 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWIBA: What Is Being Argued? A Comprehensive Approach to Argument Mining
May 01, 2024

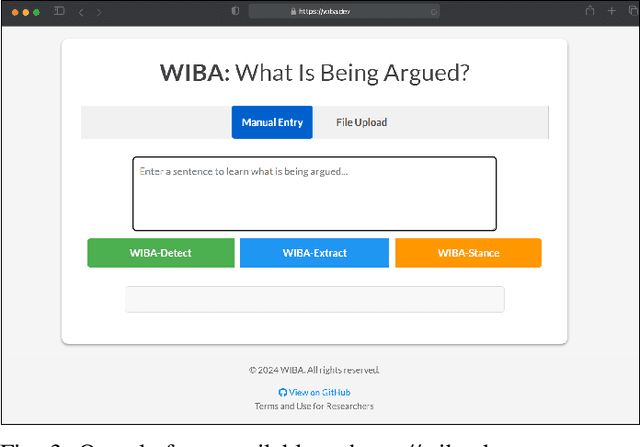

We propose WIBA, a novel framework and suite of methods that enable the comprehensive understanding of "What Is Being Argued" across contexts. Our approach develops a comprehensive framework that detects: (a) the existence, (b) the topic, and (c) the stance of an argument, correctly accounting for the logical dependence among the three tasks. Our algorithm leverages the fine-tuning and prompt-engineering of Large Language Models. We evaluate our approach and show that it performs well in all the three capabilities. First, we develop and release an Argument Detection model that can classify a piece of text as an argument with an F1 score between 79% and 86% on three different benchmark datasets. Second, we release a language model that can identify the topic being argued in a sentence, be it implicit or explicit, with an average similarity score of 71%, outperforming current naive methods by nearly 40%. Finally, we develop a method for Argument Stance Classification, and evaluate the capability of our approach, showing it achieves a classification F1 score between 71% and 78% across three diverse benchmark datasets. Our evaluation demonstrates that WIBA allows the comprehensive understanding of What Is Being Argued in large corpora across diverse contexts, which is of core interest to many applications in linguistics, communication, and social and computer science. To facilitate accessibility to the advancements outlined in this work, we release WIBA as a free open access platform (wiba.dev).
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity
Jul 11, 2021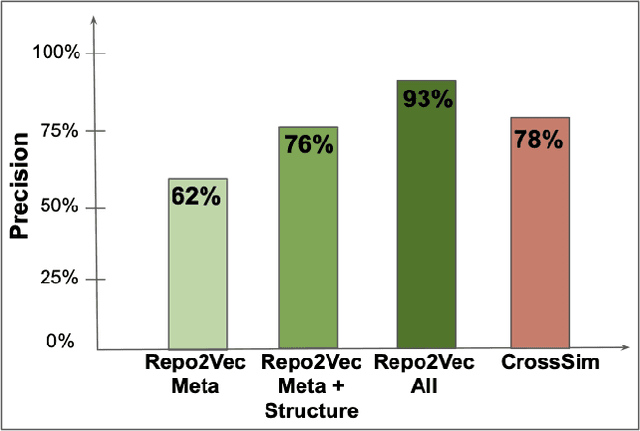
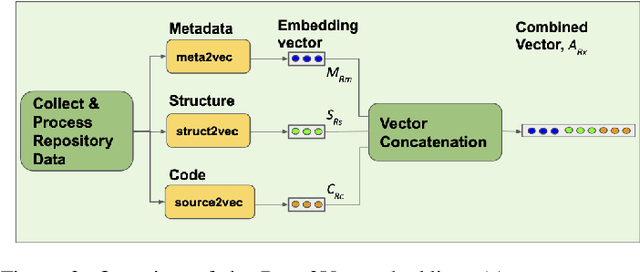
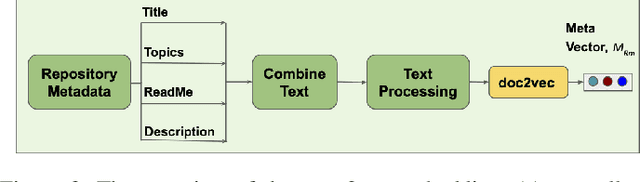
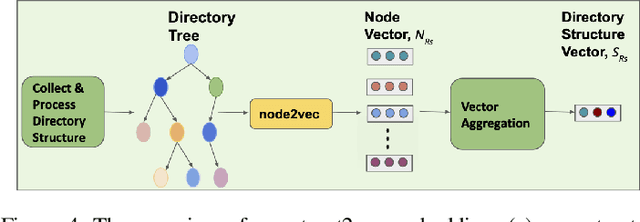
How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determiningrepository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by MLalgorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a)metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93%vs 78%), with nearly twice as many Strongly Similar repositories and 30% fewer False Positives. Second, we show how Repo2Vecprovides a solid basis for: (a) distinguishing between malware and benign repositories, and (b) identifying a meaningful hierarchical clustering. For example, we achieve 98% precision and 96%recall in distinguishing malware and benign repositories. Overall, our work is a fundamental building block for enabling many repository analysis functions such as repository categorization by target platform or intention, detecting code-reuse and clones, and identifying lineage and evolution.
