 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Supervision for Walmart's Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Apr 10, 2026Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
Unified Supervision for Walmarts Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Apr 09, 2026Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
Semantic Ads Retrieval at Walmart eCommerce with Language Models Progressively Trained on Multiple Knowledge Domains
Feb 13, 2025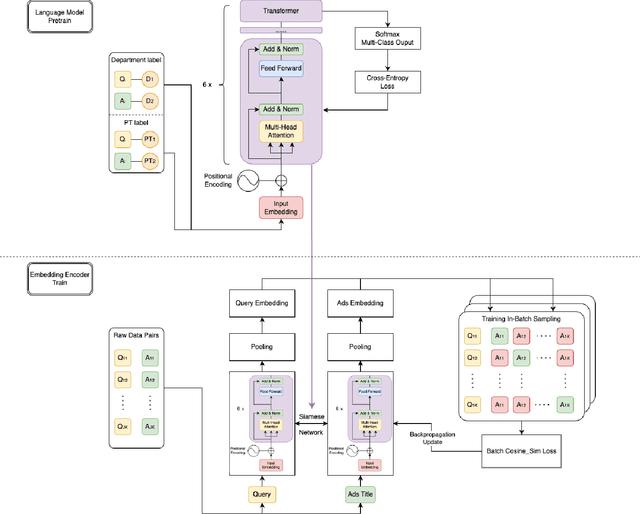
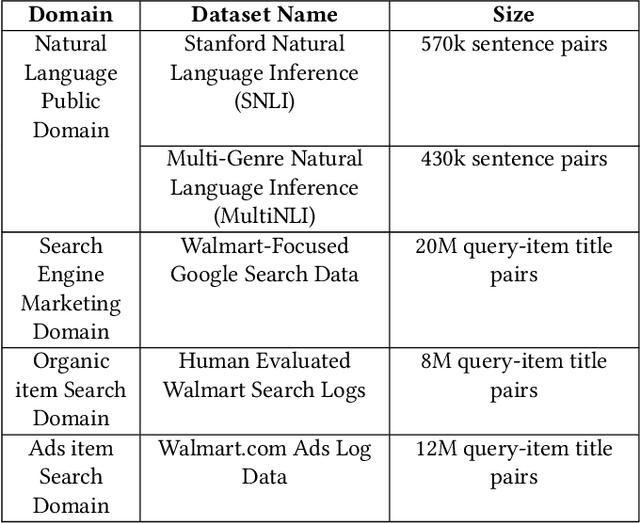
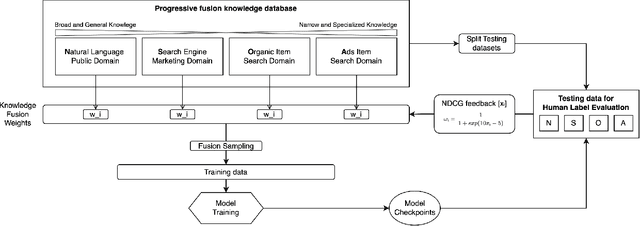
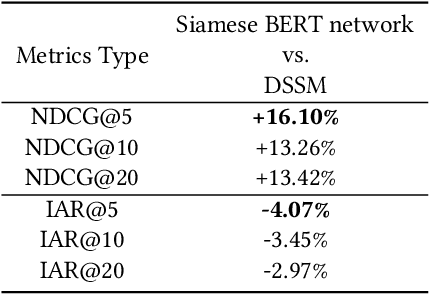
Sponsored search in e-commerce poses several unique and complex challenges. These challenges stem from factors such as the asymmetric language structure between search queries and product names, the inherent ambiguity in user search intent, and the vast volume of sparse and imbalanced search corpus data. The role of the retrieval component within a sponsored search system is pivotal, serving as the initial step that directly affects the subsequent ranking and bidding systems. In this paper, we present an end-to-end solution tailored to optimize the ads retrieval system on Walmart.com. Our approach is to pretrain the BERT-like classification model with product category information, enhancing the model's understanding of Walmart product semantics. Second, we design a two-tower Siamese Network structure for embedding structures to augment training efficiency. Third, we introduce a Human-in-the-loop Progressive Fusion Training method to ensure robust model performance. Our results demonstrate the effectiveness of this pipeline. It enhances the search relevance metric by up to 16% compared to a baseline DSSM-based model. Moreover, our large-scale online A/B testing demonstrates that our approach surpasses the ad revenue of the existing production model.
