 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Hardness of Computing Counterfactual and Semifactual Explanations in XAI
Jan 14, 2026Providing clear explanations to the choices of machine learning models is essential for these models to be deployed in crucial applications. Counterfactual and semi-factual explanations have emerged as two mechanisms for providing users with insights into the outputs of their models. We provide an overview of the computational complexity results in the literature for generating these explanations, finding that in many cases, generating explanations is computationally hard. We strengthen the argument for this considerably by further contributing our own inapproximability results showing that not only are explanations often hard to generate, but under certain assumptions, they are also hard to approximate. We discuss the implications of these complexity results for the XAI community and for policymakers seeking to regulate explanations in AI.
* Accepted in Transactions on Machine Learning Research (TMLR), 2025 -- https://openreview.net/pdf?id=aELzBw0q1O
Interpretable Event Diagnosis in Water Distribution Networks
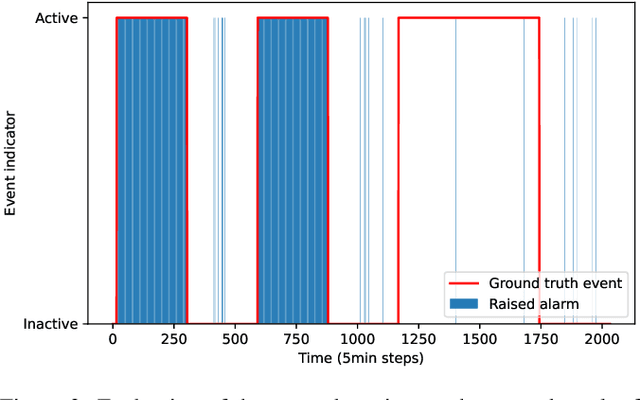
May 12, 2025The increasing penetration of information and communication technologies in the design, monitoring, and control of water systems enables the use of algorithms for detecting and identifying unanticipated events (such as leakages or water contamination) using sensor measurements. However, data-driven methodologies do not always give accurate results and are often not trusted by operators, who may prefer to use their engineering judgment and experience to deal with such events. In this work, we propose a framework for interpretable event diagnosis -- an approach that assists the operators in associating the results of algorithmic event diagnosis methodologies with their own intuition and experience. This is achieved by providing contrasting (i.e., counterfactual) explanations of the results provided by fault diagnosis algorithms; their aim is to improve the understanding of the algorithm's inner workings by the operators, thus enabling them to take a more informed decision by combining the results with their personal experiences. Specifically, we propose counterfactual event fingerprints, a representation of the difference between the current event diagnosis and the closest alternative explanation, which can be presented in a graphical way. The proposed methodology is applied and evaluated on a realistic use case using the L-Town benchmark.
Challenges, Methods, Data -- a Survey of Machine Learning in Water Distribution Networks
Oct 16, 2024Research on methods for planning and controlling water distribution networks gains increasing relevance as the availability of drinking water will decrease as a consequence of climate change. So far, the majority of approaches is based on hydraulics and engineering expertise. However, with the increasing availability of sensors, machine learning techniques constitute a promising tool. This work presents the main tasks in water distribution networks, discusses how they relate to machine learning and analyses how the particularities of the domain pose challenges to and can be leveraged by machine learning approaches. Besides, it provides a technical toolkit by presenting evaluation benchmarks and a structured survey of the exemplary task of leakage detection and localization.
Analyzing the Influence of Training Samples on Explanations
Jun 05, 2024EXplainable AI (XAI) constitutes a popular method to analyze the reasoning of AI systems by explaining their decision-making, e.g. providing a counterfactual explanation of how to achieve recourse. However, in cases such as unexpected explanations, the user might be interested in learning about the cause of this explanation -- e.g. properties of the utilized training data that are responsible for the observed explanation. Under the umbrella of data valuation, first approaches have been proposed that estimate the influence of data samples on a given model. In this work, we take a slightly different stance, as we are interested in the influence of single samples on a model explanation rather than the model itself. Hence, we propose the novel problem of identifying training data samples that have a high influence on a given explanation (or related quantity) and investigate the particular case of differences in the cost of the recourse between protected groups. For this, we propose an algorithm that identifies such influential training samples.