Mobility Map Inference from Thermal Modeling of a Building
Nov 14, 2020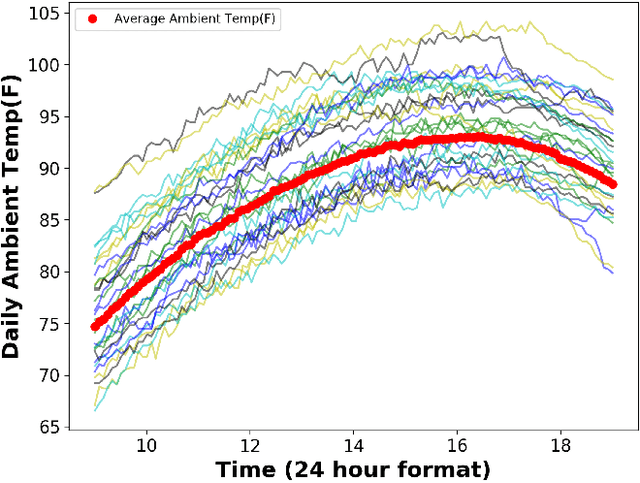
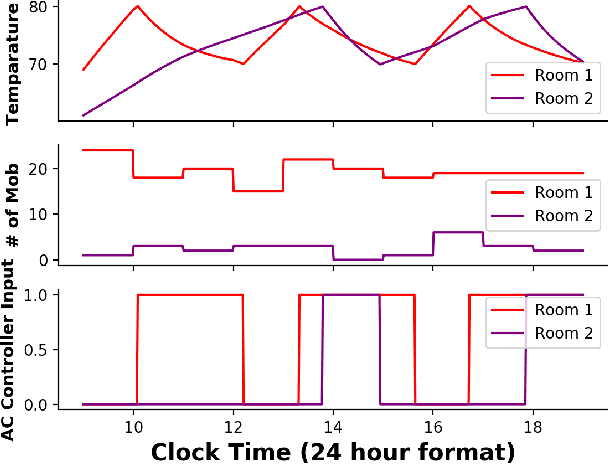
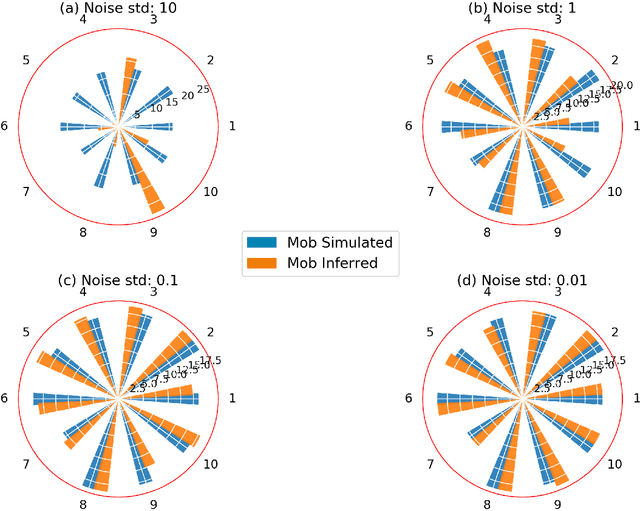
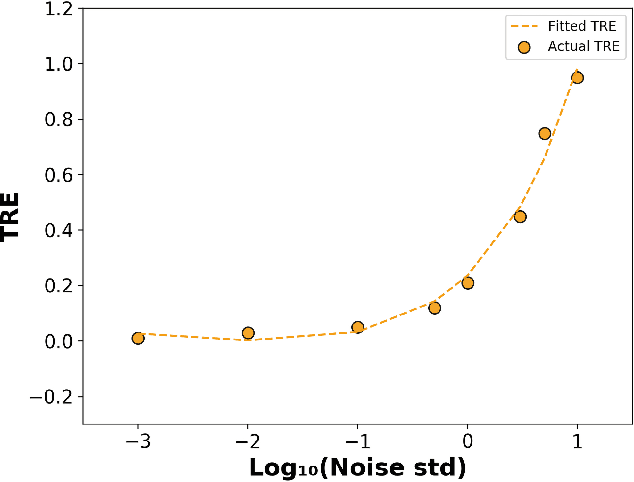
We consider the problem of inferring the mobility map, which is the distribution of the building occupants at each timestamp, from the temperatures of the rooms. We also want to explore the effects of noise in the temperature measurement, room layout, etc. in the reconstruction of the movement of people within the building. Our proposed algorithm tackles down the aforementioned challenges leveraging a parameter learner, the modified Least Square Estimator. In the absence of a complete data set with mobility map, room and ambient temperatures, and HVAC data in the public domain, we simulate a physics-based thermal model of the rooms in a building and evaluate the performance of our inference algorithm on this simulated data. We find an upper bound of the noise standard deviation (<= 1F) in the input temperature data of our model. Within this bound, our algorithm can reconstruct the mobility map with a reasonable reconstruction error. Our work can be used in a wide range of applications, for example, ensuring the physical security of office buildings, elderly and infant monitoring, building resources management, emergency building evacuation, and vulnerability assessment of HVAC data. Our work brings together multiple research areas, Thermal Modeling and Parameter Estimation, towards achieving a common goal of inferring the distribution of people within a large office building.
