 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Speech Recognition for Hindi
Jun 26, 2024Automatic speech recognition (ASR) is a key area in computational linguistics, focusing on developing technologies that enable computers to convert spoken language into text. This field combines linguistics and machine learning. ASR models, which map speech audio to transcripts through supervised learning, require handling real and unrestricted text. Text-to-speech systems directly work with real text, while ASR systems rely on language models trained on large text corpora. High-quality transcribed data is essential for training predictive models. The research involved two main components: developing a web application and designing a web interface for speech recognition. The web application, created with JavaScript and Node.js, manages large volumes of audio files and their transcriptions, facilitating collaborative human correction of ASR transcripts. It operates in real-time using a client-server architecture. The web interface for speech recognition records 16 kHz mono audio from any device running the web app, performs voice activity detection (VAD), and sends the audio to the recognition engine. VAD detects human speech presence, aiding efficient speech processing and reducing unnecessary processing during non-speech intervals, thus saving computation and network bandwidth in VoIP applications. The final phase of the research tested a neural network for accurately aligning the speech signal to hidden Markov model (HMM) states. This included implementing a novel backpropagation method that utilizes prior statistics of node co-activations.
Brain-scale Theta Band Functional Connectivity As A Signature of Slow Breathing and Breath-hold Phases
Dec 15, 2023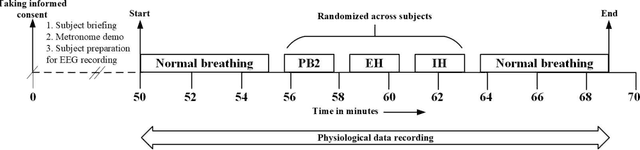
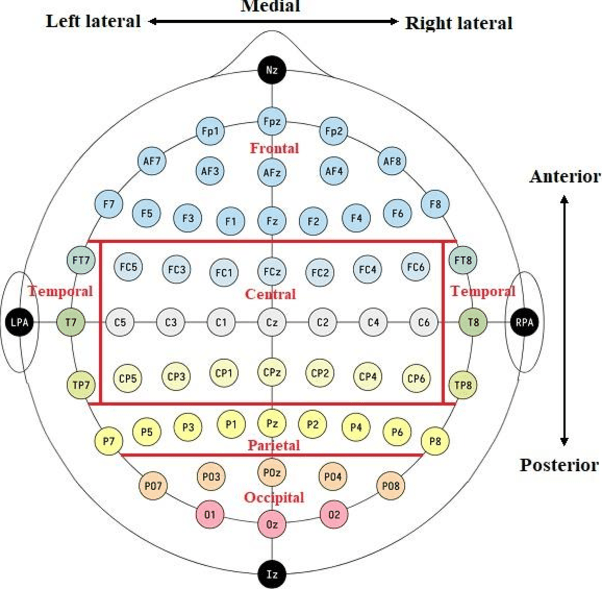

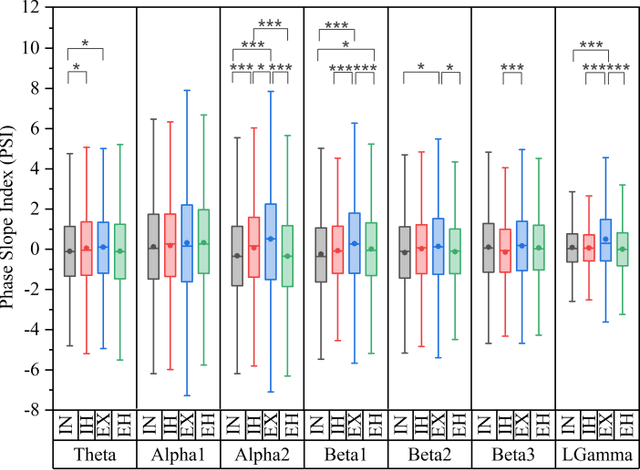
The study reported herein attempts to understand the neural mechanisms engaged in the conscious control of breathing and breath-hold. The variations in the electroencephalogram (EEG) based functional connectivity (FC) of the human brain during consciously controlled breathing at 2 cycles per minute (cpm), and breath-hold have been investigated and reported here. An experimental protocol involving controlled breathing and breath-hold sessions, synchronized to a visual metronome, was designed and administered to 20 healthy subjects (9 females and 11 males). EEG data were collected during these sessions using the 61-channel eego mylab system from ANT Neuro. Further, FC was estimated for all possible pairs of EEG time series data, for 7 EEG bands. Feature selection using a genetic algorithm (GA) was performed to identify a subset of functional connections that would best distinguish the inhale, exhale, inhale-hold, and exhale-hold phases using a random committee classifier. The best accuracy of 93.36 % was obtained when 1161 theta-band functional connections were fed as input to the classifier, highlighting the efficacy of the theta-band functional connectome in distinguishing these phases of the respiratory cycle. This functional network was further characterized using graph measures, and observations illustrated a statistically significant difference in the efficiency of information exchange through the network during different respiratory phases.
