 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Supervision for Walmart's Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Apr 10, 2026Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
Unified Supervision for Walmarts Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Apr 09, 2026Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
Semantic Ads Retrieval at Walmart eCommerce with Language Models Progressively Trained on Multiple Knowledge Domains
Feb 13, 2025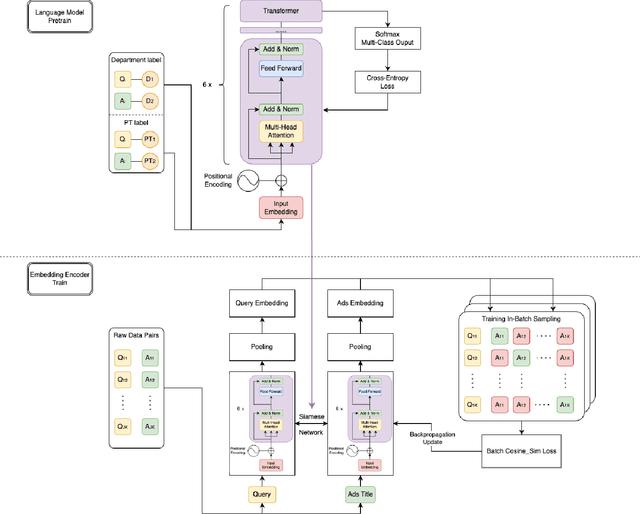
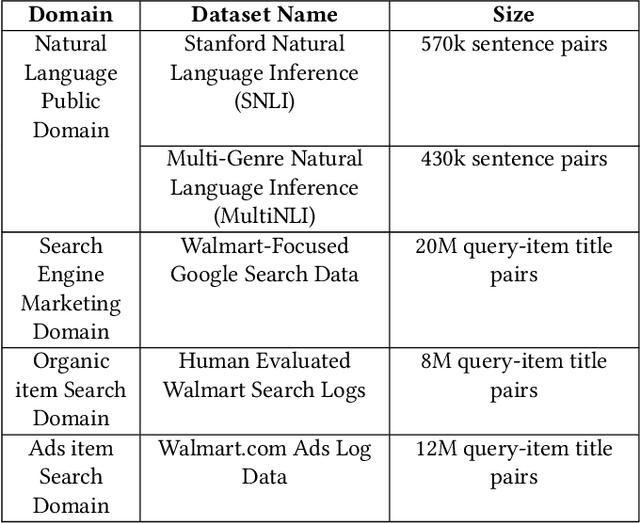
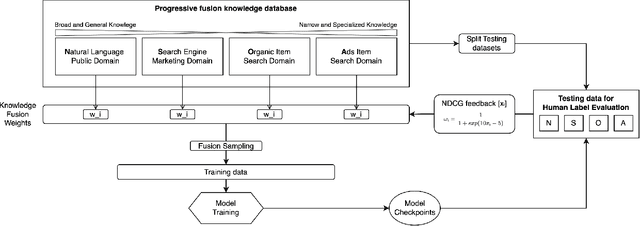
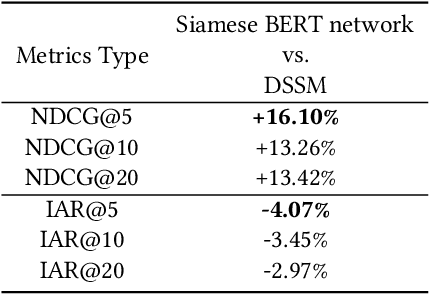
Sponsored search in e-commerce poses several unique and complex challenges. These challenges stem from factors such as the asymmetric language structure between search queries and product names, the inherent ambiguity in user search intent, and the vast volume of sparse and imbalanced search corpus data. The role of the retrieval component within a sponsored search system is pivotal, serving as the initial step that directly affects the subsequent ranking and bidding systems. In this paper, we present an end-to-end solution tailored to optimize the ads retrieval system on Walmart.com. Our approach is to pretrain the BERT-like classification model with product category information, enhancing the model's understanding of Walmart product semantics. Second, we design a two-tower Siamese Network structure for embedding structures to augment training efficiency. Third, we introduce a Human-in-the-loop Progressive Fusion Training method to ensure robust model performance. Our results demonstrate the effectiveness of this pipeline. It enhances the search relevance metric by up to 16% compared to a baseline DSSM-based model. Moreover, our large-scale online A/B testing demonstrates that our approach surpasses the ad revenue of the existing production model.
