 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
AniFaceDrawing: Anime Portrait Exploration during Your Sketching
Jun 13, 2023In this paper, we focus on how artificial intelligence (AI) can be used to assist users in the creation of anime portraits, that is, converting rough sketches into anime portraits during their sketching process. The input is a sequence of incomplete freehand sketches that are gradually refined stroke by stroke, while the output is a sequence of high-quality anime portraits that correspond to the input sketches as guidance. Although recent GANs can generate high quality images, it is a challenging problem to maintain the high quality of generated images from sketches with a low degree of completion due to ill-posed problems in conditional image generation. Even with the latest sketch-to-image (S2I) technology, it is still difficult to create high-quality images from incomplete rough sketches for anime portraits since anime style tend to be more abstract than in realistic style. To address this issue, we adopt a latent space exploration of StyleGAN with a two-stage training strategy. We consider the input strokes of a freehand sketch to correspond to edge information-related attributes in the latent structural code of StyleGAN, and term the matching between strokes and these attributes stroke-level disentanglement. In the first stage, we trained an image encoder with the pre-trained StyleGAN model as a teacher encoder. In the second stage, we simulated the drawing process of the generated images without any additional data (labels) and trained the sketch encoder for incomplete progressive sketches to generate high-quality portrait images with feature alignment to the disentangled representations in the teacher encoder. We verified the proposed progressive S2I system with both qualitative and quantitative evaluations and achieved high-quality anime portraits from incomplete progressive sketches. Our user study proved its effectiveness in art creation assistance for the anime style.
Unsupervised Learning Based Focal Stack Camera Depth Estimation
Mar 14, 2022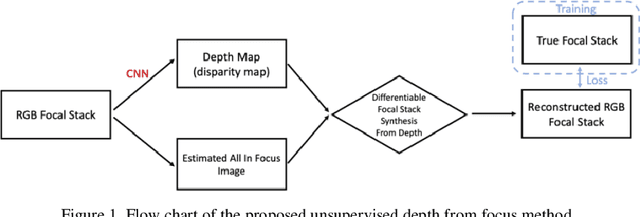

We propose an unsupervised deep learning based method to estimate depth from focal stack camera images. On the NYU-v2 dataset, our method achieves much better depth estimation accuracy compared to single-image based methods.
Interactive 3D Character Modeling from 2D Orthogonal Drawings with Annotations
Jan 27, 2022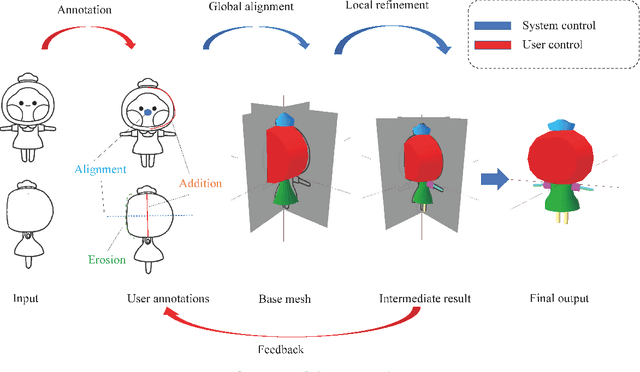
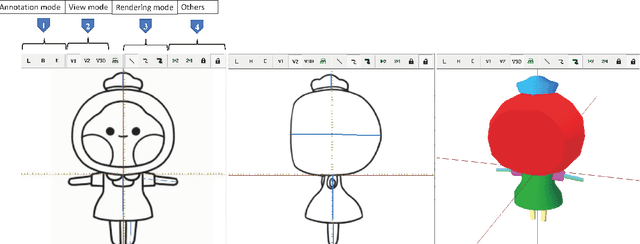
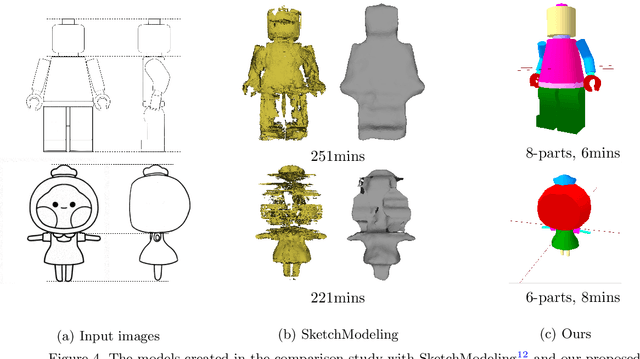
We propose an interactive 3D character modeling approach from orthographic drawings (e.g., front and side views) based on 2D-space annotations. First, the system builds partial correspondences between the input drawings and generates a base mesh with sweeping splines according to edge information in 2D images. Next, users annotates the desired parts on the input drawings (e.g., the eyes and mouth) by using two type of strokes, called addition and erosion, and the system re-optimizes the shape of the base mesh. By repeating the 2D-space operations (i.e., revising and modifying the annotations), users can design a desired character model. To validate the efficiency and quality of our system, we verified the generated results with state-of-the-art methods.