A Classifier Using Global Character Level and Local Sub-unit Level Features for Hindi Online Handwritten Character Recognition
Oct 26, 2023


A classifier is developed that defines a joint distribution of global character features, number of sub-units and local sub-unit features to model Hindi online handwritten characters. The classifier uses latent variables to model the structure of sub-units. The classifier uses histograms of points, orientations, and dynamics of orientations (HPOD) features to represent characters at global character level and local sub-unit level and is independent of character stroke order and stroke direction variations. The parameters of the classifier is estimated using maximum likelihood method. Different classifiers and features used in other studies are considered in this study for classification performance comparison with the developed classifier. The classifiers considered are Second Order Statistics (SOS), Sub-space (SS), Fisher Discriminant (FD), Feedforward Neural Network (FFN) and Support Vector Machines (SVM) and the features considered are Spatio Temporal (ST), Discrete Fourier Transform (DFT), Discrete Cosine Transform (SCT), Discrete Wavelet Transform (DWT), Spatial (SP) and Histograms of Oriented Gradients (HOG). Hindi character datasets used for training and testing the developed classifier consist of samples of handwritten characters from 96 different character classes. There are 12832 samples with an average of 133 samples per character class in the training set and 2821 samples with an average of 29 samples per character class in the testing set. The developed classifier has the highest accuracy of 93.5\% on the testing set compared to that of the classifiers trained on different features extracted from the same training set and evaluated on the same testing set considered in this study.
Structural analysis of Hindi online handwritten characters for character recognition
Oct 12, 2023



Direction properties of online strokes are used to analyze them in terms of homogeneous regions or sub-strokes with points satisfying common geometric properties. Such sub-strokes are called sub-units. These properties are used to extract sub-units from Hindi ideal online characters. These properties along with some heuristics are used to extract sub-units from Hindi online handwritten characters.\\ A method is developed to extract point stroke, clockwise curve stroke, counter-clockwise curve stroke and loop stroke segments as sub-units from Hindi online handwritten characters. These extracted sub-units are close in structure to the sub-units of the corresponding Hindi online ideal characters.\\ Importance of local representation of online handwritten characters in terms of sub-units is assessed by training a classifier with sub-unit level local and character level global features extracted from characters for character recognition. The classifier has the recognition accuracy of 93.5\% on the testing set. This accuracy is the highest when compared with that of the classifiers trained only with global features extracted from characters in the same training set and evaluated on the same testing set.\\ Sub-unit extraction algorithm and the sub-unit based character classifier are tested on Hindi online handwritten character dataset. This dataset consists of samples from 96 different characters. There are 12832 and 2821 samples in the training and testing sets, respectively.
Histograms of Points, Orientations, and Dynamics of Orientations Features for Hindi Online Handwritten Character Recognition
Sep 05, 2023



A set of features independent of character stroke direction and order variations is proposed for online handwritten character recognition. A method is developed that maps features like co-ordinates of points, orientations of strokes at points, and dynamics of orientations of strokes at points spatially as a function of co-ordinate values of the points and computes histograms of these features from different regions in the spatial map. Different features like spatio-temporal, discrete Fourier transform, discrete cosine transform, discrete wavelet transform, spatial, and histograms of oriented gradients used in other studies for training classifiers for character recognition are considered. The classifier chosen for classification performance comparison, when trained with different features, is support vector machines (SVM). The character datasets used for training and testing the classifiers consist of online handwritten samples of 96 different Hindi characters. There are 12832 and 2821 samples in training and testing datasets, respectively. SVM classifiers trained with the proposed features has the highest classification accuracy of 92.9\% when compared to the performances of SVM classifiers trained with the other features and tested on the same testing dataset. Therefore, the proposed features have better character discriminative capability than the other features considered for comparison.
