 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Deep Learning Architecture for Decoding Imagined Speech from EEG
Mar 19, 2020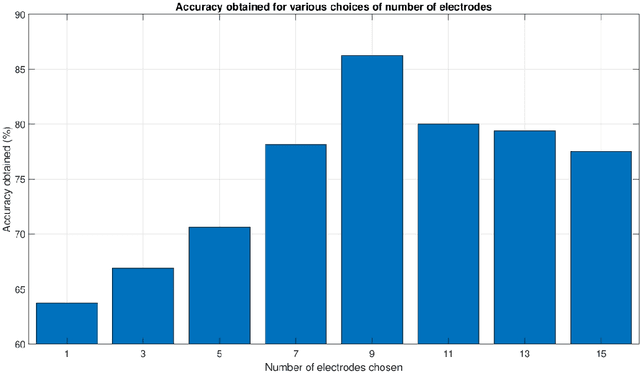
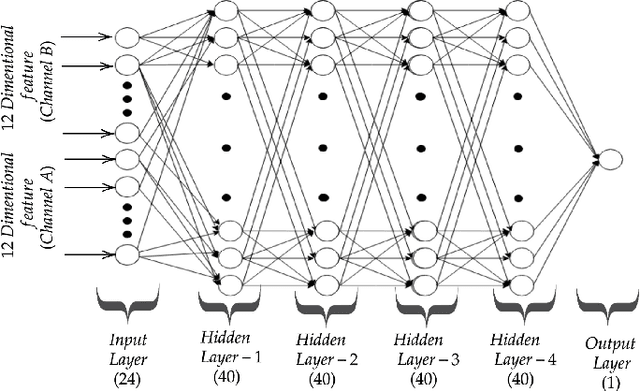
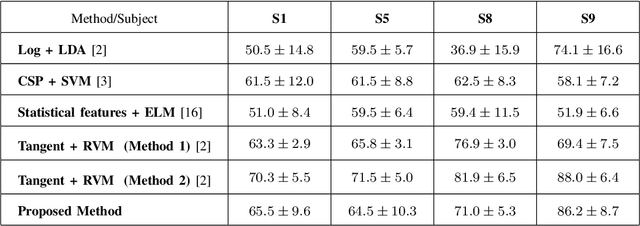
The recent advances in the field of deep learning have not been fully utilised for decoding imagined speech primarily because of the unavailability of sufficient training samples to train a deep network. In this paper, we present a novel architecture that employs deep neural network (DNN) for classifying the words "in" and "cooperate" from the corresponding EEG signals in the ASU imagined speech dataset. Nine EEG channels, which best capture the underlying cortical activity, are chosen using common spatial pattern (CSP) and are treated as independent data vectors. Discrete wavelet transform (DWT) is used for feature extraction. To the best of our knowledge, so far DNN has not been employed as a classifier in decoding imagined speech. Treating the selected EEG channels corresponding to each imagined word as independent data vectors helps in providing sufficient number of samples to train a DNN. For each test trial, the final class label is obtained by applying a majority voting on the classification results of the individual channels considered in the trial. We have achieved accuracies comparable to the state-of-the-art results. The results can be further improved by using a higher-density EEG acquisition system in conjunction with other deep learning techniques such as long short-term memory.
