 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Ads Retrieval at Walmart eCommerce with Language Models Progressively Trained on Multiple Knowledge Domains
Feb 13, 2025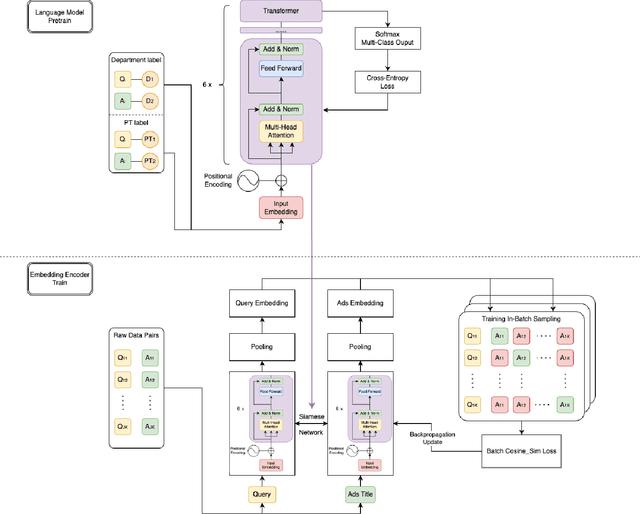
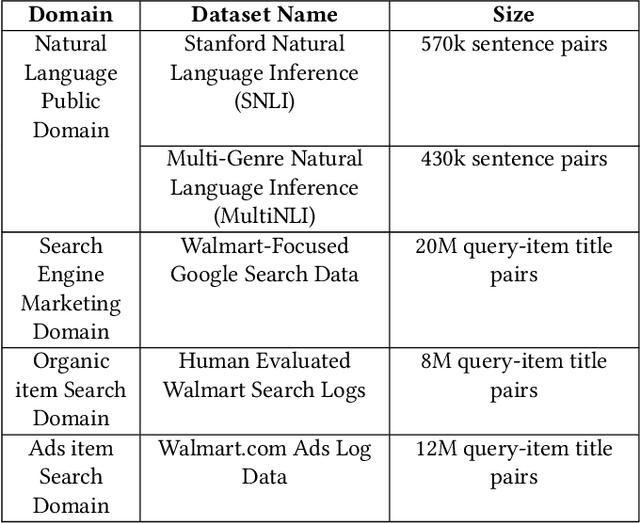
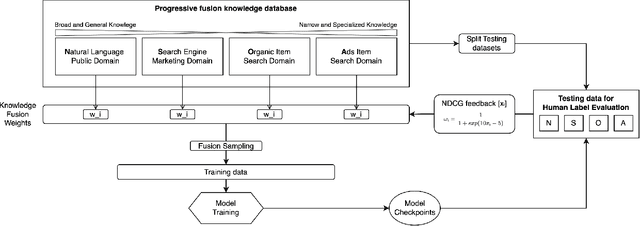
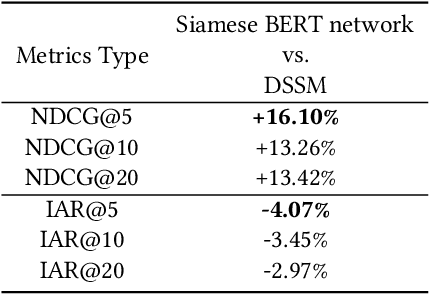
Sponsored search in e-commerce poses several unique and complex challenges. These challenges stem from factors such as the asymmetric language structure between search queries and product names, the inherent ambiguity in user search intent, and the vast volume of sparse and imbalanced search corpus data. The role of the retrieval component within a sponsored search system is pivotal, serving as the initial step that directly affects the subsequent ranking and bidding systems. In this paper, we present an end-to-end solution tailored to optimize the ads retrieval system on Walmart.com. Our approach is to pretrain the BERT-like classification model with product category information, enhancing the model's understanding of Walmart product semantics. Second, we design a two-tower Siamese Network structure for embedding structures to augment training efficiency. Third, we introduce a Human-in-the-loop Progressive Fusion Training method to ensure robust model performance. Our results demonstrate the effectiveness of this pipeline. It enhances the search relevance metric by up to 16% compared to a baseline DSSM-based model. Moreover, our large-scale online A/B testing demonstrates that our approach surpasses the ad revenue of the existing production model.