A Novel Deep Learning Architecture for Decoding Imagined Speech from EEG
Mar 19, 2020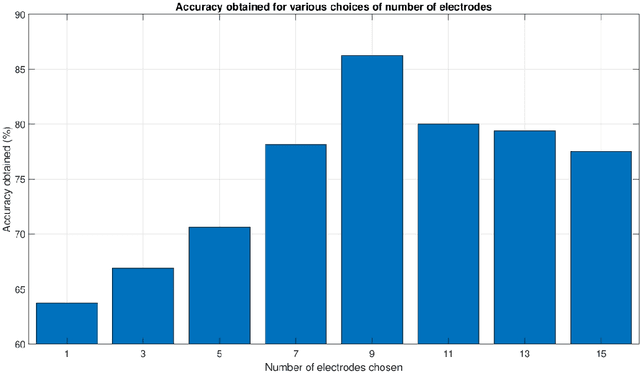
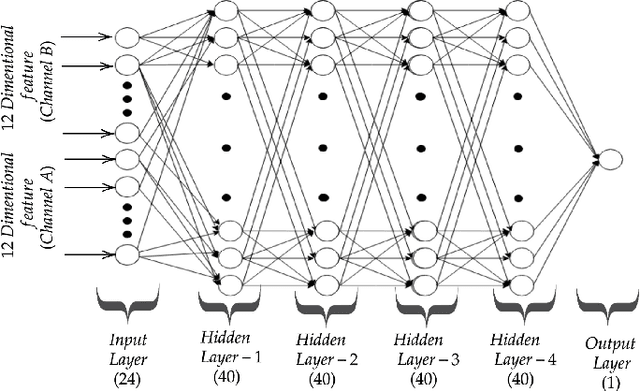
The recent advances in the field of deep learning have not been fully utilised for decoding imagined speech primarily because of the unavailability of sufficient training samples to train a deep network. In this paper, we present a novel architecture that employs deep neural network (DNN) for classifying the words "in" and "cooperate" from the corresponding EEG signals in the ASU imagined speech dataset. Nine EEG channels, which best capture the underlying cortical activity, are chosen using common spatial pattern (CSP) and are treated as independent data vectors. Discrete wavelet transform (DWT) is used for feature extraction. To the best of our knowledge, so far DNN has not been employed as a classifier in decoding imagined speech. Treating the selected EEG channels corresponding to each imagined word as independent data vectors helps in providing sufficient number of samples to train a DNN. For each test trial, the final class label is obtained by applying a majority voting on the classification results of the individual channels considered in the trial. We have achieved accuracies comparable to the state-of-the-art results. The results can be further improved by using a higher-density EEG acquisition system in conjunction with other deep learning techniques such as long short-term memory.
