 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity
Jul 11, 2021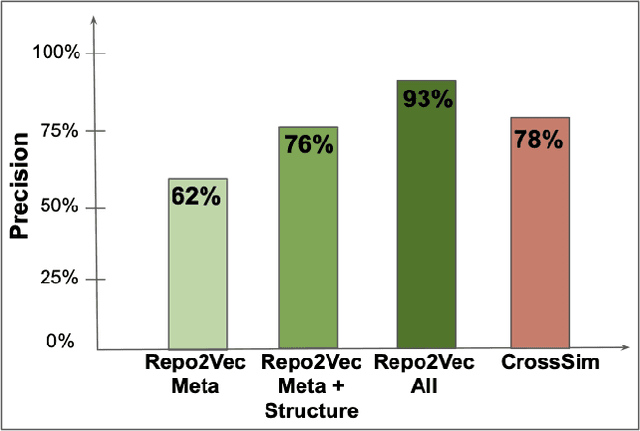
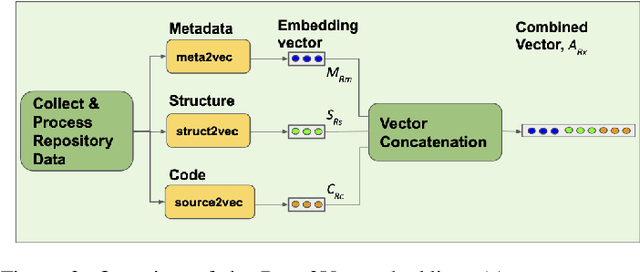
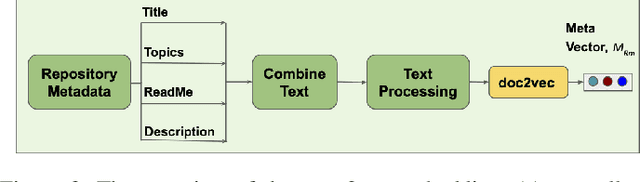
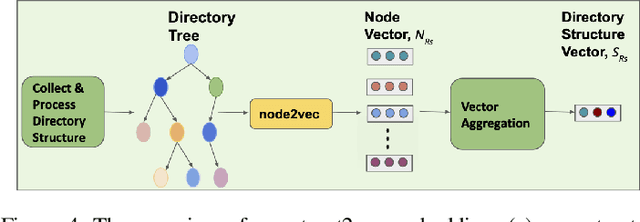
How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determiningrepository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by MLalgorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a)metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93%vs 78%), with nearly twice as many Strongly Similar repositories and 30% fewer False Positives. Second, we show how Repo2Vecprovides a solid basis for: (a) distinguishing between malware and benign repositories, and (b) identifying a meaningful hierarchical clustering. For example, we achieve 98% precision and 96%recall in distinguishing malware and benign repositories. Overall, our work is a fundamental building block for enabling many repository analysis functions such as repository categorization by target platform or intention, detecting code-reuse and clones, and identifying lineage and evolution.