Towards the Unification of Generative and Discriminative Visual Foundation Model: A Survey
Dec 15, 2023The advent of foundation models, which are pre-trained on vast datasets, has ushered in a new era of computer vision, characterized by their robustness and remarkable zero-shot generalization capabilities. Mirroring the transformative impact of foundation models like large language models (LLMs) in natural language processing, visual foundation models (VFMs) have become a catalyst for groundbreaking developments in computer vision. This review paper delineates the pivotal trajectories of VFMs, emphasizing their scalability and proficiency in generative tasks such as text-to-image synthesis, as well as their adeptness in discriminative tasks including image segmentation. While generative and discriminative models have historically charted distinct paths, we undertake a comprehensive examination of the recent strides made by VFMs in both domains, elucidating their origins, seminal breakthroughs, and pivotal methodologies. Additionally, we collate and discuss the extensive resources that facilitate the development of VFMs and address the challenges that pave the way for future research endeavors. A crucial direction for forthcoming innovation is the amalgamation of generative and discriminative paradigms. The nascent application of generative models within discriminative contexts signifies the early stages of this confluence. This survey aspires to be a contemporary compendium for scholars and practitioners alike, charting the course of VFMs and illuminating their multifaceted landscape.
Enhanced E-Commerce Attribute Extraction: Innovating with Decorative Relation Correction and LLAMA 2.0-Based Annotation
Dec 09, 2023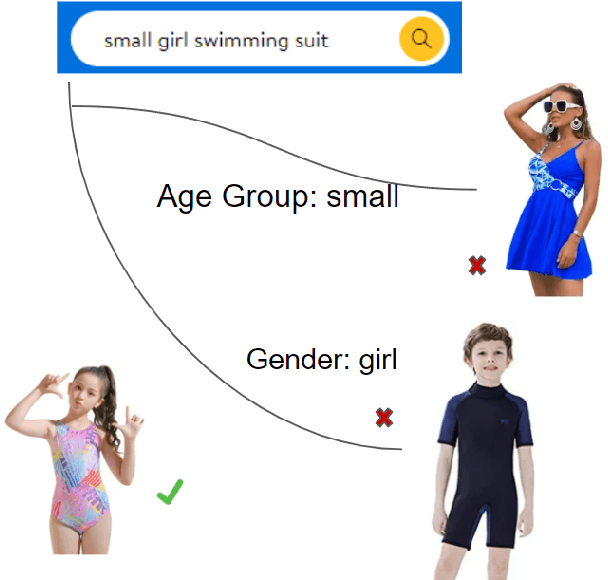
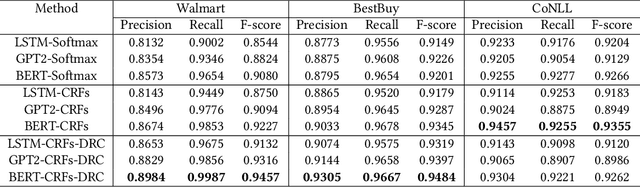
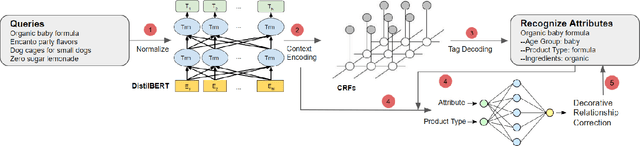
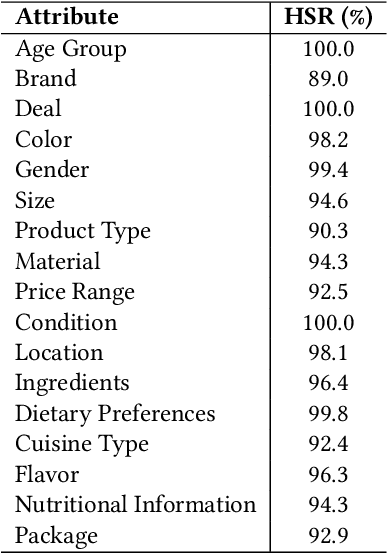
The rapid proliferation of e-commerce platforms accentuates the need for advanced search and retrieval systems to foster a superior user experience. Central to this endeavor is the precise extraction of product attributes from customer queries, enabling refined search, comparison, and other crucial e-commerce functionalities. Unlike traditional Named Entity Recognition (NER) tasks, e-commerce queries present a unique challenge owing to the intrinsic decorative relationship between product types and attributes. In this study, we propose a pioneering framework that integrates BERT for classification, a Conditional Random Fields (CRFs) layer for attribute value extraction, and Large Language Models (LLMs) for data annotation, significantly advancing attribute recognition from customer inquiries. Our approach capitalizes on the robust representation learning of BERT, synergized with the sequence decoding prowess of CRFs, to adeptly identify and extract attribute values. We introduce a novel decorative relation correction mechanism to further refine the extraction process based on the nuanced relationships between product types and attributes inherent in e-commerce data. Employing LLMs, we annotate additional data to expand the model's grasp and coverage of diverse attributes. Our methodology is rigorously validated on various datasets, including Walmart, BestBuy's e-commerce NER dataset, and the CoNLL dataset, demonstrating substantial improvements in attribute recognition performance. Particularly, the model showcased promising results during a two-month deployment in Walmart's Sponsor Product Search, underscoring its practical utility and effectiveness.