REST: A thread embedding approach for identifying and classifying user-specified information in security forums
Jan 08, 2020



How can we extract useful information from a security forum? We focus on identifying threads of interest to a security professional: (a) alerts of worrisome events, such as attacks, (b) offering of malicious services and products, (c) hacking information to perform malicious acts, and (d) useful security-related experiences. The analysis of security forums is in its infancy despite several promising recent works. Novel approaches are needed to address the challenges in this domain: (a) the difficulty in specifying the "topics" of interest efficiently, and (b) the unstructured and informal nature of the text. We propose, REST, a systematic methodology to: (a) identify threads of interest based on a, possibly incomplete, bag of words, and (b) classify them into one of the four classes above. The key novelty of the work is a multi-step weighted embedding approach: we project words, threads and classes in appropriate embedding spaces and establish relevance and similarity there. We evaluate our method with real data from three security forums with a total of 164k posts and 21K threads. First, REST robustness to initial keyword selection can extend the user-provided keyword set and thus, it can recover from missing keywords. Second, REST categorizes the threads into the classes of interest with superior accuracy compared to five other methods: REST exhibits an accuracy between 63.3-76.9%. We see our approach as a first step for harnessing the wealth of information of online forums in a user-friendly way, since the user can loosely specify her keywords of interest.
