 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Forecasting Framework based on Multi-Stage Hierarchical Forecasting Reconciliation and Adjustment
Dec 19, 2024
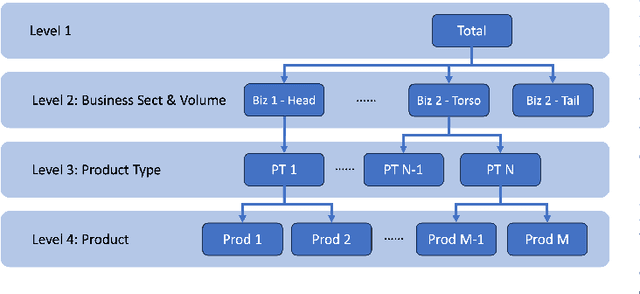


Ads demand forecasting for Walmart's ad products plays a critical role in enabling effective resource planning, allocation, and management of ads performance. In this paper, we introduce a comprehensive demand forecasting system that tackles hierarchical time series forecasting in business settings. Though traditional hierarchical reconciliation methods ensure forecasting coherence, they often trade off accuracy for coherence especially at lower levels and fail to capture the seasonality unique to each time-series in the hierarchy. Thus, we propose a novel framework "Multi-Stage Hierarchical Forecasting Reconciliation and Adjustment (Multi-Stage HiFoReAd)" to address the challenges of preserving seasonality, ensuring coherence, and improving accuracy. Our system first utilizes diverse models, ensembled through Bayesian Optimization (BO), achieving base forecasts. The generated base forecasts are then passed into the Multi-Stage HiFoReAd framework. The initial stage refines the hierarchy using Top-Down forecasts and "harmonic alignment." The second stage aligns the higher levels' forecasts using MinTrace algorithm, following which the last two levels undergo "harmonic alignment" and "stratified scaling", to eventually achieve accurate and coherent forecasts across the whole hierarchy. Our experiments on Walmart's internal Ads-demand dataset and 3 other public datasets, each with 4 hierarchical levels, demonstrate that the average Absolute Percentage Error from the cross-validation sets improve from 3% to 40% across levels against BO-ensemble of models (LGBM, MSTL+ETS, Prophet) as well as from 1.2% to 92.9% against State-Of-The-Art models. In addition, the forecasts at all hierarchical levels are proved to be coherent. The proposed framework has been deployed and leveraged by Walmart's ads, sales and operations teams to track future demands, make informed decisions and plan resources.
Automatic Speech Recognition for Hindi
Jun 26, 2024Automatic speech recognition (ASR) is a key area in computational linguistics, focusing on developing technologies that enable computers to convert spoken language into text. This field combines linguistics and machine learning. ASR models, which map speech audio to transcripts through supervised learning, require handling real and unrestricted text. Text-to-speech systems directly work with real text, while ASR systems rely on language models trained on large text corpora. High-quality transcribed data is essential for training predictive models. The research involved two main components: developing a web application and designing a web interface for speech recognition. The web application, created with JavaScript and Node.js, manages large volumes of audio files and their transcriptions, facilitating collaborative human correction of ASR transcripts. It operates in real-time using a client-server architecture. The web interface for speech recognition records 16 kHz mono audio from any device running the web app, performs voice activity detection (VAD), and sends the audio to the recognition engine. VAD detects human speech presence, aiding efficient speech processing and reducing unnecessary processing during non-speech intervals, thus saving computation and network bandwidth in VoIP applications. The final phase of the research tested a neural network for accurately aligning the speech signal to hidden Markov model (HMM) states. This included implementing a novel backpropagation method that utilizes prior statistics of node co-activations.
Seeded Hierarchical Clustering for Expert-Crafted Taxonomies
May 23, 2022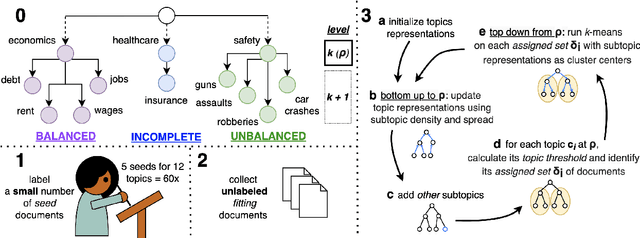
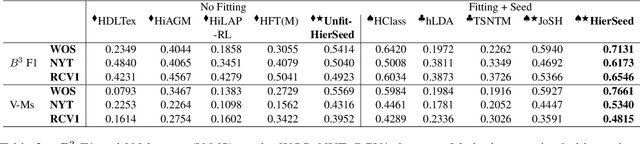
Practitioners from many disciplines (e.g., political science) use expert-crafted taxonomies to make sense of large, unlabeled corpora. In this work, we study Seeded Hierarchical Clustering (SHC): the task of automatically fitting unlabeled data to such taxonomies using only a small set of labeled examples. We propose HierSeed, a novel weakly supervised algorithm for this task that uses only a small set of labeled seed examples. It is both data and computationally efficient. HierSeed assigns documents to topics by weighing document density against topic hierarchical structure. It outperforms both unsupervised and supervised baselines for the SHC task on three real-world datasets.