dualFace:Two-Stage Drawing Guidance for Freehand Portrait Sketching
Apr 26, 2021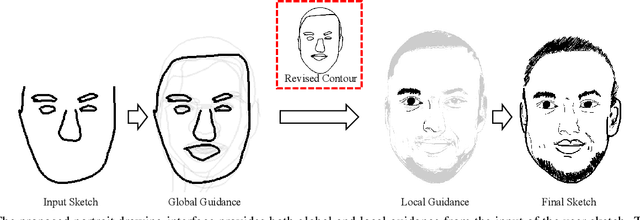
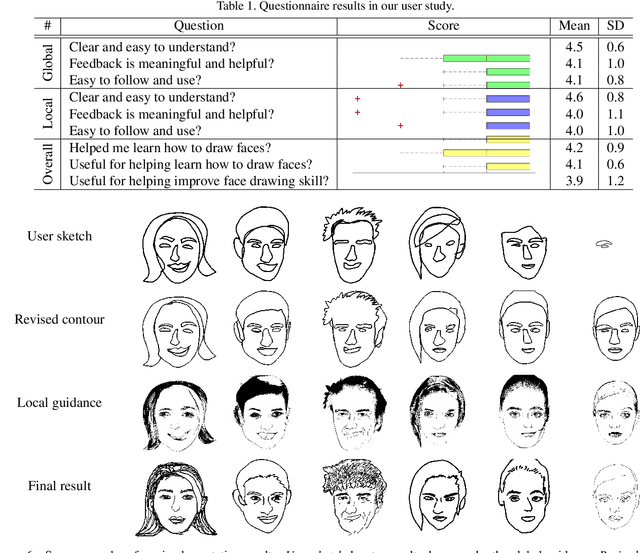
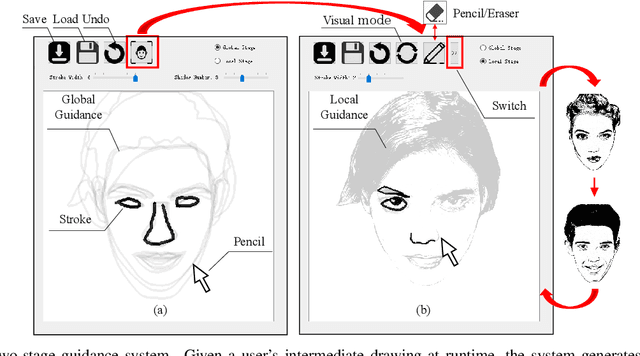
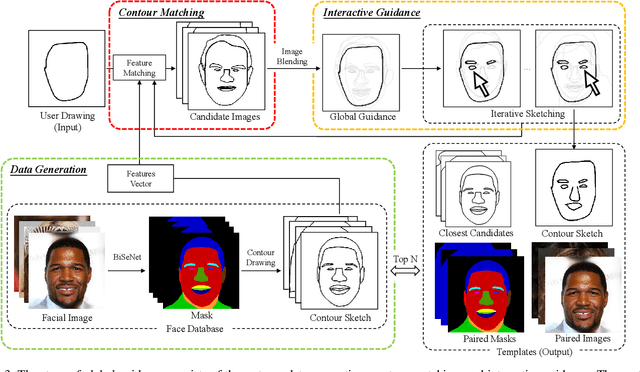
In this paper, we propose dualFace, a portrait drawing interface to assist users with different levels of drawing skills to complete recognizable and authentic face sketches. dualFace consists of two-stage drawing assistance to provide global and local visual guidance: global guidance, which helps users draw contour lines of portraits (i.e., geometric structure), and local guidance, which helps users draws details of facial parts (which conform to user-drawn contour lines), inspired by traditional artist workflows in portrait drawing. In the stage of global guidance, the user draws several contour lines, and dualFace then searches several relevant images from an internal database and displays the suggested face contour lines over the background of the canvas. In the stage of local guidance, we synthesize detailed portrait images with a deep generative model from user-drawn contour lines, but use the synthesized results as detailed drawing guidance. We conducted a user study to verify the effectiveness of dualFace, and we confirmed that dualFace significantly helps achieve a detailed portrait sketch. see http://www.jaist.ac.jp/~xie/dualface.html
