 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift Localization using Conformal Predictions
Feb 23, 2026Concept drift -- the change of the distribution over time -- poses significant challenges for learning systems and is of central interest for monitoring. Understanding drift is thus paramount, and drift localization -- determining which samples are affected by the drift -- is essential. While several approaches exist, most rely on local testing schemes, which tend to fail in high-dimensional, low-signal settings. In this work, we consider a fundamentally different approach based on conformal predictions. We discuss and show the shortcomings of common approaches and demonstrate the performance of our approach on state-of-the-art image datasets.
Challenges, Methods, Data -- a Survey of Machine Learning in Water Distribution Networks
Oct 16, 2024Research on methods for planning and controlling water distribution networks gains increasing relevance as the availability of drinking water will decrease as a consequence of climate change. So far, the majority of approaches is based on hydraulics and engineering expertise. However, with the increasing availability of sensors, machine learning techniques constitute a promising tool. This work presents the main tasks in water distribution networks, discusses how they relate to machine learning and analyses how the particularities of the domain pose challenges to and can be leveraged by machine learning approaches. Besides, it provides a technical toolkit by presenting evaluation benchmarks and a structured survey of the exemplary task of leakage detection and localization.
FairGLVQ: Fairness in Partition-Based Classification
Oct 16, 2024Fairness is an important objective throughout society. From the distribution of limited goods such as education, over hiring and payment, to taxes, legislation, and jurisprudence. Due to the increasing importance of machine learning approaches in all areas of daily life including those related to health, security, and equity, an increasing amount of research focuses on fair machine learning. In this work, we focus on the fairness of partition- and prototype-based models. The contribution of this work is twofold: 1) we develop a general framework for fair machine learning of partition-based models that does not depend on a specific fairness definition, and 2) we derive a fair version of learning vector quantization (LVQ) as a specific instantiation. We compare the resulting algorithm against other algorithms from the literature on theoretical and real-world data showing its practical relevance.
Model Based Explanations of Concept Drift
Mar 16, 2023The notion of concept drift refers to the phenomenon that the distribution generating the observed data changes over time. If drift is present, machine learning models can become inaccurate and need adjustment. While there do exist methods to detect concept drift or to adjust models in the presence of observed drift, the question of explaining drift, i.e., describing the potentially complex and high dimensional change of distribution in a human-understandable fashion, has hardly been considered so far. This problem is of importance since it enables an inspection of the most prominent characteristics of how and where drift manifests itself. Hence, it enables human understanding of the change and it increases acceptance of life-long learning models. In this paper, we present a novel technology characterizing concept drift in terms of the characteristic change of spatial features based on various explanation techniques. To do so, we propose a methodology to reduce the explanation of concept drift to an explanation of models that are trained in a suitable way extracting relevant information regarding the drift. This way a large variety of explanation schemes is available. Thus, a suitable method can be selected for the problem of drift explanation at hand. We outline the potential of this approach and demonstrate its usefulness in several examples.
Combining self-labeling and demand based active learning for non-stationary data streams
Feb 08, 2023



Learning from non-stationary data streams is a research direction that gains increasing interest as more data in form of streams becomes available, for example from social media, smartphones, or industrial process monitoring. Most approaches assume that the ground truth of the samples becomes available (possibly with some delay) and perform supervised online learning in the test-then-train scheme. While this assumption might be valid in some scenarios, it does not apply to all settings. In this work, we focus on scarcely labeled data streams and explore the potential of self-labeling in gradually drifting data streams. We formalize this setup and propose a novel online $k$-nn classifier that combines self-labeling and demand-based active learning.
On the Change of Decision Boundaries and Loss in Learning with Concept Drift
Dec 02, 2022The notion of concept drift refers to the phenomenon that the distribution generating the observed data changes over time. If drift is present, machine learning models may become inaccurate and need adjustment. Many technologies for learning with drift rely on the interleaved test-train error (ITTE) as a quantity which approximates the model generalization error and triggers drift detection and model updates. In this work, we investigate in how far this procedure is mathematically justified. More precisely, we relate a change of the ITTE to the presence of real drift, i.e., a changed posterior, and to a change of the training result under the assumption of optimality. We support our theoretical findings by empirical evidence for several learning algorithms, models, and datasets.
Explaining Reject Options of Learning Vector Quantization Classifiers
Feb 15, 2022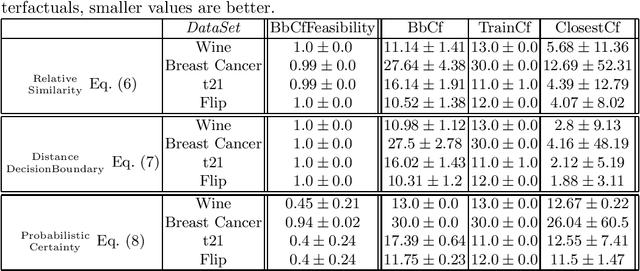
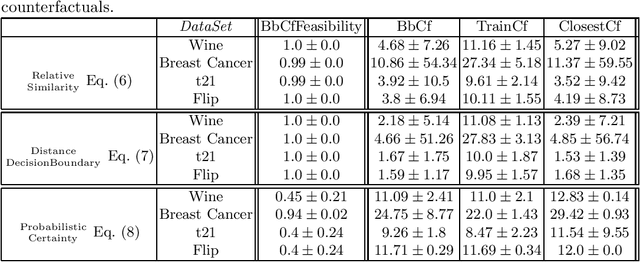
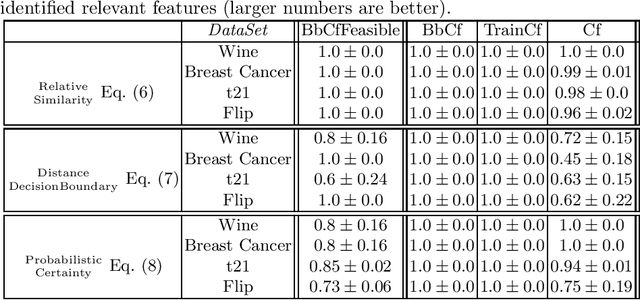

While machine learning models are usually assumed to always output a prediction, there also exist extensions in the form of reject options which allow the model to reject inputs where only a prediction with an unacceptably low certainty would be possible. With the ongoing rise of eXplainable AI, a lot of methods for explaining model predictions have been developed. However, understanding why a given input was rejected, instead of being classified by the model, is also of interest. Surprisingly, explanations of rejects have not been considered so far. We propose to use counterfactual explanations for explaining rejects and investigate how to efficiently compute counterfactual explanations of different reject options for an important class of models, namely prototype-based classifiers such as learning vector quantization models.