Decoding Imagined Speech using Wavelet Features and Deep Neural Networks
Mar 19, 2020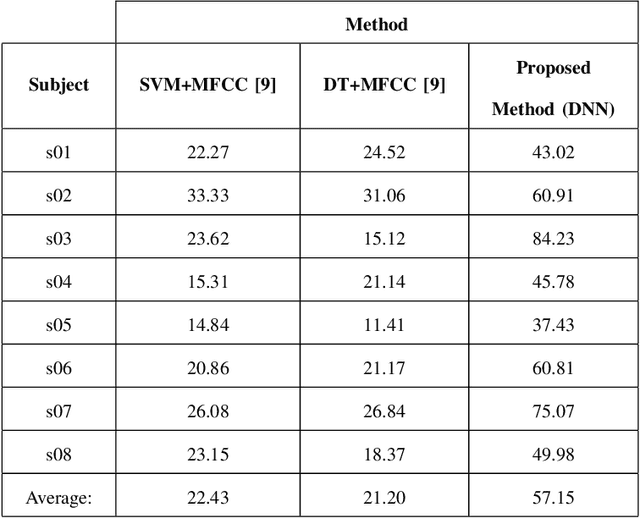
This paper proposes a novel approach that uses deep neural networks for classifying imagined speech, significantly increasing the classification accuracy. The proposed approach employs only the EEG channels over specific areas of the brain for classification, and derives distinct feature vectors from each of those channels. This gives us more data to train a classifier, enabling us to use deep learning approaches. Wavelet and temporal domain features are extracted from each channel. The final class label of each test trial is obtained by applying a majority voting on the classification results of the individual channels considered in the trial. This approach is used for classifying all the 11 prompts in the KaraOne dataset of imagined speech. The proposed architecture and the approach of treating the data have resulted in an average classification accuracy of 57.15%, which is an improvement of around 35% over the state-of-the-art results.
An Improved EEG Acquisition Protocol Facilitates Localized Neural Activation
Mar 13, 2020
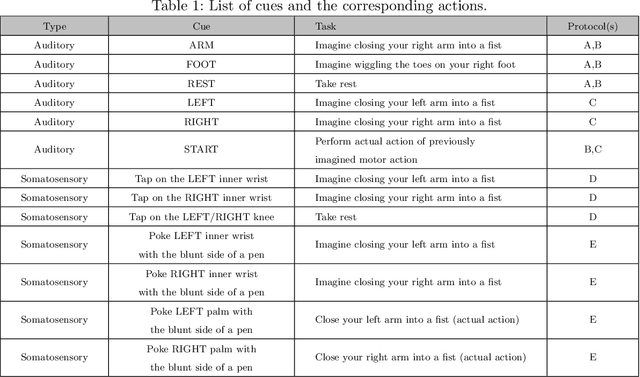
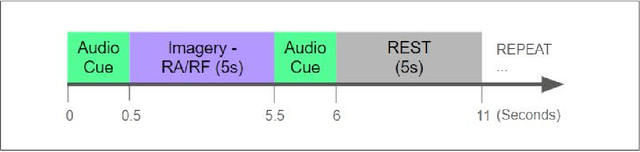
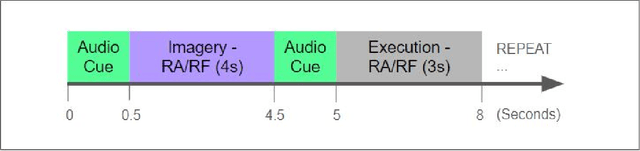
This work proposes improvements in the electroencephalogram (EEG) recording protocols for motor imagery through the introduction of actual motor movement and/or somatosensory cues. The results obtained demonstrate the advantage of requiring the subjects to perform motor actions following the trials of imagery. By introducing motor actions in the protocol, the subjects are able to perform actual motor planning, rather than just visualizing the motor movement, thus greatly improving the ease with which the motor movements can be imagined. This study also probes the added advantage of administering somatosensory cues in the subject, as opposed to the conventional auditory/visual cues. These changes in the protocol show promise in terms of the aptness of the spatial filters obtained on the data, on application of the well-known common spatial pattern (CSP) algorithms. The regions highlighted by the spatial filters are more localized and consistent across the subjects when the protocol is augmented with somatosensory stimuli. Hence, we suggest that this may prove to be a better EEG acquisition protocol for detecting brain activation in response to intended motor commands in (clinically) paralyzed/locked-in patients.