ES-Net: An Efficient Stereo Matching Network
Mar 05, 2021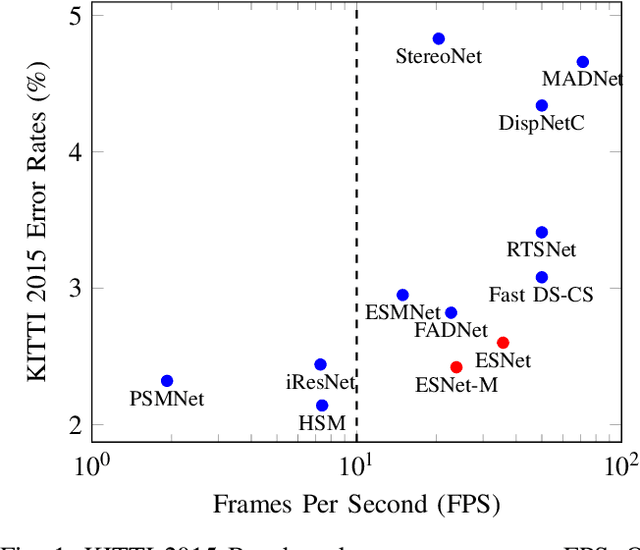
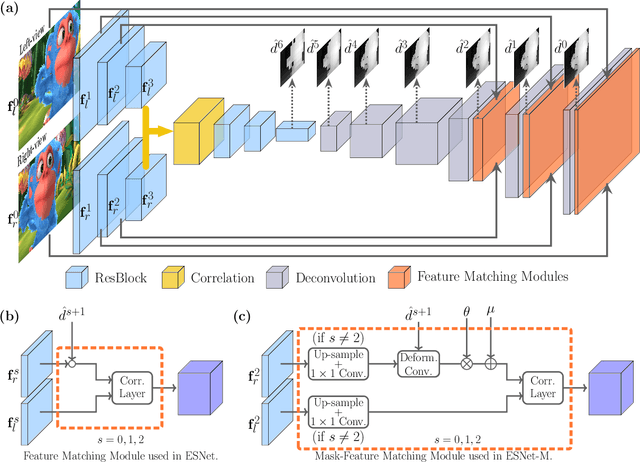

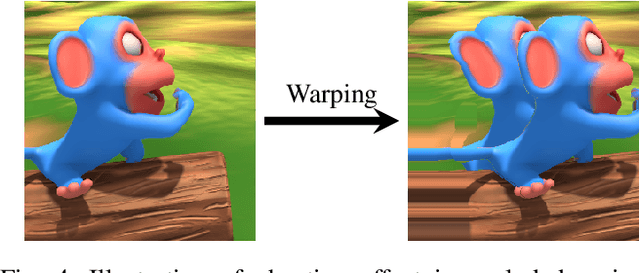
Dense stereo matching with deep neural networks is of great interest to the research community. Existing stereo matching networks typically use slow and computationally expensive 3D convolutions to improve the performance, which is not friendly to real-world applications such as autonomous driving. In this paper, we propose the Efficient Stereo Network (ESNet), which achieves high performance and efficient inference at the same time. ESNet relies only on 2D convolution and computes multi-scale cost volume efficiently using a warping-based method to improve the performance in regions with fine-details. In addition, we address the matching ambiguity issue in the occluded region by proposing ESNet-M, a variant of ESNet that additionally estimates an occlusion mask without supervision. We further improve the network performance by proposing a new training scheme that includes dataset scheduling and unsupervised pre-training. Compared with other low-cost dense stereo depth estimation methods, our proposed approach achieves state-of-the-art performance on the Scene Flow [1], DrivingStereo [2], and KITTI-2015 dataset [3]. Our code will be made available.
