 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Ads Retrieval at Walmart eCommerce with Language Models Progressively Trained on Multiple Knowledge Domains
Feb 13, 2025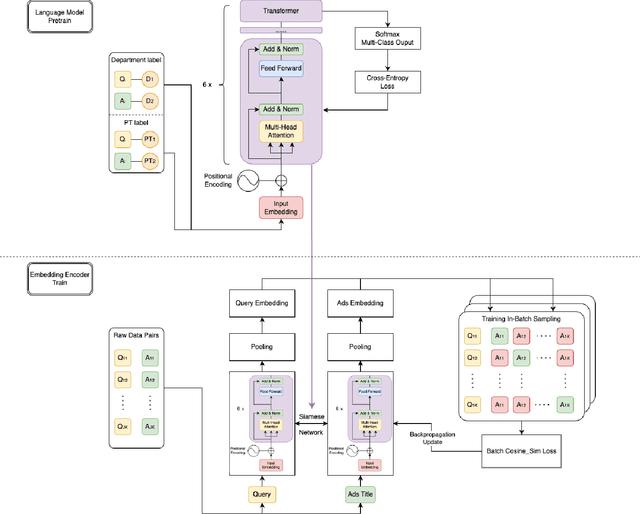
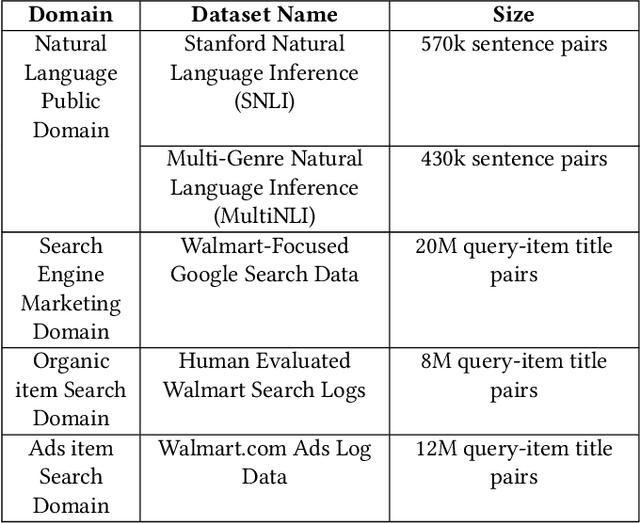
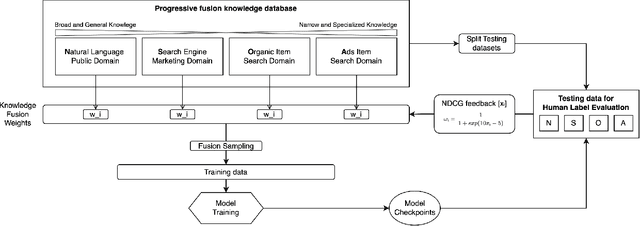
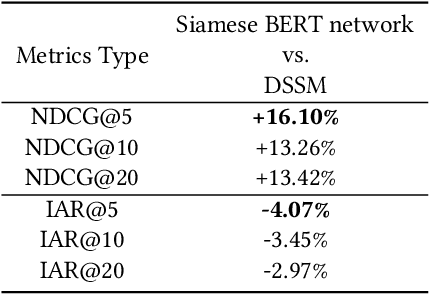
Sponsored search in e-commerce poses several unique and complex challenges. These challenges stem from factors such as the asymmetric language structure between search queries and product names, the inherent ambiguity in user search intent, and the vast volume of sparse and imbalanced search corpus data. The role of the retrieval component within a sponsored search system is pivotal, serving as the initial step that directly affects the subsequent ranking and bidding systems. In this paper, we present an end-to-end solution tailored to optimize the ads retrieval system on Walmart.com. Our approach is to pretrain the BERT-like classification model with product category information, enhancing the model's understanding of Walmart product semantics. Second, we design a two-tower Siamese Network structure for embedding structures to augment training efficiency. Third, we introduce a Human-in-the-loop Progressive Fusion Training method to ensure robust model performance. Our results demonstrate the effectiveness of this pipeline. It enhances the search relevance metric by up to 16% compared to a baseline DSSM-based model. Moreover, our large-scale online A/B testing demonstrates that our approach surpasses the ad revenue of the existing production model.