A Toolbox for Supporting Research on AI in Water Distribution Networks
Jun 04, 2024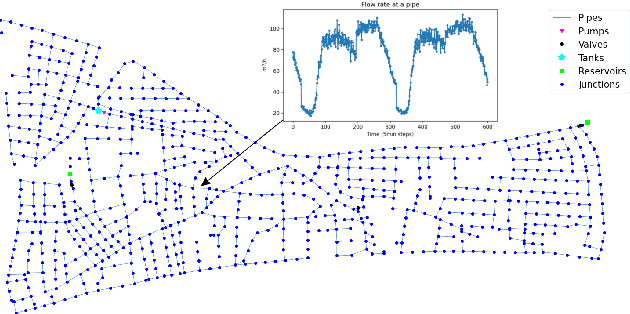
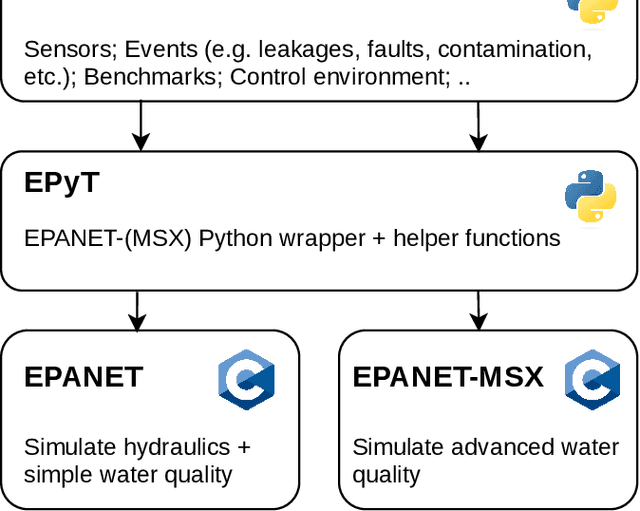
Drinking water is a vital resource for humanity, and thus, Water Distribution Networks (WDNs) are considered critical infrastructures in modern societies. The operation of WDNs is subject to diverse challenges such as water leakages and contamination, cyber/physical attacks, high energy consumption during pump operation, etc. With model-based methods reaching their limits due to various uncertainty sources, AI methods offer promising solutions to those challenges. In this work, we introduce a Python toolbox for complex scenario modeling \& generation such that AI researchers can easily access challenging problems from the drinking water domain. Besides providing a high-level interface for the easy generation of hydraulic and water quality scenario data, it also provides easy access to popular event detection benchmarks and an environment for developing control algorithms.
A Two-Stage Algorithm for Cost-Efficient Multi-instance Counterfactual Explanations
Mar 02, 2024

Counterfactual explanations constitute among the most popular methods for analyzing the predictions of black-box systems since they can recommend cost-efficient and actionable changes to the input to turn an undesired system's output into a desired output. While most of the existing counterfactual methods explain a single instance, several real-world use cases, such as customer satisfaction, require the identification of a single counterfactual that can satisfy multiple instances (e.g. customers) simultaneously. In this work, we propose a flexible two-stage algorithm for finding groups of instances along with cost-efficient multi-instance counterfactual explanations. This is motivated by the fact that in most previous works the aspect of finding such groups is not addressed.
The Effect of Data Poisoning on Counterfactual Explanations
Feb 13, 2024Counterfactual explanations provide a popular method for analyzing the predictions of black-box systems, and they can offer the opportunity for computational recourse by suggesting actionable changes on how to change the input to obtain a different (i.e. more favorable) system output. However, recent work highlighted their vulnerability to different types of manipulations. This work studies the vulnerability of counterfactual explanations to data poisoning. We formalize data poisoning in the context of counterfactual explanations for increasing the cost of recourse on three different levels: locally for a single instance, or a sub-group of instances, or globally for all instances. We demonstrate that state-of-the-art counterfactual generation methods \& toolboxes are vulnerable to such data poisoning.
