 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
Quantum Machine Learning for Cybersecurity: A Taxonomy and Future Directions
Dec 17, 2025The increasing number of cyber threats and rapidly evolving tactics, as well as the high volume of data in recent years, have caused classical machine learning, rules, and signature-based defence strategies to fail, rendering them unable to keep up. An alternative, Quantum Machine Learning (QML), has recently emerged, making use of computations based on quantum mechanics. It offers better encoding and processing of high-dimensional structures for certain problems. This survey provides a comprehensive overview of QML techniques relevant to the domain of security, such as Quantum Neural Networks (QNNs), Quantum Support Vector Machines (QSVMs), Variational Quantum Circuits (VQCs), and Quantum Generative Adversarial Networks (QGANs), and discusses the contributions of this paper in relation to existing research in the field and how it improves over them. It also maps these methods across supervised, unsupervised, and generative learning paradigms, and to core cybersecurity tasks, including intrusion and anomaly detection, malware and botnet classification, and encrypted-traffic analytics. It also discusses their application in the domain of cloud computing security, where QML can enhance secure and scalable operations. Many limitations of QML in the domain of cybersecurity have also been discussed, along with the directions for addressing them.
Analyticup E-commerce Product Search Competition Technical Report from Team Tredence_AICOE
Oct 23, 2025This study presents the multilingual e-commerce search system developed by the Tredence_AICOE team. The competition features two multilingual relevance tasks: Query-Category (QC) Relevance, which evaluates how well a user's search query aligns with a product category, and Query-Item (QI) Relevance, which measures the match between a multilingual search query and an individual product listing. To ensure full language coverage, we performed data augmentation by translating existing datasets into languages missing from the development set, enabling training across all target languages. We fine-tuned Gemma-3 12B and Qwen-2.5 14B model for both tasks using multiple strategies. The Gemma-3 12B (4-bit) model achieved the best QC performance using original and translated data, and the best QI performance using original, translated, and minority class data creation. These approaches secured 4th place on the final leaderboard, with an average F1-score of 0.8857 on the private test set.
From Idea to Implementation: Evaluating the Influence of Large Language Models in Software Development -- An Opinion Paper
Mar 10, 2025The introduction of transformer architecture was a turning point in Natural Language Processing (NLP). Models based on the transformer architecture such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-Trained Transformer (GPT) have gained widespread popularity in various applications such as software development and education. The availability of Large Language Models (LLMs) such as ChatGPT and Bard to the general public has showcased the tremendous potential of these models and encouraged their integration into various domains such as software development for tasks such as code generation, debugging, and documentation generation. In this study, opinions from 11 experts regarding their experience with LLMs for software development have been gathered and analysed to draw insights that can guide successful and responsible integration. The overall opinion of the experts is positive, with the experts identifying advantages such as increase in productivity and reduced coding time. Potential concerns and challenges such as risk of over-dependence and ethical considerations have also been highlighted.
Exploring the Impact of Generative Artificial Intelligence in Education: A Thematic Analysis
Jan 17, 2025



The recent advancements in Generative Artificial intelligence (GenAI) technology have been transformative for the field of education. Large Language Models (LLMs) such as ChatGPT and Bard can be leveraged to automate boilerplate tasks, create content for personalised teaching, and handle repetitive tasks to allow more time for creative thinking. However, it is important to develop guidelines, policies, and assessment methods in the education sector to ensure the responsible integration of these tools. In this article, thematic analysis has been performed on seven essays obtained from professionals in the education sector to understand the advantages and pitfalls of using GenAI models such as ChatGPT and Bard in education. Exploratory Data Analysis (EDA) has been performed on the essays to extract further insights from the text. The study found several themes which highlight benefits and drawbacks of GenAI tools, as well as suggestions to overcome these limitations and ensure that students are using these tools in a responsible and ethical manner.