A Comprehensive Forecasting Framework based on Multi-Stage Hierarchical Forecasting Reconciliation and Adjustment
Dec 19, 2024
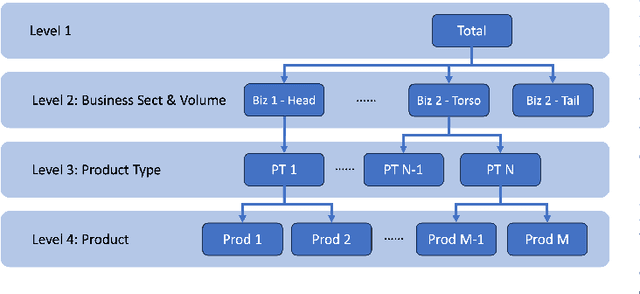


Ads demand forecasting for Walmart's ad products plays a critical role in enabling effective resource planning, allocation, and management of ads performance. In this paper, we introduce a comprehensive demand forecasting system that tackles hierarchical time series forecasting in business settings. Though traditional hierarchical reconciliation methods ensure forecasting coherence, they often trade off accuracy for coherence especially at lower levels and fail to capture the seasonality unique to each time-series in the hierarchy. Thus, we propose a novel framework "Multi-Stage Hierarchical Forecasting Reconciliation and Adjustment (Multi-Stage HiFoReAd)" to address the challenges of preserving seasonality, ensuring coherence, and improving accuracy. Our system first utilizes diverse models, ensembled through Bayesian Optimization (BO), achieving base forecasts. The generated base forecasts are then passed into the Multi-Stage HiFoReAd framework. The initial stage refines the hierarchy using Top-Down forecasts and "harmonic alignment." The second stage aligns the higher levels' forecasts using MinTrace algorithm, following which the last two levels undergo "harmonic alignment" and "stratified scaling", to eventually achieve accurate and coherent forecasts across the whole hierarchy. Our experiments on Walmart's internal Ads-demand dataset and 3 other public datasets, each with 4 hierarchical levels, demonstrate that the average Absolute Percentage Error from the cross-validation sets improve from 3% to 40% across levels against BO-ensemble of models (LGBM, MSTL+ETS, Prophet) as well as from 1.2% to 92.9% against State-Of-The-Art models. In addition, the forecasts at all hierarchical levels are proved to be coherent. The proposed framework has been deployed and leveraged by Walmart's ads, sales and operations teams to track future demands, make informed decisions and plan resources.
Enhanced E-Commerce Attribute Extraction: Innovating with Decorative Relation Correction and LLAMA 2.0-Based Annotation
Dec 09, 2023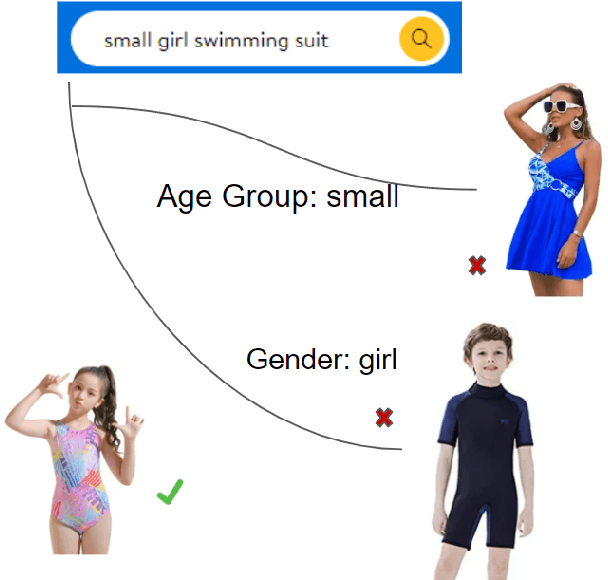
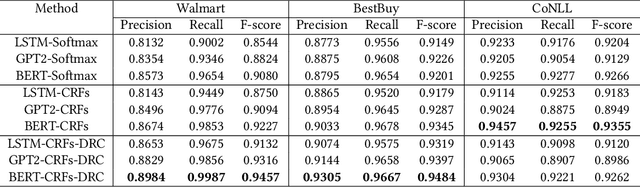
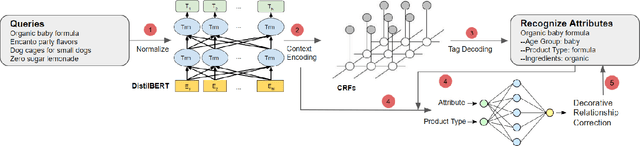
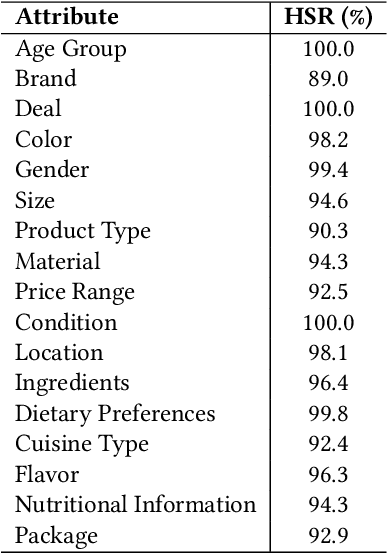
