 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT WEAVER: Using WEight AVERaging to Enable Lifelong Learning for Transformer-based Models
Paper and Code

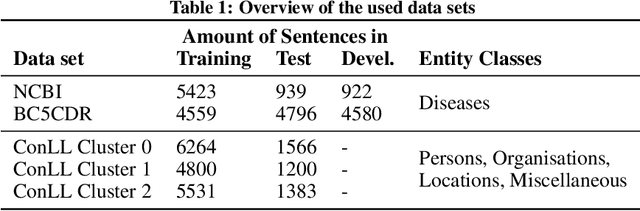
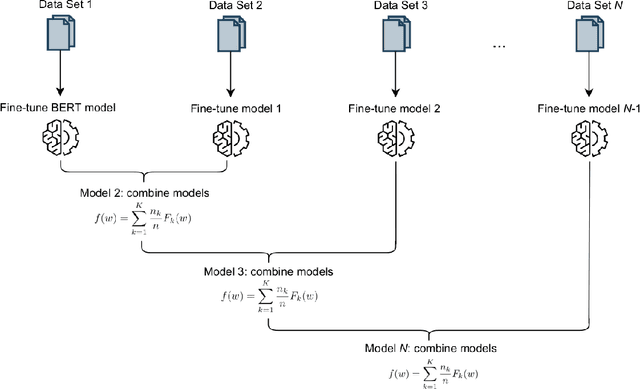

Recent developments in transfer learning have boosted the advancements in natural language processing tasks. The performance is, however, dependent on high-quality, manually annotated training data. Especially in the biomedical domain, it has been shown that one training corpus is not enough to learn generic models that are able to efficiently predict on new data. Therefore, state-of-the-art models need the ability of lifelong learning in order to improve performance as soon as new data are available - without the need of retraining the whole model from scratch. We present WEAVER, a simple, yet efficient post-processing method that infuses old knowledge into the new model, thereby reducing catastrophic forgetting. We show that applying WEAVER in a sequential manner results in similar word embedding distributions as doing a combined training on all data at once, while being computationally more efficient. Because there is no need of data sharing, the presented method is also easily applicable to federated learning settings and can for example be beneficial for the mining of electronic health records from different clinics.