Interpretable LLM-based Table Question Answering
Dec 16, 2024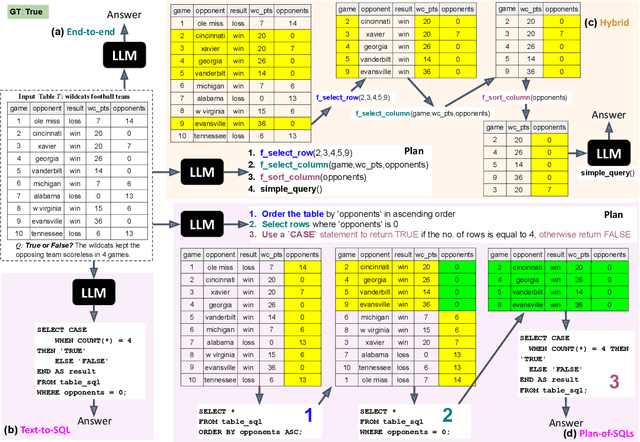

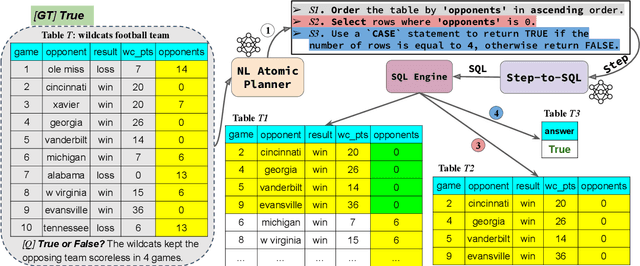
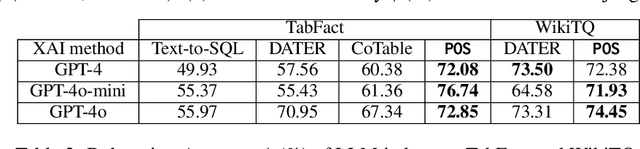
Interpretability for Table Question Answering (Table QA) is critical, particularly in high-stakes industries like finance or healthcare. Although recent approaches using Large Language Models (LLMs) have significantly improved Table QA performance, their explanations for how the answers are generated are ambiguous. To fill this gap, we introduce Plan-of-SQLs ( or POS), an interpretable, effective, and efficient approach to Table QA that answers an input query solely with SQL executions. Through qualitative and quantitative evaluations with human and LLM judges, we show that POS is most preferred among explanation methods, helps human users understand model decision boundaries, and facilitates model success and error identification. Furthermore, when evaluated in standard benchmarks (TabFact, WikiTQ, and FetaQA), POS achieves competitive or superior accuracy compared to existing methods, while maintaining greater efficiency by requiring significantly fewer LLM calls and database queries.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024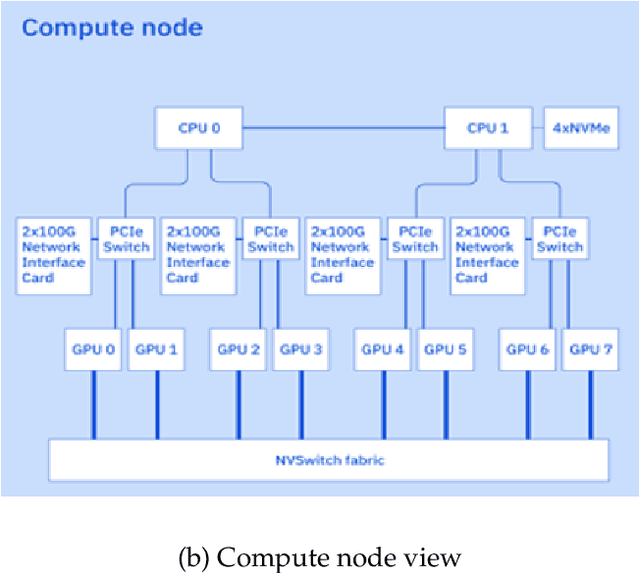
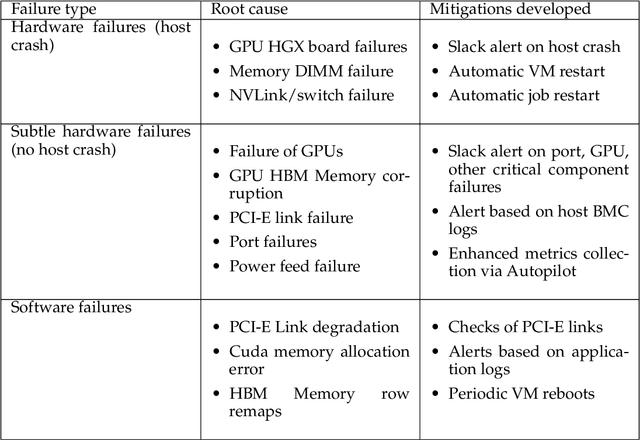
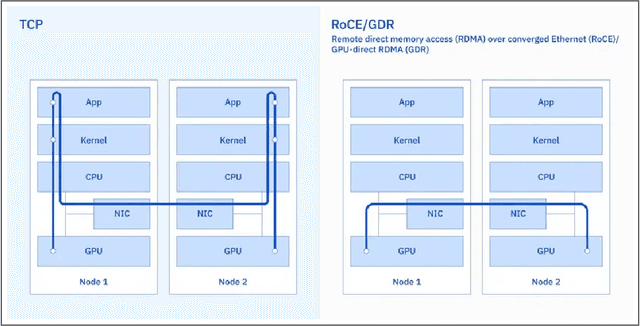
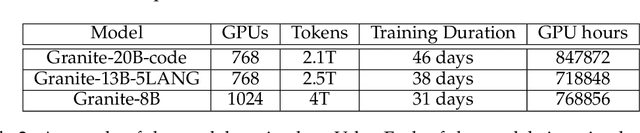
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
REFRESH: Responsible and Efficient Feature Reselection Guided by SHAP Values
Mar 13, 2024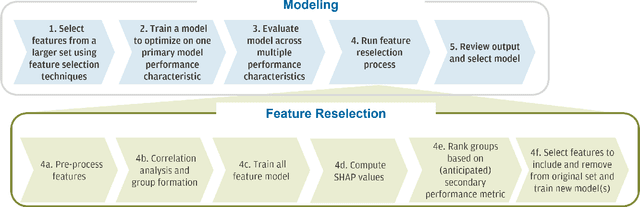


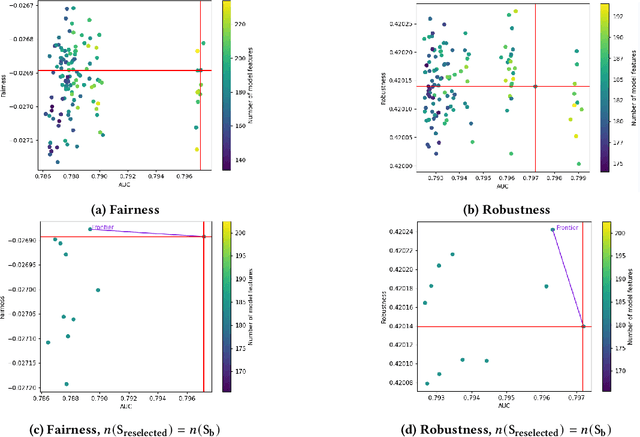
Feature selection is a crucial step in building machine learning models. This process is often achieved with accuracy as an objective, and can be cumbersome and computationally expensive for large-scale datasets. Several additional model performance characteristics such as fairness and robustness are of importance for model development. As regulations are driving the need for more trustworthy models, deployed models need to be corrected for model characteristics associated with responsible artificial intelligence. When feature selection is done with respect to one model performance characteristic (eg. accuracy), feature selection with secondary model performance characteristics (eg. fairness and robustness) as objectives would require going through the computationally expensive selection process from scratch. In this paper, we introduce the problem of feature \emph{reselection}, so that features can be selected with respect to secondary model performance characteristics efficiently even after a feature selection process has been done with respect to a primary objective. To address this problem, we propose REFRESH, a method to reselect features so that additional constraints that are desirable towards model performance can be achieved without having to train several new models. REFRESH's underlying algorithm is a novel technique using SHAP values and correlation analysis that can approximate for the predictions of a model without having to train these models. Empirical evaluations on three datasets, including a large-scale loan defaulting dataset show that REFRESH can help find alternate models with better model characteristics efficiently. We also discuss the need for reselection and REFRESH based on regulation desiderata.