The rapid proliferation of e-commerce platforms accentuates the need for advanced search and retrieval systems to foster a superior user experience. Central to this endeavor is the precise extraction of product attributes from customer queries, enabling refined search, comparison, and other crucial e-commerce functionalities. Unlike traditional Named Entity Recognition (NER) tasks, e-commerce queries present a unique challenge owing to the intrinsic decorative relationship between product types and attributes. In this study, we propose a pioneering framework that integrates BERT for classification, a Conditional Random Fields (CRFs) layer for attribute value extraction, and Large Language Models (LLMs) for data annotation, significantly advancing attribute recognition from customer inquiries. Our approach capitalizes on the robust representation learning of BERT, synergized with the sequence decoding prowess of CRFs, to adeptly identify and extract attribute values. We introduce a novel decorative relation correction mechanism to further refine the extraction process based on the nuanced relationships between product types and attributes inherent in e-commerce data. Employing LLMs, we annotate additional data to expand the model's grasp and coverage of diverse attributes. Our methodology is rigorously validated on various datasets, including Walmart, BestBuy's e-commerce NER dataset, and the CoNLL dataset, demonstrating substantial improvements in attribute recognition performance. Particularly, the model showcased promising results during a two-month deployment in Walmart's Sponsor Product Search, underscoring its practical utility and effectiveness.
Leveraging Large Language Models for Enhanced Product Descriptions in eCommerce
Oct 24, 2023



In the dynamic field of eCommerce, the quality and comprehensiveness of product descriptions are pivotal for enhancing search visibility and customer engagement. Effective product descriptions can address the 'cold start' problem, align with market trends, and ultimately lead to increased click-through rates. Traditional methods for crafting these descriptions often involve significant human effort and may lack both consistency and scalability. This paper introduces a novel methodology for automating product description generation using the LLAMA 2.0 7B language model. We train the model on a dataset of authentic product descriptions from Walmart, one of the largest eCommerce platforms. The model is then fine-tuned for domain-specific language features and eCommerce nuances to enhance its utility in sales and user engagement. We employ multiple evaluation metrics, including NDCG, customer click-through rates, and human assessments, to validate the effectiveness of our approach. Our findings reveal that the system is not only scalable but also significantly reduces the human workload involved in creating product descriptions. This study underscores the considerable potential of large language models like LLAMA 2.0 7B in automating and optimizing various facets of eCommerce platforms, offering significant business impact, including improved search functionality and increased sales.