Intrinsic normalization and extrinsic denormalization of formant data of vowels
Dec 10, 2016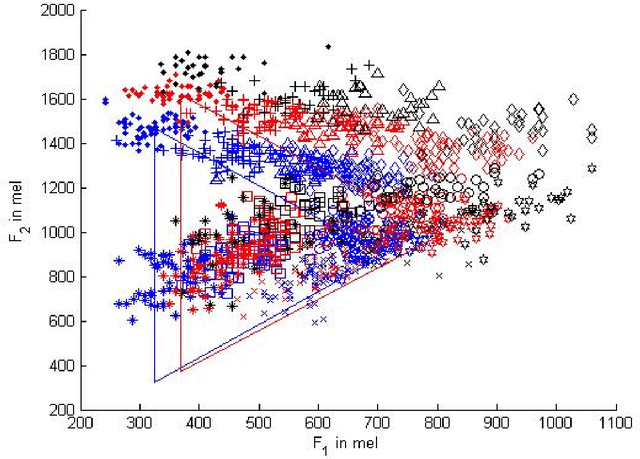
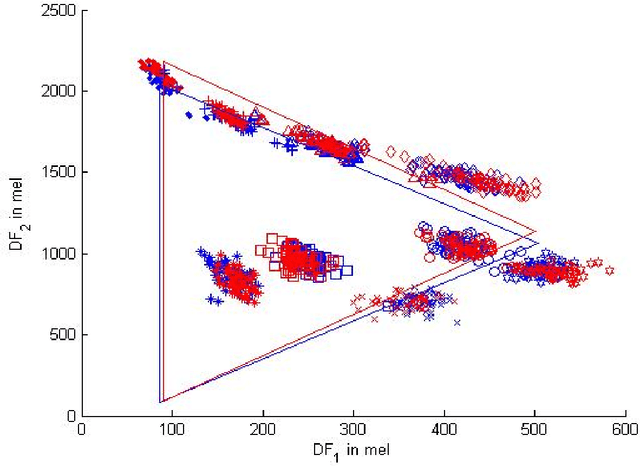
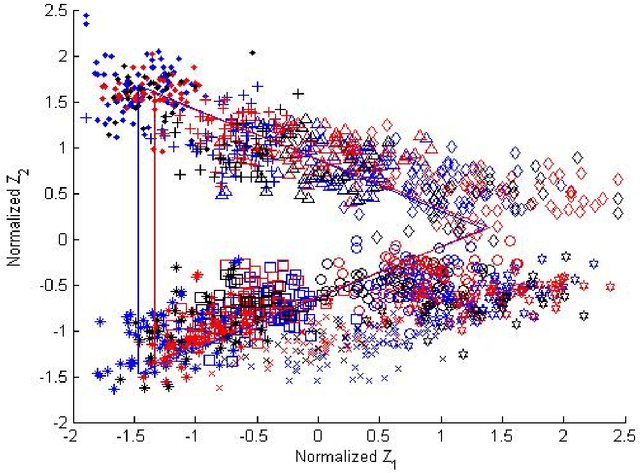
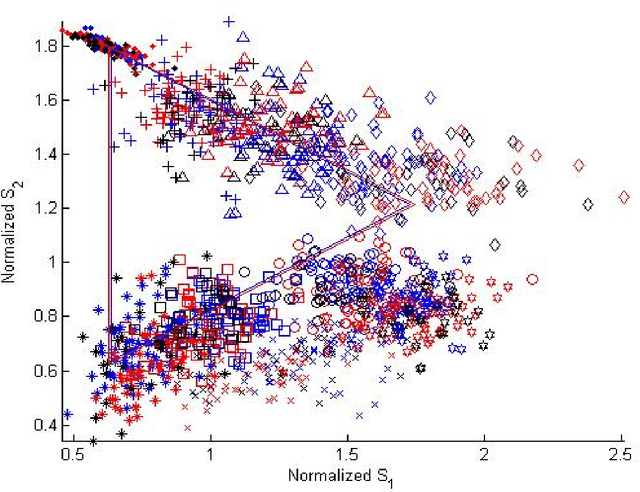
Using a known speaker-intrinsic normalization procedure, formant data are scaled by the reciprocal of the geometric mean of the first three formant frequencies. This reduces the influence of the talker but results in a distorted vowel space. The proposed speaker-extrinsic procedure re-scales the normalized values by the mean formant values of vowels. When tested on the formant data of vowels published by Peterson and Barney, the combined approach leads to well separated clusters by reducing the spread due to talkers. The proposed procedure performs better than two top-ranked normalization procedures based on the accuracy of vowel classification as the objective measure.
