 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift Localization using Conformal Predictions
Feb 23, 2026Concept drift -- the change of the distribution over time -- poses significant challenges for learning systems and is of central interest for monitoring. Understanding drift is thus paramount, and drift localization -- determining which samples are affected by the drift -- is essential. While several approaches exist, most rely on local testing schemes, which tend to fail in high-dimensional, low-signal settings. In this work, we consider a fundamentally different approach based on conformal predictions. We discuss and show the shortcomings of common approaches and demonstrate the performance of our approach on state-of-the-art image datasets.
Conceptualizing Uncertainty
Mar 05, 2025Uncertainty in machine learning refers to the degree of confidence or lack thereof in a model's predictions. While uncertainty quantification methods exist, explanations of uncertainty, especially in high-dimensional settings, remain an open challenge. Existing work focuses on feature attribution approaches which are restricted to local explanations. Understanding uncertainty, its origins, and characteristics on a global scale is crucial for enhancing interpretability and trust in a model's predictions. In this work, we propose to explain the uncertainty in high-dimensional data classification settings by means of concept activation vectors which give rise to local and global explanations of uncertainty. We demonstrate the utility of the generated explanations by leveraging them to refine and improve our model.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
An Algorithm-Centered Approach To Model Streaming Data
Dec 12, 2024Besides the classical offline setup of machine learning, stream learning constitutes a well-established setup where data arrives over time in potentially non-stationary environments. Concept drift, the phenomenon that the underlying distribution changes over time poses a significant challenge. Yet, despite high practical relevance, there is little to no foundational theory for learning in the drifting setup comparable to classical statistical learning theory in the offline setting. This can be attributed to the lack of an underlying object comparable to a probability distribution as in the classical setup. While there exist approaches to transfer ideas to the streaming setup, these start from a data perspective rather than an algorithmic one. In this work, we suggest a new model of data over time that is aimed at the algorithm's perspective. Instead of defining the setup using time points, we utilize a window-based approach that resembles the inner workings of most stream learning algorithms. We compare our framework to others from the literature on a theoretical basis, showing that in many cases both model the same situation. Furthermore, we perform a numerical evaluation and showcase an application in the domain of critical infrastructure.
Adversarial Attacks for Drift Detection
Nov 25, 2024

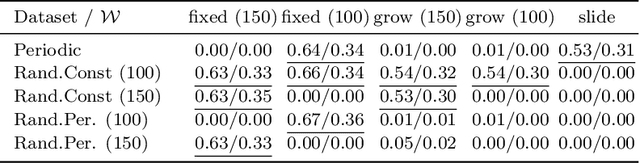
Concept drift refers to the change of data distributions over time. While drift poses a challenge for learning models, requiring their continual adaption, it is also relevant in system monitoring to detect malfunctions, system failures, and unexpected behavior. In the latter case, the robust and reliable detection of drifts is imperative. This work studies the shortcomings of commonly used drift detection schemes. We show how to construct data streams that are drifting without being detected. We refer to those as drift adversarials. In particular, we compute all possible adversairals for common detection schemes and underpin our theoretical findings with empirical evaluations.
Challenges, Methods, Data -- a Survey of Machine Learning in Water Distribution Networks
Oct 16, 2024Research on methods for planning and controlling water distribution networks gains increasing relevance as the availability of drinking water will decrease as a consequence of climate change. So far, the majority of approaches is based on hydraulics and engineering expertise. However, with the increasing availability of sensors, machine learning techniques constitute a promising tool. This work presents the main tasks in water distribution networks, discusses how they relate to machine learning and analyses how the particularities of the domain pose challenges to and can be leveraged by machine learning approaches. Besides, it provides a technical toolkit by presenting evaluation benchmarks and a structured survey of the exemplary task of leakage detection and localization.
FairGLVQ: Fairness in Partition-Based Classification
Oct 16, 2024Fairness is an important objective throughout society. From the distribution of limited goods such as education, over hiring and payment, to taxes, legislation, and jurisprudence. Due to the increasing importance of machine learning approaches in all areas of daily life including those related to health, security, and equity, an increasing amount of research focuses on fair machine learning. In this work, we focus on the fairness of partition- and prototype-based models. The contribution of this work is twofold: 1) we develop a general framework for fair machine learning of partition-based models that does not depend on a specific fairness definition, and 2) we derive a fair version of learning vector quantization (LVQ) as a specific instantiation. We compare the resulting algorithm against other algorithms from the literature on theoretical and real-world data showing its practical relevance.
Semantic Properties of cosine based bias scores for word embeddings
Jan 27, 2024Plenty of works have brought social biases in language models to attention and proposed methods to detect such biases. As a result, the literature contains a great deal of different bias tests and scores, each introduced with the premise to uncover yet more biases that other scores fail to detect. What severely lacks in the literature, however, are comparative studies that analyse such bias scores and help researchers to understand the benefits or limitations of the existing methods. In this work, we aim to close this gap for cosine based bias scores. By building on a geometric definition of bias, we propose requirements for bias scores to be considered meaningful for quantifying biases. Furthermore, we formally analyze cosine based scores from the literature with regard to these requirements. We underline these findings with experiments to show that the bias scores' limitations have an impact in the application case.
