 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Robust One-Class Intrusion Detection on Dynamic Graphs
Aug 19, 2025In the domain of network intrusion detection, robustness against contaminated and noisy data inputs remains a critical challenge. This study introduces a probabilistic version of the Temporal Graph Network Support Vector Data Description (TGN-SVDD) model, designed to enhance detection accuracy in the presence of input noise. By predicting parameters of a Gaussian distribution for each network event, our model is able to naturally address noisy adversarials and improve robustness compared to a baseline model. Our experiments on a modified CIC-IDS2017 data set with synthetic noise demonstrate significant improvements in detection performance compared to the baseline TGN-SVDD model, especially as noise levels increase.
Conceptualizing Uncertainty
Mar 05, 2025Uncertainty in machine learning refers to the degree of confidence or lack thereof in a model's predictions. While uncertainty quantification methods exist, explanations of uncertainty, especially in high-dimensional settings, remain an open challenge. Existing work focuses on feature attribution approaches which are restricted to local explanations. Understanding uncertainty, its origins, and characteristics on a global scale is crucial for enhancing interpretability and trust in a model's predictions. In this work, we propose to explain the uncertainty in high-dimensional data classification settings by means of concept activation vectors which give rise to local and global explanations of uncertainty. We demonstrate the utility of the generated explanations by leveraging them to refine and improve our model.
Intelligent Learning Rate Distribution to reduce Catastrophic Forgetting in Transformers
Mar 27, 2024Pretraining language models on large text corpora is a common practice in natural language processing. Fine-tuning of these models is then performed to achieve the best results on a variety of tasks. In this paper, we investigate the problem of catastrophic forgetting in transformer neural networks and question the common practice of fine-tuning with a flat learning rate for the entire network in this context. We perform a hyperparameter optimization process to find learning rate distributions that are better than a flat learning rate. We combine the learning rate distributions thus found and show that they generalize to better performance with respect to the problem of catastrophic forgetting. We validate these learning rate distributions with a variety of NLP benchmarks from the GLUE dataset.
Debiasing Sentence Embedders through Contrastive Word Pairs
Mar 27, 2024Over the last years, various sentence embedders have been an integral part in the success of current machine learning approaches to Natural Language Processing (NLP). Unfortunately, multiple sources have shown that the bias, inherent in the datasets upon which these embedding methods are trained, is learned by them. A variety of different approaches to remove biases in embeddings exists in the literature. Most of these approaches are applicable to word embeddings and in fewer cases to sentence embeddings. It is problematic that most debiasing approaches are directly transferred from word embeddings, therefore these approaches fail to take into account the nonlinear nature of sentence embedders and the embeddings they produce. It has been shown in literature that bias information is still present if sentence embeddings are debiased using such methods. In this contribution, we explore an approach to remove linear and nonlinear bias information for NLP solutions, without impacting downstream performance. We compare our approach to common debiasing methods on classical bias metrics and on bias metrics which take nonlinear information into account.
Targeted Visualization of the Backbone of Encoder LLMs
Mar 26, 2024Attention based Large Language Models (LLMs) are the state-of-the-art in natural language processing (NLP). The two most common architectures are encoders such as BERT, and decoders like the GPT models. Despite the success of encoder models, on which we focus in this work, they also bear several risks, including issues with bias or their susceptibility for adversarial attacks, signifying the necessity for explainable AI to detect such issues. While there does exist various local explainability methods focusing on the prediction of single inputs, global methods based on dimensionality reduction for classification inspection, which have emerged in other domains and that go further than just using t-SNE in the embedding space, are not widely spread in NLP. To reduce this gap, we investigate the application of DeepView, a method for visualizing a part of the decision function together with a data set in two dimensions, to the NLP domain. While in previous work, DeepView has been used to inspect deep image classification models, we demonstrate how to apply it to BERT-based NLP classifiers and investigate its usability in this domain, including settings with adversarially perturbed input samples and pre-trained, fine-tuned, and multi-task models.
Semantic Properties of cosine based bias scores for word embeddings
Jan 27, 2024Plenty of works have brought social biases in language models to attention and proposed methods to detect such biases. As a result, the literature contains a great deal of different bias tests and scores, each introduced with the premise to uncover yet more biases that other scores fail to detect. What severely lacks in the literature, however, are comparative studies that analyse such bias scores and help researchers to understand the benefits or limitations of the existing methods. In this work, we aim to close this gap for cosine based bias scores. By building on a geometric definition of bias, we propose requirements for bias scores to be considered meaningful for quantifying biases. Furthermore, we formally analyze cosine based scores from the literature with regard to these requirements. We underline these findings with experiments to show that the bias scores' limitations have an impact in the application case.