Significance of the levels of spectral valleys with application to front/back distinction of vowel sounds
Oct 05, 2015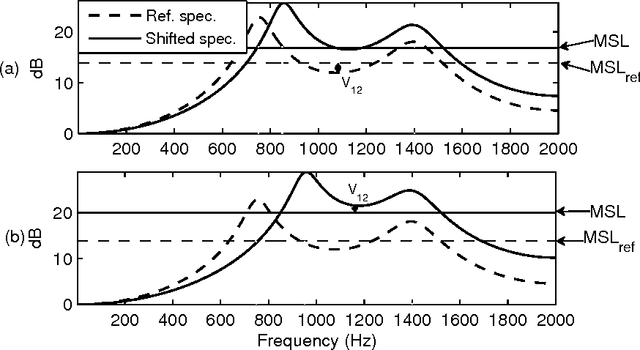
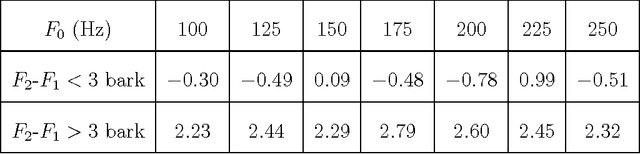
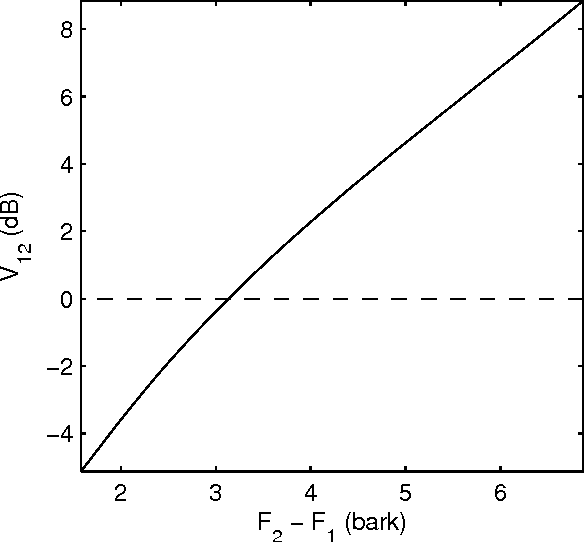
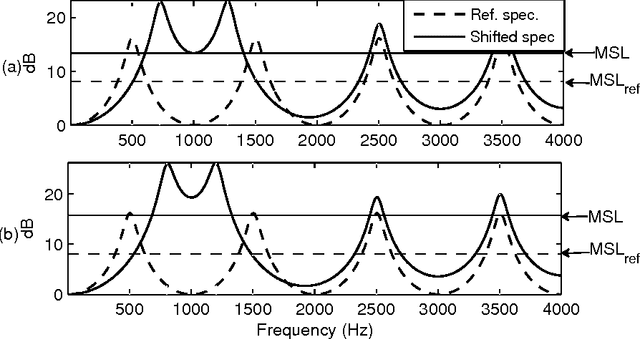
An objective critical distance (OCD) has been defined as that spacing between adjacent formants, when the level of the valley between them reaches the mean spectral level. The measured OCD lies in the same range (viz., 3-3.5 bark) as the critical distance determined by subjective experiments for similar experimental conditions. The level of spectral valley serves a purpose similar to that of the spacing between the formants with an added advantage that it can be measured from the spectral envelope without an explicit knowledge of formant frequencies. Based on the relative spacing of formant frequencies, the level of the spectral valley, VI (between F1 and F2) is much higher than the level of VII (spectral valley between F2 and F3) for back vowels and vice-versa for front vowels. Classification of vowels into front/back distinction with the difference (VI-VII) as an acoustic feature, tested using TIMIT, NTIMIT, Tamil and Kannada language databases gives, on the average, an accuracy of about 95%, which is comparable to the accuracy (90.6%) obtained using a neural network classifier trained and tested using MFCC as the feature vector for TIMIT database. The acoustic feature (VI-VII) has also been tested for its robustness on the TIMIT database for additive white and babble noise and an accuracy of about 95% has been obtained for SNRs down to 25 dB for both types of noise.