Enhanced E-Commerce Attribute Extraction: Innovating with Decorative Relation Correction and LLAMA 2.0-Based Annotation
Dec 09, 2023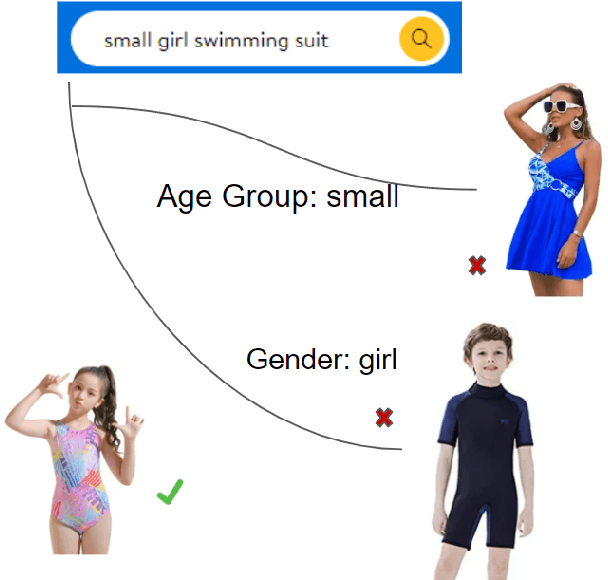
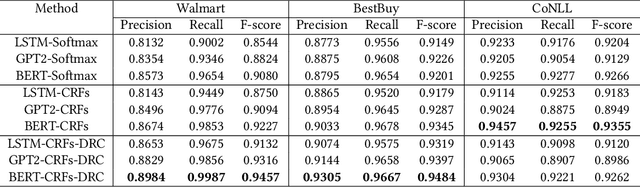
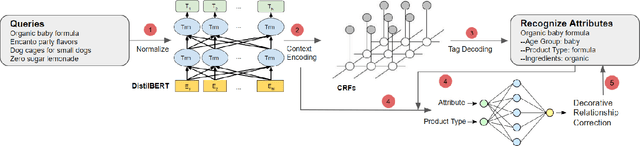
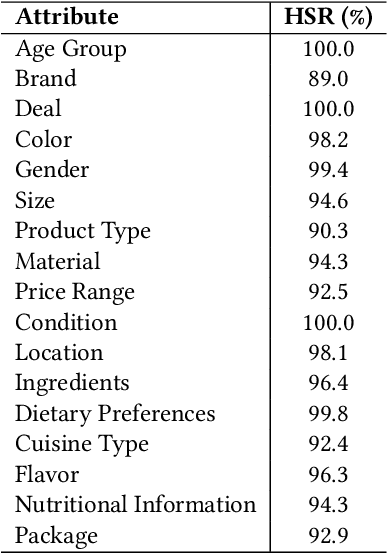
The rapid proliferation of e-commerce platforms accentuates the need for advanced search and retrieval systems to foster a superior user experience. Central to this endeavor is the precise extraction of product attributes from customer queries, enabling refined search, comparison, and other crucial e-commerce functionalities. Unlike traditional Named Entity Recognition (NER) tasks, e-commerce queries present a unique challenge owing to the intrinsic decorative relationship between product types and attributes. In this study, we propose a pioneering framework that integrates BERT for classification, a Conditional Random Fields (CRFs) layer for attribute value extraction, and Large Language Models (LLMs) for data annotation, significantly advancing attribute recognition from customer inquiries. Our approach capitalizes on the robust representation learning of BERT, synergized with the sequence decoding prowess of CRFs, to adeptly identify and extract attribute values. We introduce a novel decorative relation correction mechanism to further refine the extraction process based on the nuanced relationships between product types and attributes inherent in e-commerce data. Employing LLMs, we annotate additional data to expand the model's grasp and coverage of diverse attributes. Our methodology is rigorously validated on various datasets, including Walmart, BestBuy's e-commerce NER dataset, and the CoNLL dataset, demonstrating substantial improvements in attribute recognition performance. Particularly, the model showcased promising results during a two-month deployment in Walmart's Sponsor Product Search, underscoring its practical utility and effectiveness.
Leveraging Large Language Models for Enhanced Product Descriptions in eCommerce
Oct 24, 2023



In the dynamic field of eCommerce, the quality and comprehensiveness of product descriptions are pivotal for enhancing search visibility and customer engagement. Effective product descriptions can address the 'cold start' problem, align with market trends, and ultimately lead to increased click-through rates. Traditional methods for crafting these descriptions often involve significant human effort and may lack both consistency and scalability. This paper introduces a novel methodology for automating product description generation using the LLAMA 2.0 7B language model. We train the model on a dataset of authentic product descriptions from Walmart, one of the largest eCommerce platforms. The model is then fine-tuned for domain-specific language features and eCommerce nuances to enhance its utility in sales and user engagement. We employ multiple evaluation metrics, including NDCG, customer click-through rates, and human assessments, to validate the effectiveness of our approach. Our findings reveal that the system is not only scalable but also significantly reduces the human workload involved in creating product descriptions. This study underscores the considerable potential of large language models like LLAMA 2.0 7B in automating and optimizing various facets of eCommerce platforms, offering significant business impact, including improved search functionality and increased sales.