The Effect of Data Poisoning on Counterfactual Explanations
Feb 13, 2024Counterfactual explanations provide a popular method for analyzing the predictions of black-box systems, and they can offer the opportunity for computational recourse by suggesting actionable changes on how to change the input to obtain a different (i.e. more favorable) system output. However, recent work highlighted their vulnerability to different types of manipulations. This work studies the vulnerability of counterfactual explanations to data poisoning. We formalize data poisoning in the context of counterfactual explanations for increasing the cost of recourse on three different levels: locally for a single instance, or a sub-group of instances, or globally for all instances. We demonstrate that state-of-the-art counterfactual generation methods \& toolboxes are vulnerable to such data poisoning.
Privacy-Preserving Algorithmic Recourse
Nov 23, 2023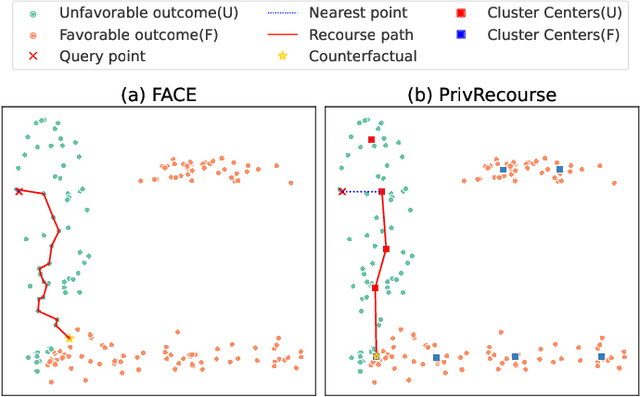

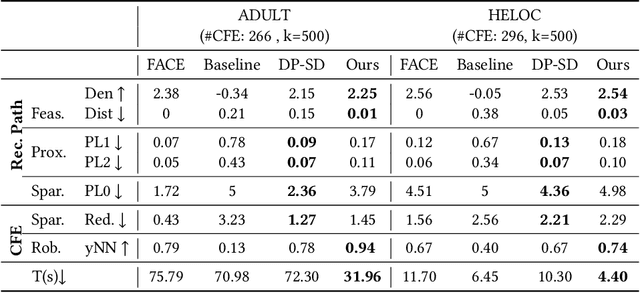
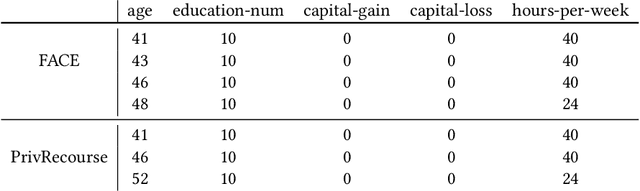
When individuals are subject to adverse outcomes from machine learning models, providing a recourse path to help achieve a positive outcome is desirable. Recent work has shown that counterfactual explanations - which can be used as a means of single-step recourse - are vulnerable to privacy issues, putting an individuals' privacy at risk. Providing a sequential multi-step path for recourse can amplify this risk. Furthermore, simply adding noise to recourse paths found from existing methods can impact the realism and actionability of the path for an end-user. In this work, we address privacy issues when generating realistic recourse paths based on instance-based counterfactual explanations, and provide PrivRecourse: an end-to-end privacy preserving pipeline that can provide realistic recourse paths. PrivRecourse uses differentially private (DP) clustering to represent non-overlapping subsets of the private dataset. These DP cluster centers are then used to generate recourse paths by forming a graph with cluster centers as the nodes, so that we can generate realistic - feasible and actionable - recourse paths. We empirically evaluate our approach on finance datasets and compare it to simply adding noise to data instances, and to using DP synthetic data, to generate the graph. We observe that PrivRecourse can provide paths that are private and realistic.