For Better or Worse: The Impact of Counterfactual Explanations' Directionality on User Behavior in xAI
Jun 13, 2023Counterfactual explanations (CFEs) are a popular approach in explainable artificial intelligence (xAI), highlighting changes to input data necessary for altering a model's output. A CFE can either describe a scenario that is better than the factual state (upward CFE), or a scenario that is worse than the factual state (downward CFE). However, potential benefits and drawbacks of the directionality of CFEs for user behavior in xAI remain unclear. The current user study (N=161) compares the impact of CFE directionality on behavior and experience of participants tasked to extract new knowledge from an automated system based on model predictions and CFEs. Results suggest that upward CFEs provide a significant performance advantage over other forms of counterfactual feedback. Moreover, the study highlights potential benefits of mixed CFEs improving user performance compared to downward CFEs or no explanations. In line with the performance results, users' explicit knowledge of the system is statistically higher after receiving upward CFEs compared to downward comparisons. These findings imply that the alignment between explanation and task at hand, the so-called regulatory fit, may play a crucial role in determining the effectiveness of model explanations, informing future research directions in xAI. To ensure reproducible research, the entire code, underlying models and user data of this study is openly available: https://github.com/ukuhl/DirectionalAlienZoo
"How to make them stay?" -- Diverse Counterfactual Explanations of Employee Attrition
Mar 08, 2023Employee attrition is an important and complex problem that can directly affect an organisation's competitiveness and performance. Explaining the reasons why employees leave an organisation is a key human resource management challenge due to the high costs and time required to attract and keep talented employees. Businesses therefore aim to increase employee retention rates to minimise their costs and maximise their performance. Machine learning (ML) has been applied in various aspects of human resource management including attrition prediction to provide businesses with insights on proactive measures on how to prevent talented employees from quitting. Among these ML methods, the best performance has been reported by ensemble or deep neural networks, which by nature constitute black box techniques and thus cannot be easily interpreted. To enable the understanding of these models' reasoning several explainability frameworks have been proposed. Counterfactual explanation methods have attracted considerable attention in recent years since they can be used to explain and recommend actions to be performed to obtain the desired outcome. However current counterfactual explanations methods focus on optimising the changes to be made on individual cases to achieve the desired outcome. In the attrition problem it is important to be able to foresee what would be the effect of an organisation's action to a group of employees where the goal is to prevent them from leaving the company. Therefore, in this paper we propose the use of counterfactual explanations focusing on multiple attrition cases from historical data, to identify the optimum interventions that an organisation needs to make to its practices/policies to prevent or minimise attrition probability for these cases.
Explainable Artificial Intelligence for Improved Modeling of Processes
Dec 01, 2022In modern business processes, the amount of data collected has increased substantially in recent years. Because this data can potentially yield valuable insights, automated knowledge extraction based on process mining has been proposed, among other techniques, to provide users with intuitive access to the information contained therein. At present, the majority of technologies aim to reconstruct explicit business process models. These are directly interpretable but limited concerning the integration of diverse and real-valued information sources. On the other hand, Machine Learning (ML) benefits from the vast amount of data available and can deal with high-dimensional sources, yet it has rarely been applied to being used in processes. In this contribution, we evaluate the capability of modern Transformer architectures as well as more classical ML technologies of modeling process regularities, as can be quantitatively evaluated by their prediction capability. In addition, we demonstrate the capability of attentional properties and feature relevance determination by highlighting features that are crucial to the processes' predictive abilities. We demonstrate the efficacy of our approach using five benchmark datasets and show that the ML models are capable of predicting critical outcomes and that the attention mechanisms or XAI components offer new insights into the underlying processes.
* 12 pages, 3 tables, 3 figures. Published in IDEAL 2022: https://link.springer.com/chapter/10.1007/978-3-031-21753-1_31