Distributed Flexible Nonlinear Tensor Factorization
May 22, 2016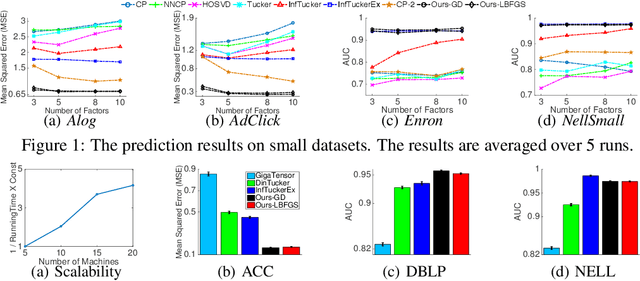
Tensor factorization is a powerful tool to analyse multi-way data. Compared with traditional multi-linear methods, nonlinear tensor factorization models are capable of capturing more complex relationships in the data. However, they are computationally expensive and may suffer severe learning bias in case of extreme data sparsity. To overcome these limitations, in this paper we propose a distributed, flexible nonlinear tensor factorization model. Our model can effectively avoid the expensive computations and structural restrictions of the Kronecker-product in existing TGP formulations, allowing an arbitrary subset of tensorial entries to be selected to contribute to the training. At the same time, we derive a tractable and tight variational evidence lower bound (ELBO) that enables highly decoupled, parallel computations and high-quality inference. Based on the new bound, we develop a distributed inference algorithm in the MapReduce framework, which is key-value-free and can fully exploit the memory cache mechanism in fast MapReduce systems such as SPARK. Experimental results fully demonstrate the advantages of our method over several state-of-the-art approaches, in terms of both predictive performance and computational efficiency. Moreover, our approach shows a promising potential in the application of Click-Through-Rate (CTR) prediction for online advertising.
Lift-Based Bidding in Ad Selection
Feb 13, 2016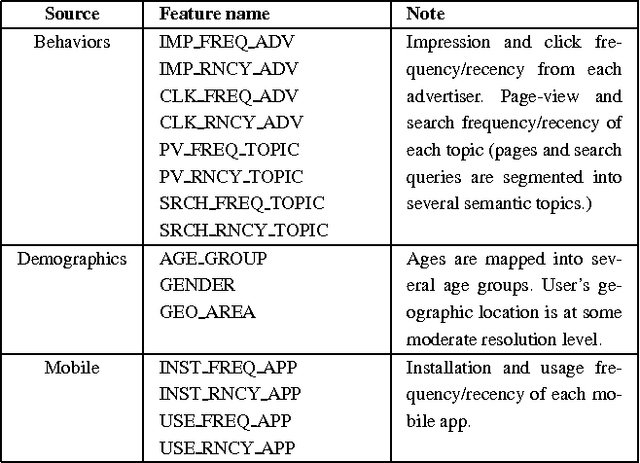
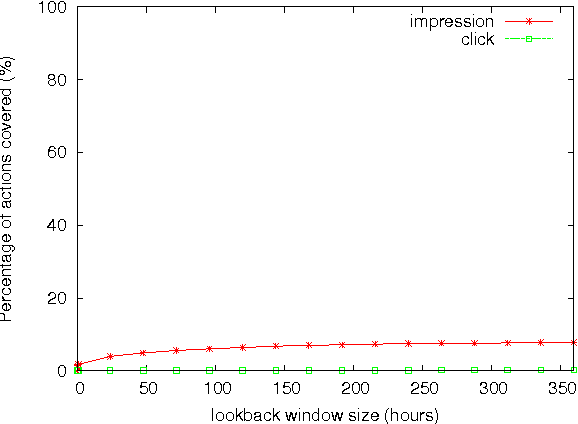
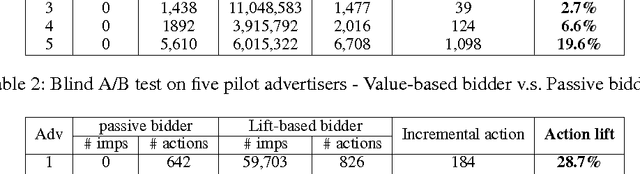
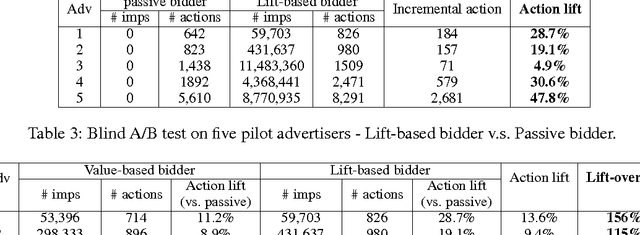
Real-time bidding (RTB) has become one of the largest online advertising markets in the world. Today the bid price per ad impression is typically decided by the expected value of how it can lead to a desired action event (e.g., registering an account or placing a purchase order) to the advertiser. However, this industry standard approach to decide the bid price does not consider the actual effect of the