Intrinsic normalization and extrinsic denormalization of formant data of vowels
Dec 10, 2016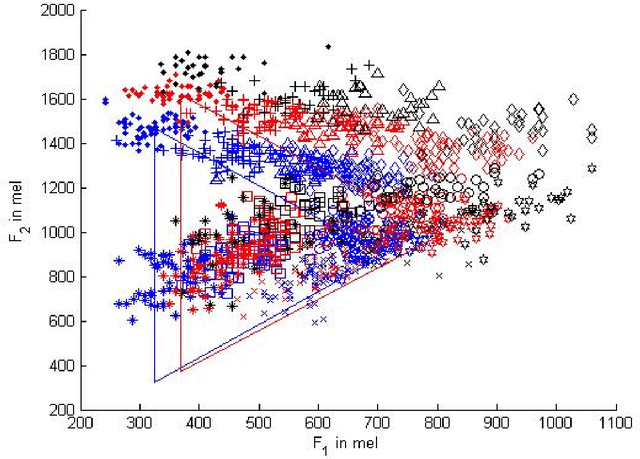
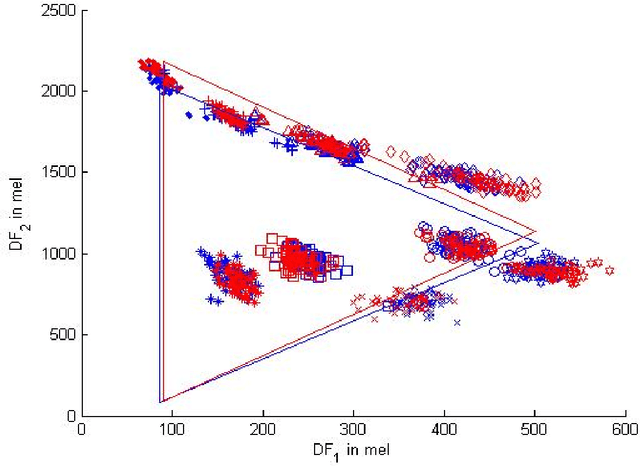
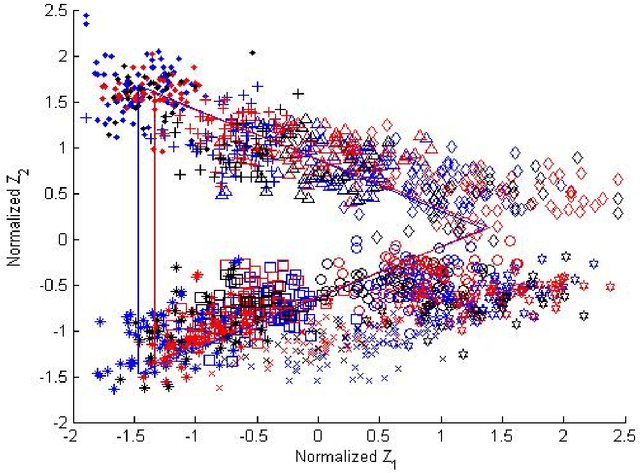
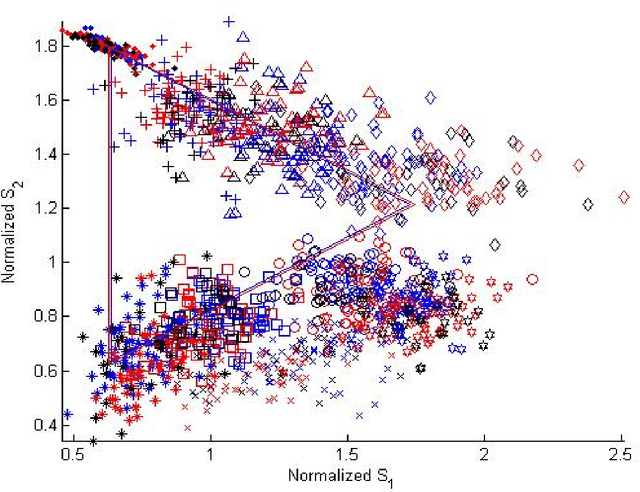
Using a known speaker-intrinsic normalization procedure, formant data are scaled by the reciprocal of the geometric mean of the first three formant frequencies. This reduces the influence of the talker but results in a distorted vowel space. The proposed speaker-extrinsic procedure re-scales the normalized values by the mean formant values of vowels. When tested on the formant data of vowels published by Peterson and Barney, the combined approach leads to well separated clusters by reducing the spread due to talkers. The proposed procedure performs better than two top-ranked normalization procedures based on the accuracy of vowel classification as the objective measure.