A Deep Reinforcement Learning Approach for Interactive Search with Sentence-level Feedback
Oct 03, 2023Interactive search can provide a better experience by incorporating interaction feedback from the users. This can significantly improve search accuracy as it helps avoid irrelevant information and captures the users' search intents. Existing state-of-the-art (SOTA) systems use reinforcement learning (RL) models to incorporate the interactions but focus on item-level feedback, ignoring the fine-grained information found in sentence-level feedback. Yet such feedback requires extensive RL action space exploration and large amounts of annotated data. This work addresses these challenges by proposing a new deep Q-learning (DQ) approach, DQrank. DQrank adapts BERT-based models, the SOTA in natural language processing, to select crucial sentences based on users' engagement and rank the items to obtain more satisfactory responses. We also propose two mechanisms to better explore optimal actions. DQrank further utilizes the experience replay mechanism in DQ to store the feedback sentences to obtain a better initial ranking performance. We validate the effectiveness of DQrank on three search datasets. The results show that DQRank performs at least 12% better than the previous SOTA RL approaches. We also conduct detailed ablation studies. The ablation results demonstrate that each model component can efficiently extract and accumulate long-term engagement effects from the users' sentence-level feedback. This structure offers new technologies with promised performance to construct a search system with sentence-level interaction.
RLIRank: Learning to Rank with Reinforcement Learning for Dynamic Search
May 21, 2021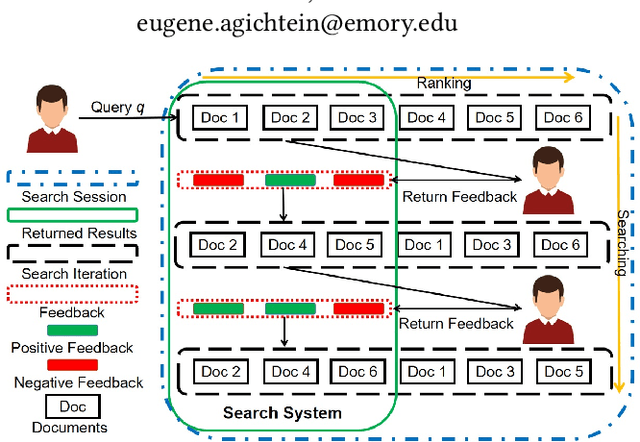
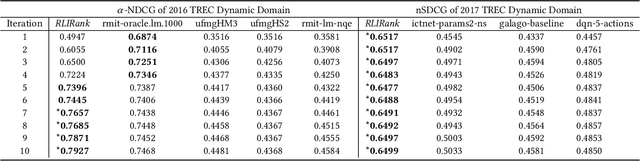
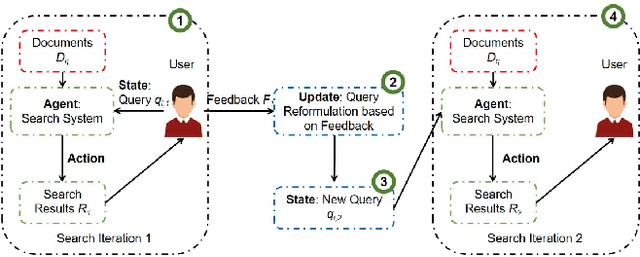

To support complex search tasks, where the initial information requirements are complex or may change during the search, a search engine must adapt the information delivery as the user's information requirements evolve. To support this dynamic ranking paradigm effectively, search result ranking must incorporate both the user feedback received, and the information displayed so far. To address this problem, we introduce a novel reinforcement learning-based approach, RLIrank. We first build an adapted reinforcement learning framework to integrate the key components of the dynamic search. Then, we implement a new Learning to Rank (LTR) model for each iteration of the dynamic search, using a recurrent Long Short Term Memory neural network (LSTM), which estimates the gain for each next result, learning from each previously ranked document. To incorporate the user's feedback, we develop a word-embedding variation of the classic Rocchio Algorithm, to help guide the ranking towards the high-value documents. Those innovations enable RLIrank to outperform the previously reported methods from the TREC Dynamic Domain Tracks 2017 and exceed all the methods in 2016 TREC Dynamic Domain after multiple search iterations, advancing the state of the art for dynamic search.