Enhanced E-Commerce Attribute Extraction: Innovating with Decorative Relation Correction and LLAMA 2.0-Based Annotation
Dec 09, 2023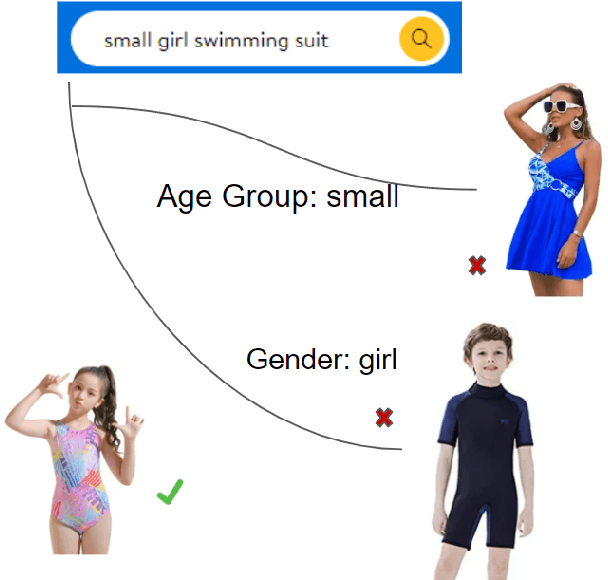
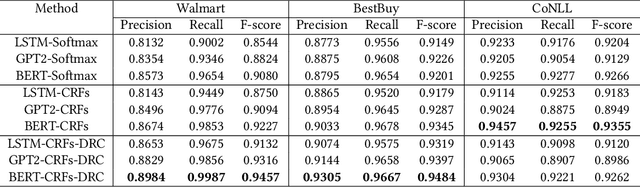
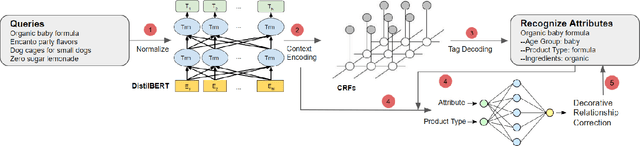
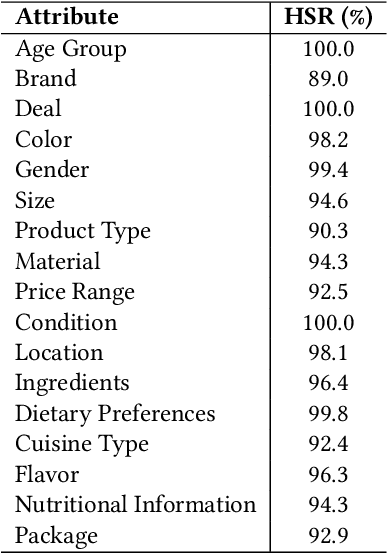
The rapid proliferation of e-commerce platforms accentuates the need for advanced search and retrieval systems to foster a superior user experience. Central to this endeavor is the precise extraction of product attributes from customer queries, enabling refined search, comparison, and other crucial e-commerce functionalities. Unlike traditional Named Entity Recognition (NER) tasks, e-commerce queries present a unique challenge owing to the intrinsic decorative relationship between product types and attributes. In this study, we propose a pioneering framework that integrates BERT for classification, a Conditional Random Fields (CRFs) layer for attribute value extraction, and Large Language Models (LLMs) for data annotation, significantly advancing attribute recognition from customer inquiries. Our approach capitalizes on the robust representation learning of BERT, synergized with the sequence decoding prowess of CRFs, to adeptly identify and extract attribute values. We introduce a novel decorative relation correction mechanism to further refine the extraction process based on the nuanced relationships between product types and attributes inherent in e-commerce data. Employing LLMs, we annotate additional data to expand the model's grasp and coverage of diverse attributes. Our methodology is rigorously validated on various datasets, including Walmart, BestBuy's e-commerce NER dataset, and the CoNLL dataset, demonstrating substantial improvements in attribute recognition performance. Particularly, the model showcased promising results during a two-month deployment in Walmart's Sponsor Product Search, underscoring its practical utility and effectiveness.
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity
Jul 11, 2021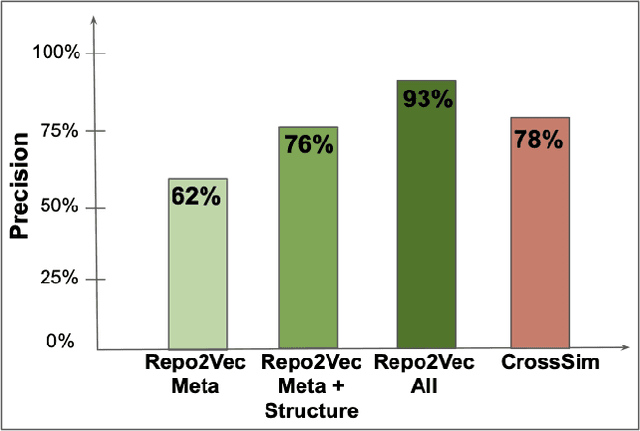
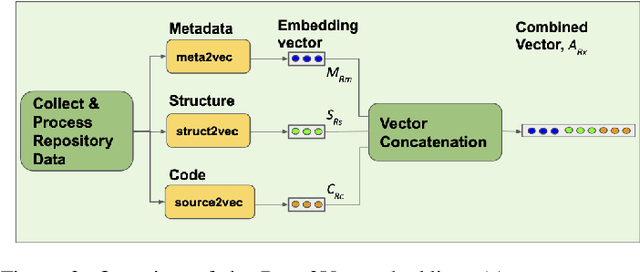
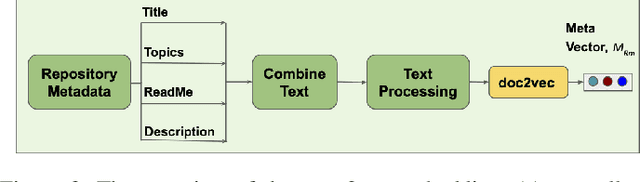
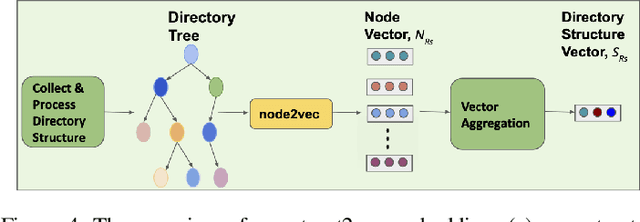
How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determiningrepository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by MLalgorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a)metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93%vs 78%), with nearly twice as many Strongly Similar repositories and 30% fewer False Positives. Second, we show how Repo2Vecprovides a solid basis for: (a) distinguishing between malware and benign repositories, and (b) identifying a meaningful hierarchical clustering. For example, we achieve 98% precision and 96%recall in distinguishing malware and benign repositories. Overall, our work is a fundamental building block for enabling many repository analysis functions such as repository categorization by target platform or intention, detecting code-reuse and clones, and identifying lineage and evolution.