Significance of the levels of spectral valleys with application to front/back distinction of vowel sounds
Oct 05, 2015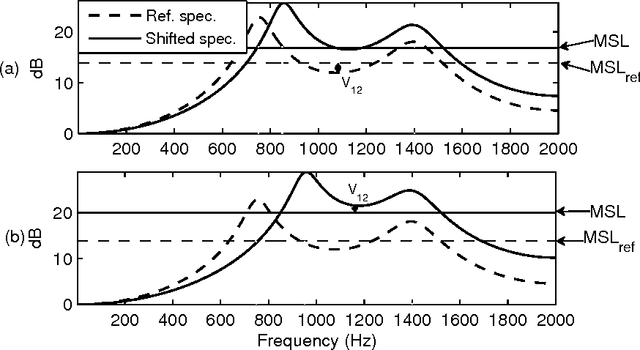
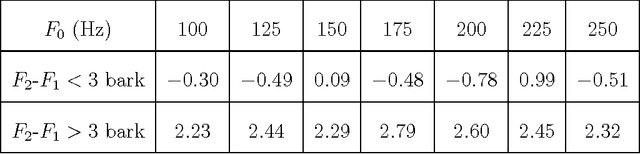
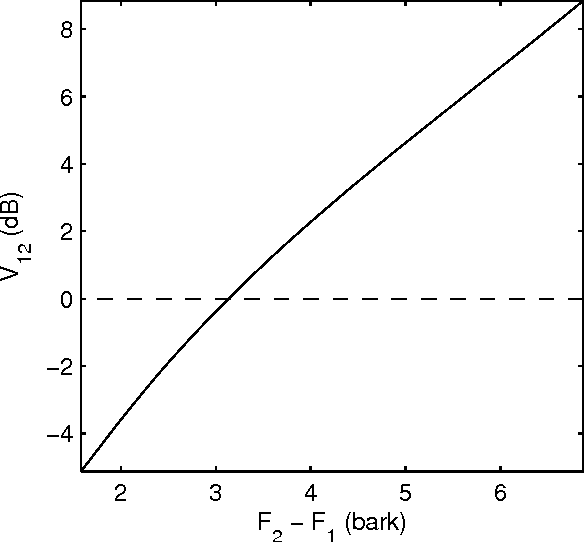
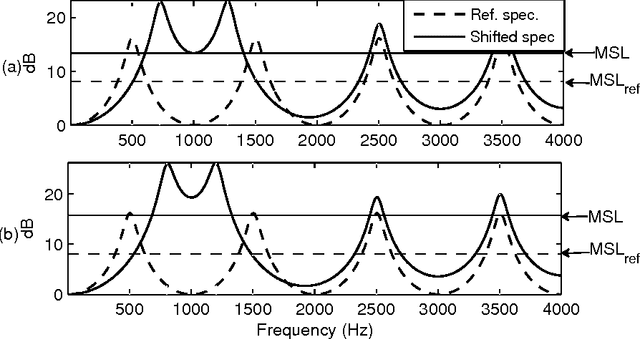
An objective critical distance (OCD) has been defined as that spacing between adjacent formants, when the level of the valley between them reaches the mean spectral level. The measured OCD lies in the same range (viz., 3-3.5 bark) as the critical distance determined by subjective experiments for similar experimental conditions. The level of spectral valley serves a purpose similar to that of the spacing between the formants with an added advantage that it can be measured from the spectral envelope without an explicit knowledge of formant frequencies. Based on the relative spacing of formant frequencies, the level of the spectral valley, VI (between F1 and F2) is much higher than the level of VII (spectral valley between F2 and F3) for back vowels and vice-versa for front vowels. Classification of vowels into front/back distinction with the difference (VI-VII) as an acoustic feature, tested using TIMIT, NTIMIT, Tamil and Kannada language databases gives, on the average, an accuracy of about 95%, which is comparable to the accuracy (90.6%) obtained using a neural network classifier trained and tested using MFCC as the feature vector for TIMIT database. The acoustic feature (VI-VII) has also been tested for its robustness on the TIMIT database for additive white and babble noise and an accuracy of about 95% has been obtained for SNRs down to 25 dB for both types of noise.