 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Reject Options of Learning Vector Quantization Classifiers
Paper and Code
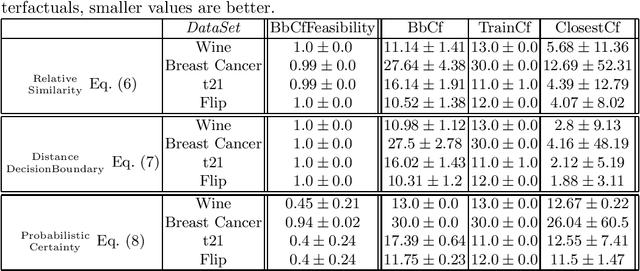
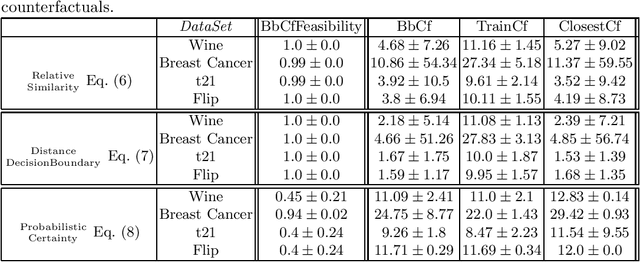
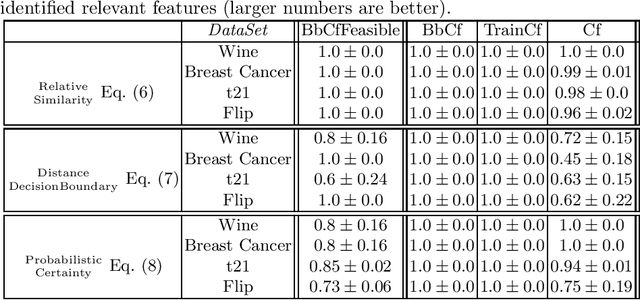

While machine learning models are usually assumed to always output a prediction, there also exist extensions in the form of reject options which allow the model to reject inputs where only a prediction with an unacceptably low certainty would be possible. With the ongoing rise of eXplainable AI, a lot of methods for explaining model predictions have been developed. However, understanding why a given input was rejected, instead of being classified by the model, is also of interest. Surprisingly, explanations of rejects have not been considered so far. We propose to use counterfactual explanations for explaining rejects and investigate how to efficiently compute counterfactual explanations of different reject options for an important class of models, namely prototype-based classifiers such as learning vector quantization models.