Investigating the Suitability of Concept Drift Detection for Detecting Leakages in Water Distribution Networks
Jan 03, 2024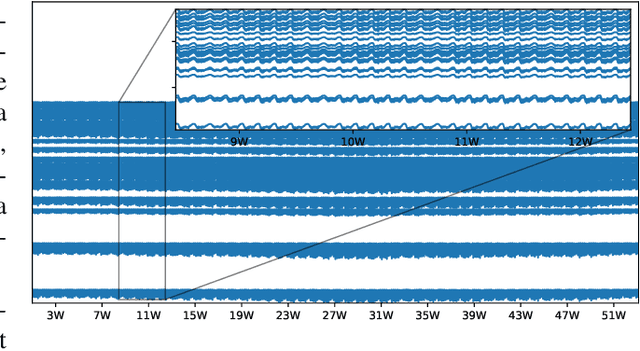
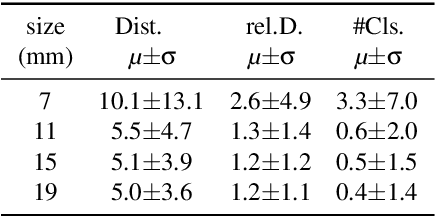
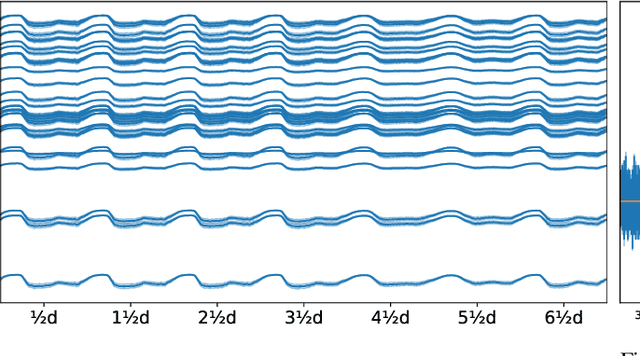
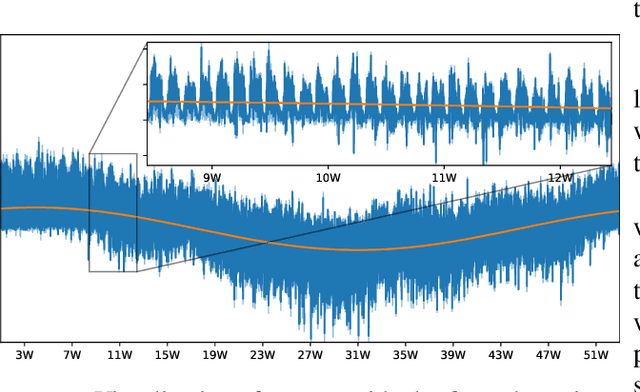
Leakages are a major risk in water distribution networks as they cause water loss and increase contamination risks. Leakage detection is a difficult task due to the complex dynamics of water distribution networks. In particular, small leakages are hard to detect. From a machine-learning perspective, leakages can be modeled as concept drift. Thus, a wide variety of drift detection schemes seems to be a suitable choice for detecting leakages. In this work, we explore the potential of model-loss-based and distribution-based drift detection methods to tackle leakage detection. We additionally discuss the issue of temporal dependencies in the data and propose a way to cope with it when applying distribution-based detection. We evaluate different methods systematically for leakages of different sizes and detection times. Additionally, we propose a first drift-detection-based technique for localizing leakages.
A Remark on Concept Drift for Dependent Data
Dec 15, 2023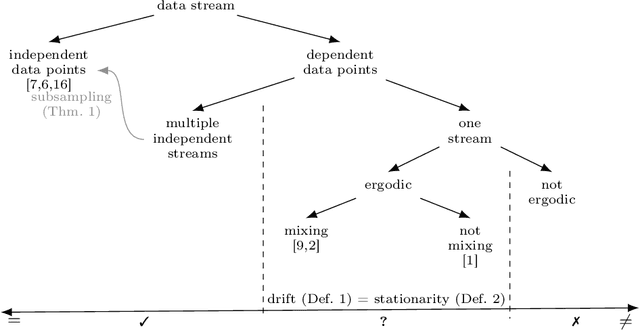
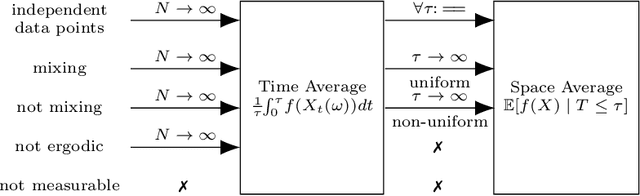
Concept drift, i.e., the change of the data generating distribution, can render machine learning models inaccurate. Several works address the phenomenon of concept drift in the streaming context usually assuming that consecutive data points are independent of each other. To generalize to dependent data, many authors link the notion of concept drift to time series. In this work, we show that the temporal dependencies are strongly influencing the sampling process. Thus, the used definitions need major modifications. In particular, we show that the notion of stationarity is not suited for this setup and discuss alternatives. We demonstrate that these alternative formal notions describe the observable learning behavior in numerical experiments.