RIPEx: Extracting malicious IP addresses from security forums using cross-forum learning
Apr 13, 2018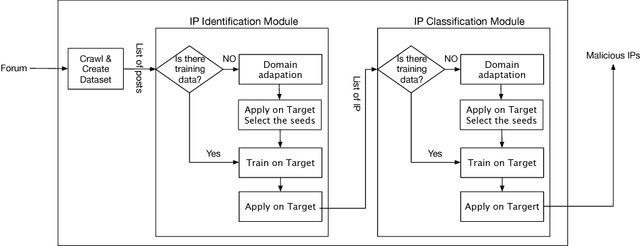



Is it possible to extract malicious IP addresses reported in security forums in an automatic way? This is the question at the heart of our work. We focus on security forums, where security professionals and hackers share knowledge and information, and often report misbehaving IP addresses. So far, there have only been a few efforts to extract information from such security forums. We propose RIPEx, a systematic approach to identify and label IP addresses in security forums by utilizing a cross-forum learning method. In more detail, the challenge is twofold: (a) identifying IP addresses from other numerical entities, such as software version numbers, and (b) classifying the IP address as benign or malicious. We propose an integrated solution that tackles both these problems. A novelty of our approach is that it does not require training data for each new forum. Our approach does knowledge transfer across forums: we use a classifier from our source forums to identify seed information for training a classifier on the target forum. We evaluate our method using data collected from five security forums with a total of 31K users and 542K posts. First, RIPEx can distinguish IP address from other numeric expressions with 95% precision and above 93% recall on average. Second, RIPEx identifies malicious IP addresses with an average precision of 88% and over 78% recall, using our cross-forum learning. Our work is a first step towards harnessing the wealth of useful information that can be found in security forums.
PhishDef: URL Names Say It All
Sep 12, 2010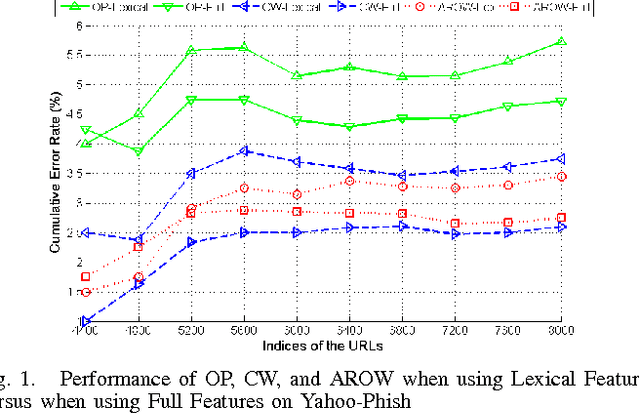
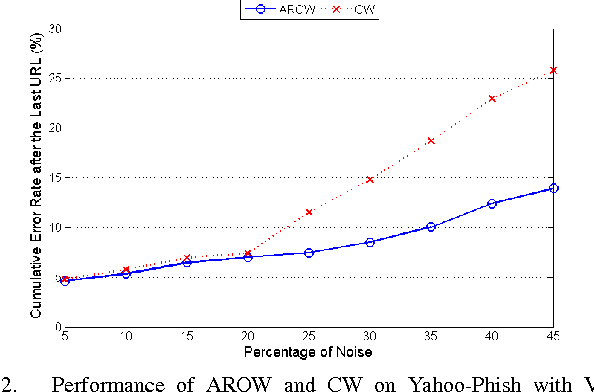


Phishing is an increasingly sophisticated method to steal personal user information using sites that pretend to be legitimate. In this paper, we take the following steps to identify phishing URLs. First, we carefully select lexical features of the URLs that are resistant to obfuscation techniques used by attackers. Second, we evaluate the classification accuracy when using only lexical features, both automatically and hand-selected, vs. when using additional features. We show that lexical features are sufficient for all practical purposes. Third, we thoroughly compare several classification algorithms, and we propose to use an online method (AROW) that is able to overcome noisy training data. Based on the insights gained from our analysis, we propose PhishDef, a phishing detection system that uses only URL names and combines the above three elements. PhishDef is a highly accurate method (when compared to state-of-the-art approaches over real datasets), lightweight (thus appropriate for online and client-side deployment), proactive (based on online classification rather than blacklists), and resilient to training data inaccuracies (thus enabling the use of large noisy training data).