 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Metrics for Bias in Word Embeddings
Paper and Code
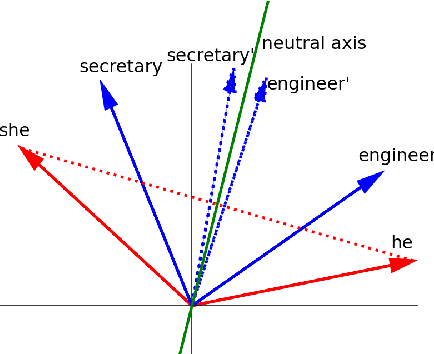

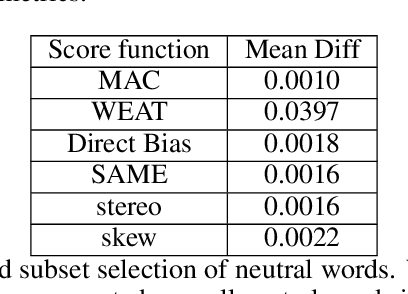
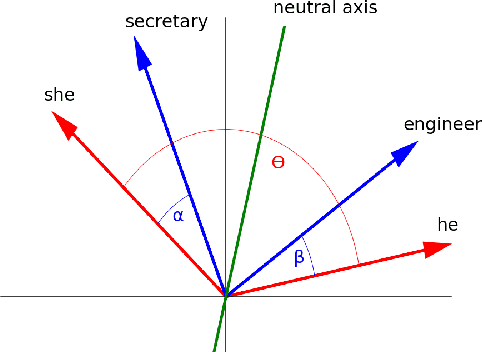
Over the last years, word and sentence embeddings have established as text preprocessing for all kinds of NLP tasks and improved the performances significantly. Unfortunately, it has also been shown that these embeddings inherit various kinds of biases from the training data and thereby pass on biases present in society to NLP solutions. Many papers attempted to quantify bias in word or sentence embeddings to evaluate debiasing methods or compare different embedding models, usually with cosine-based metrics. However, lately some works have raised doubts about these metrics showing that even though such metrics report low biases, other tests still show biases. In fact, there is a great variety of bias metrics or tests proposed in the literature without any consensus on the optimal solutions. Yet we lack works that evaluate bias metrics on a theoretical level or elaborate the advantages and disadvantages of different bias metrics. In this work, we will explore different cosine based bias metrics. We formalize a bias definition based on the ideas from previous works and derive conditions for bias metrics. Furthermore, we thoroughly investigate the existing cosine-based metrics and their limitations to show why these metrics can fail to report biases in some cases. Finally, we propose a new metric, SAME, to address the shortcomings of existing metrics and mathematically prove that SAME behaves appropriately.