"Why Here and Not There?" -- Diverse Contrasting Explanations of Dimensionality Reduction
Jun 15, 2022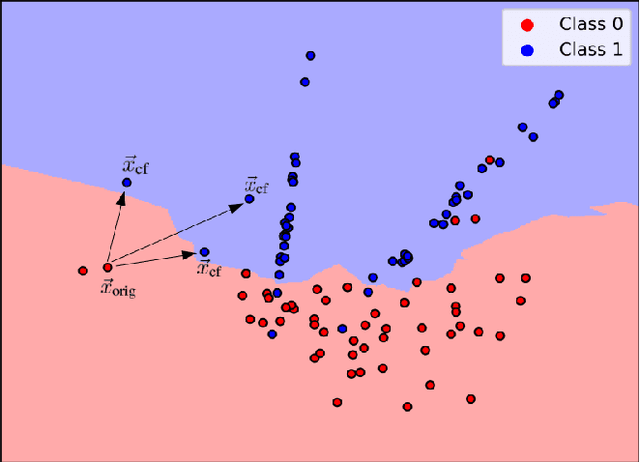
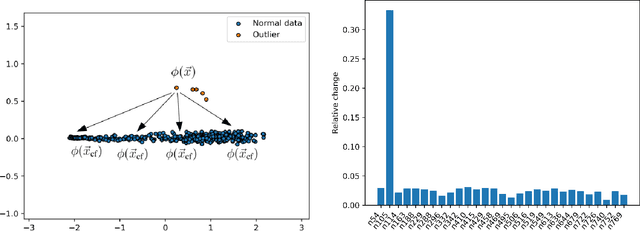
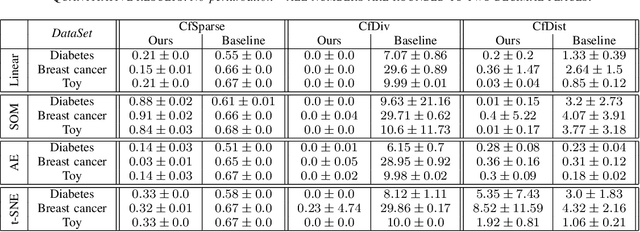
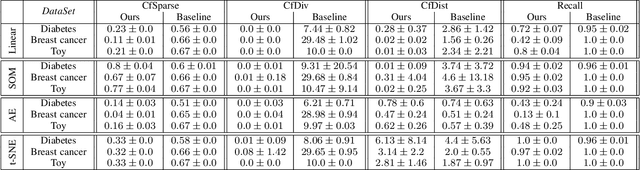
Dimensionality reduction is a popular preprocessing and a widely used tool in data mining. Transparency, which is usually achieved by means of explanations, is nowadays a widely accepted and crucial requirement of machine learning based systems like classifiers and recommender systems. However, transparency of dimensionality reduction and other data mining tools have not been considered much yet, still it is crucial to understand their behavior -- in particular practitioners might want to understand why a specific sample got mapped to a specific location. In order to (locally) understand the behavior of a given dimensionality reduction method, we introduce the abstract concept of contrasting explanations for dimensionality reduction, and apply a realization of this concept to the specific application of explaining two dimensional data visualization.
The SAME score: Improved cosine based bias score for word embeddings
Mar 28, 2022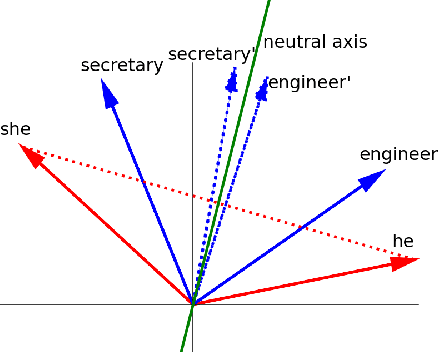

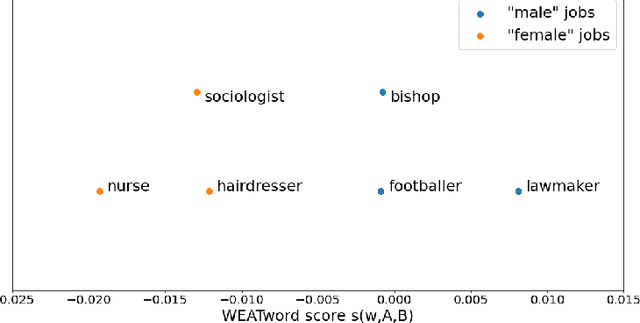
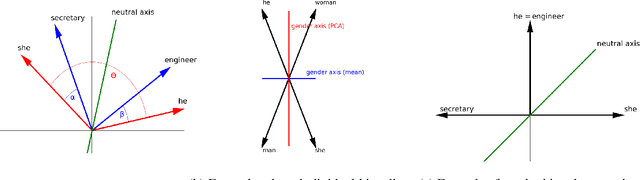
Over the last years, word and sentence embeddings have established as text preprocessing for all kinds of NLP tasks and improved performances in these tasks significantly. Unfortunately, it has also been shown that these embeddings inherit various kinds of biases from the training data and thereby pass on biases present in society to NLP solutions. Many papers attempted to quantify bias in word or sentence embeddings to evaluate debiasing methods or compare different embedding models, often with cosine-based scores. However, some works have raised doubts about these scores showing that even though they report low biases, biases persist and can be shown with other tests. In fact, there is a great variety of bias scores or tests proposed in the literature without any consensus on the optimal solutions. We lack works that study the behavior of bias scores and elaborate their advantages and disadvantages. In this work, we will explore different cosine-based bias scores. We provide a bias definition based on the ideas from the literature and derive novel requirements for bias scores. Furthermore, we thoroughly investigate the existing cosine-based scores and their limitations in order to show why these scores fail to report biases in some situations. Finally, we propose a new bias score, SAME, to address the shortcomings of existing bias scores and show empirically that SAME is better suited to quantify biases in word embeddings.