ad shown to the user, which should be measured based on the performance lift among users who have been or have not been exposed to a certain treatment of ads. In this paper, we propose a new bidding strategy and prove that if the bid price is decided based on the performance lift rather than absolute performance value, advertisers can actually gain more action events. We describe the modeling methodology to predict the performance lift and demonstrate the actual performance gain through blind A/B test with real ad campaigns in an industry-leading Demand-Side Platform (DSP). We also discuss the relationship between attribution models and bidding strategies. We prove that, to move the DSPs to bid based on performance lift, they should be rewarded according to the relative performance lift they contribute.
Smart Pacing for Effective Online Ad Campaign Optimization
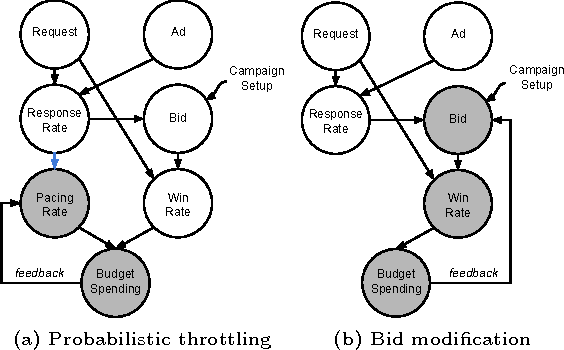
Jun 18, 2015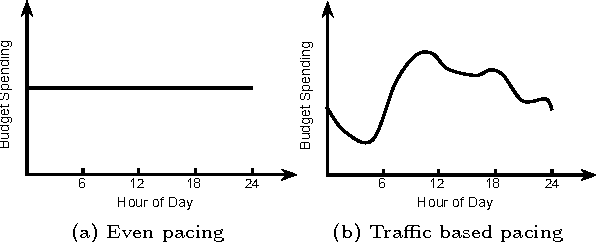

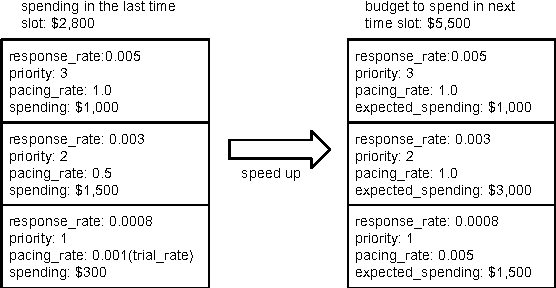
In targeted online advertising, advertisers look for maximizing campaign performance under delivery constraint within budget schedule. Most of the advertisers typically prefer to impose the delivery constraint to spend budget smoothly over the time in order to reach a wider range of audiences and have a sustainable impact. Since lots of impressions are traded through public auctions for online advertising today, the liquidity makes price elasticity and bid landscape between demand and supply change quite dynamically. Therefore, it is challenging to perform smooth pacing control and maximize campaign performance simultaneously. In this paper, we propose a smart pacing approach in which the delivery pace of each campaign is learned from both offline and online data to achieve smooth delivery and optimal performance goals. The implementation of the proposed approach in a real DSP system is also presented. Experimental evaluations on both real online ad campaigns and offline simulations show that our approach can effectively improve campaign performance and achieve delivery goals.