* Proceedings of The Web Conference 2020 (WWW '20), April 20--24, 2020, Taipei, Taiwan
Diversifying Multi-aspect Search Results Using Simpson's Diversity Index
May 21, 2021
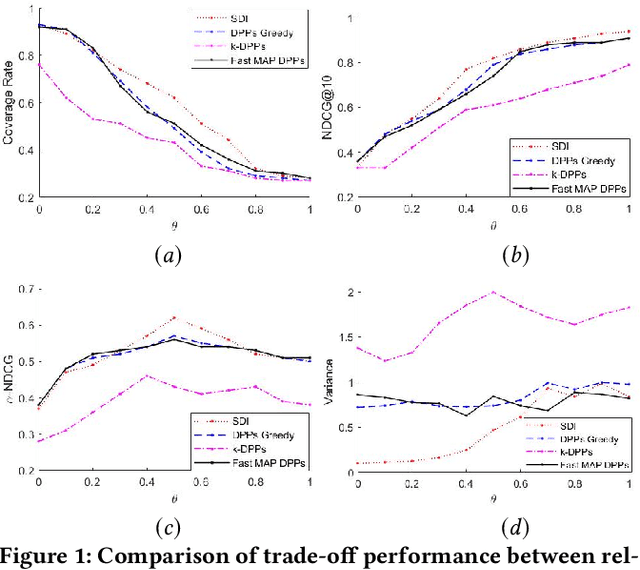
In search and recommendation, diversifying the multi-aspect search results could help with reducing redundancy, and promoting results that might not be shown otherwise. Many previous methods have been proposed for this task. However, previous methods do not explicitly consider the uniformity of the number of the items' classes, or evenness, which could degrade the search and recommendation quality. To address this problem, we introduce a novel method by adapting the Simpson's Diversity Index from biology, which enables a more effective and efficient quadratic search result diversification algorithm. We also extend the method to balance the diversity between multiple aspects through weighted factors and further improve computational complexity by developing a fast approximation algorithm. We demonstrate the feasibility of the proposed method using the openly available Kaggle shoes competition dataset. Our experimental results show that our approach outperforms previous state of the art diversification methods, while reducing computational complexity.
* Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM '20), October 19--23, 2020, Virtual Event, Ireland}
De-Biased Modelling of Search Click Behavior with Reinforcement Learning
May 21, 2021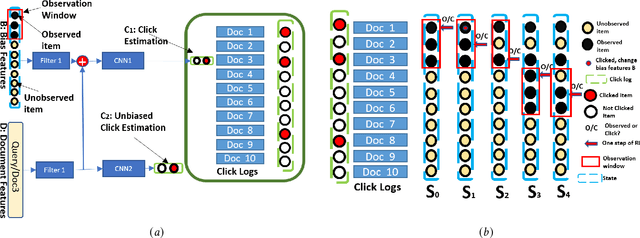

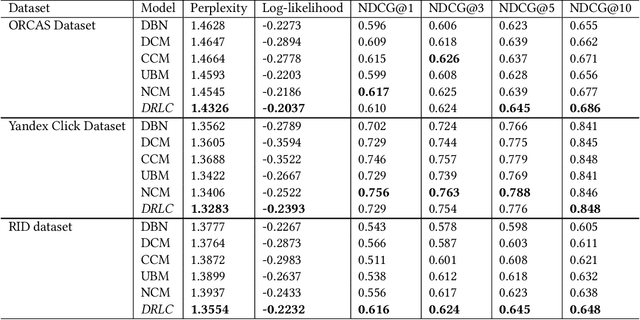
Users' clicks on Web search results are one of the key signals for evaluating and improving web search quality and have been widely used as part of current state-of-the-art Learning-To-Rank(LTR) models. With a large volume of search logs available for major search engines, effective models of searcher click behavior have emerged to evaluate and train LTR models. However, when modeling the users' click behavior, considering the bias of the behavior is imperative. In particular, when a search result is not clicked, it is not necessarily chosen as not relevant by the user, but instead could have been simply missed, especially for lower-ranked results. These kinds of biases in the click log data can be incorporated into the click models, propagating the errors to the resulting LTR ranking models or evaluation metrics. In this paper, we propose the De-biased Reinforcement Learning Click model (DRLC). The DRLC model relaxes previously made assumptions about the users' examination behavior and resulting latent states. To implement the DRLC model, convolutional neural networks are used as the value networks for reinforcement learning, trained to learn a policy to reduce bias in the click logs. To demonstrate the effectiveness of the DRLC model, we first compare performance with the previous state-of-art approaches using established click prediction metrics, including log-likelihood and perplexity. We further show that DRLC also leads to improvements in ranking performance. Our experiments demonstrate the effectiveness of the DRLC model in learning to reduce bias in click logs, leading to improved modeling performance and showing the potential for using DRLC for improving Web search quality.