BERT WEAVER: Using WEight AVERaging to Enable Lifelong Learning for Transformer-based Models
Feb 21, 2022
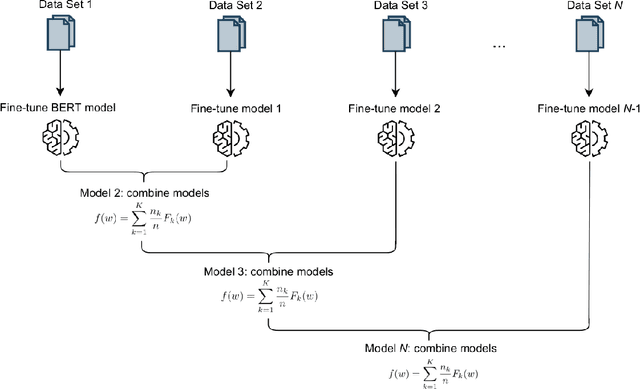

Recent developments in transfer learning have boosted the advancements in natural language processing tasks. The performance is, however, dependent on high-quality, manually annotated training data. Especially in the biomedical domain, it has been shown that one training corpus is not enough to learn generic models that are able to efficiently predict on new data. Therefore, state-of-the-art models need the ability of lifelong learning in order to improve performance as soon as new data are available - without the need of retraining the whole model from scratch. We present WEAVER, a simple, yet efficient post-processing method that infuses old knowledge into the new model, thereby reducing catastrophic forgetting. We show that applying WEAVER in a sequential manner results in similar word embedding distributions as doing a combined training on all data at once, while being computationally more efficient. Because there is no need of data sharing, the presented method is also easily applicable to federated learning settings and can for example be beneficial for the mining of electronic health records from different clinics.
Evaluating Metrics for Bias in Word Embeddings
Nov 15, 2021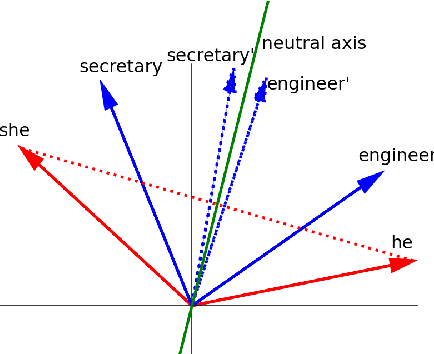

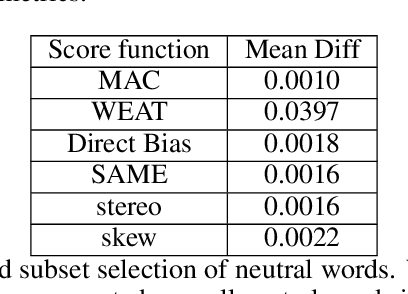
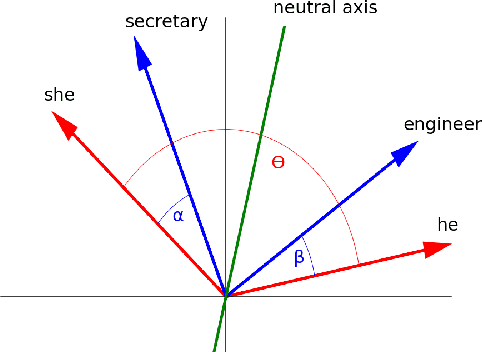
Over the last years, word and sentence embeddings have established as text preprocessing for all kinds of NLP tasks and improved the performances significantly. Unfortunately, it has also been shown that these embeddings inherit various kinds of biases from the training data and thereby pass on biases present in society to NLP solutions. Many papers attempted to quantify bias in word or sentence embeddings to evaluate debiasing methods or compare different embedding models, usually with cosine-based metrics. However, lately some works have raised doubts about these metrics showing that even though such metrics report low biases, other tests still show biases. In fact, there is a great variety of bias metrics or tests proposed in the literature without any consensus on the optimal solutions. Yet we lack works that evaluate bias metrics on a theoretical level or elaborate the advantages and disadvantages of different bias metrics. In this work, we will explore different cosine based bias metrics. We formalize a bias definition based on the ideas from previous works and derive conditions for bias metrics. Furthermore, we thoroughly investigate the existing cosine-based metrics and their limitations to show why these metrics can fail to report biases in some cases. Finally, we propose a new metric, SAME, to address the shortcomings of existing metrics and mathematically prove that SAME behaves appropriately.