Mobility Map Inference from Thermal Modeling of a Building
Nov 14, 2020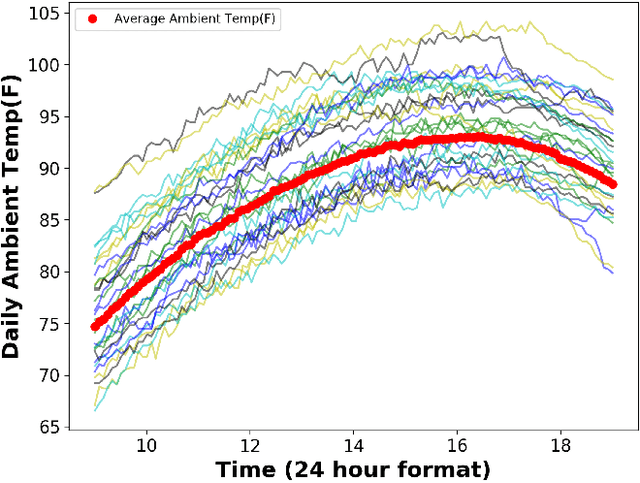
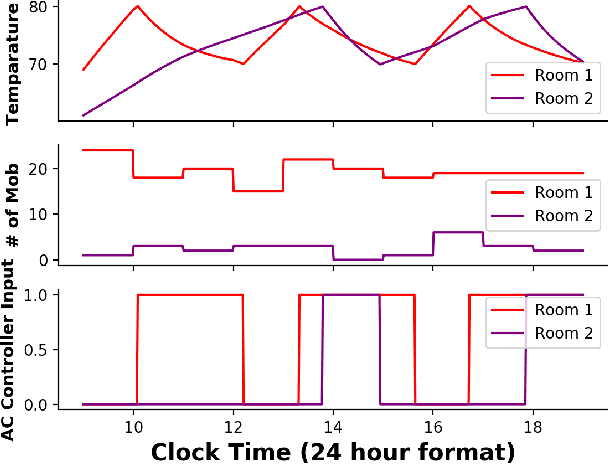
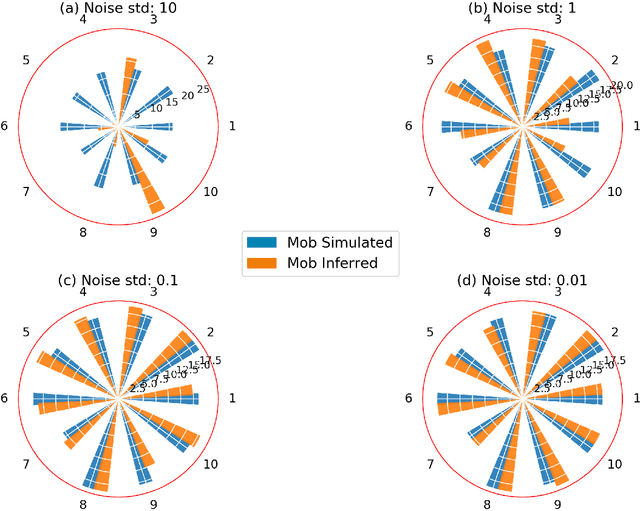
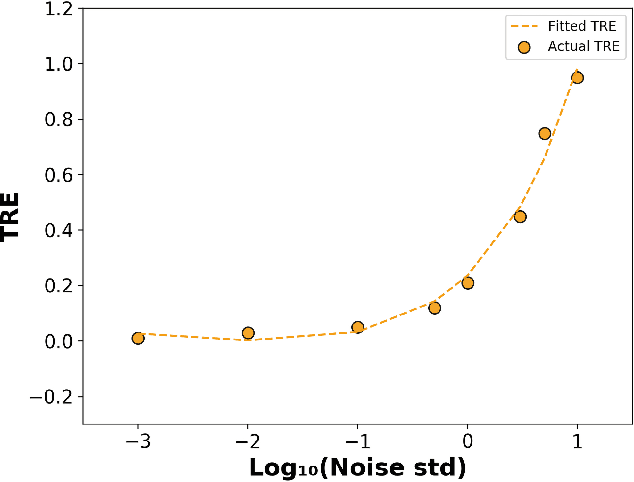
We consider the problem of inferring the mobility map, which is the distribution of the building occupants at each timestamp, from the temperatures of the rooms. We also want to explore the effects of noise in the temperature measurement, room layout, etc. in the reconstruction of the movement of people within the building. Our proposed algorithm tackles down the aforementioned challenges leveraging a parameter learner, the modified Least Square Estimator. In the absence of a complete data set with mobility map, room and ambient temperatures, and HVAC data in the public domain, we simulate a physics-based thermal model of the rooms in a building and evaluate the performance of our inference algorithm on this simulated data. We find an upper bound of the noise standard deviation (<= 1F) in the input temperature data of our model. Within this bound, our algorithm can reconstruct the mobility map with a reasonable reconstruction error. Our work can be used in a wide range of applications, for example, ensuring the physical security of office buildings, elderly and infant monitoring, building resources management, emergency building evacuation, and vulnerability assessment of HVAC data. Our work brings together multiple research areas, Thermal Modeling and Parameter Estimation, towards achieving a common goal of inferring the distribution of people within a large office building.