Momentum-Net: Fast and convergent iterative neural network for inverse problems
Sep 11, 2019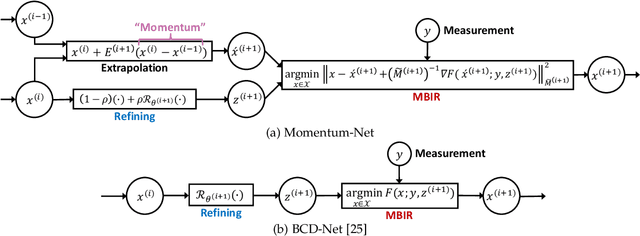
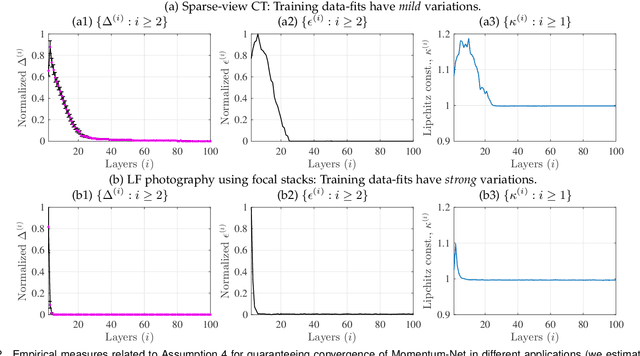
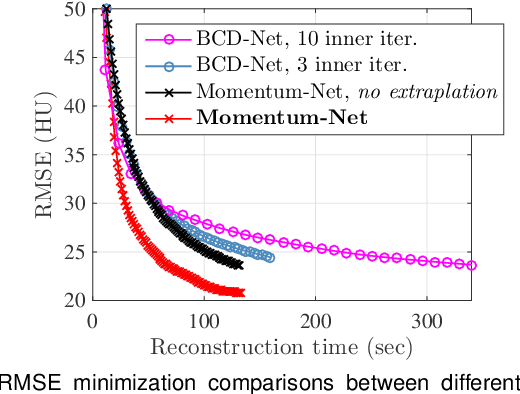
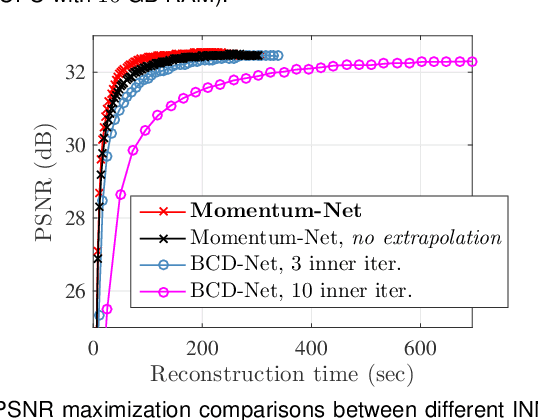
Iterative neural networks (INN) are rapidly gaining attention for solving inverse problems in imaging, image processing, and computer vision. INNs combine regression NNs and an iterative model-based image reconstruction (MBIR) algorithm, leading to both good generalization capability and outperforming reconstruction quality over existing MBIR optimization models. This paper proposes the first fast and convergent INN architecture, Momentum-Net, by generalizing a block-wise MBIR algorithm that uses momentums and majorizers with regression NNs. For fast MBIR, Momentum-Net uses momentum terms in extrapolation modules, and noniterative MBIR modules at each layer by using majorizers, where each layer of Momentum-Net consists of three core modules: image refining, extrapolation, and MBIR. Momentum-Net guarantees convergence to a fixed-point for general differentiable (non)convex MBIR functions (or data-fit terms) and convex feasible sets, under two asymptomatic conditions. To consider data-fit variations across training and testing samples, we also propose a regularization parameter selection scheme based on the spectral radius of majorization matrices. Numerical experiments for light-field photography using a focal stack and sparse-view computational tomography demonstrate that given identical regression NN architectures, Momentum-Net significantly improves MBIR speed and accuracy over several existing INNs; it significantly improves reconstruction quality compared to a state-of-the-art MBIR method in each application.