Practical Lessons on Optimizing Sponsored Products in eCommerce
Apr 05, 2023



In this paper, we study multiple problems from sponsored product optimization in ad system, including position-based de-biasing, click-conversion multi-task learning, and calibration on predicted click-through-rate (pCTR). We propose a practical machine learning framework that provides the solutions to such problems without structural change to existing machine learning models, thus can be combined with most machine learning models including shallow models (e.g. gradient boosting decision trees, support vector machines). In this paper, we first propose data and feature engineering techniques to handle the aforementioned problems in ad system; after that, we evaluate the benefit of our practical framework on real-world data sets from our traffic logs from online shopping site. We show that our proposed practical framework with data and feature engineering can also handle the perennial problems in ad systems and bring increments to multiple evaluation metrics.
Transformer and GAN Based Super-Resolution Reconstruction Network for Medical Images
Dec 26, 2022



Because of the necessity to obtain high-quality images with minimal radiation doses, such as in low-field magnetic resonance imaging, super-resolution reconstruction in medical imaging has become more popular (MRI). However, due to the complexity and high aesthetic requirements of medical imaging, image super-resolution reconstruction remains a difficult challenge. In this paper, we offer a deep learning-based strategy for reconstructing medical images from low resolutions utilizing Transformer and Generative Adversarial Networks (T-GAN). The integrated system can extract more precise texture information and focus more on important locations through global image matching after successfully inserting Transformer into the generative adversarial network for picture reconstruction. Furthermore, we weighted the combination of content loss, adversarial loss, and adversarial feature loss as the final multi-task loss function during the training of our proposed model T-GAN. In comparison to established measures like PSNR and SSIM, our suggested T-GAN achieves optimal performance and recovers more texture features in super-resolution reconstruction of MRI scanned images of the knees and belly.
Unsupervised Learning Based Focal Stack Camera Depth Estimation
Mar 14, 2022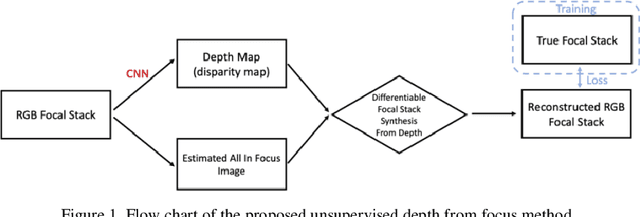

We propose an unsupervised deep learning based method to estimate depth from focal stack camera images. On the NYU-v2 dataset, our method achieves much better depth estimation accuracy compared to single-image based methods.