 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Remaining Lifespan Prediction from Images
Jun 16, 2025



Predicting mortality-related outcomes from images offers the prospect of accessible, noninvasive, and scalable health screening. We present a method that leverages pretrained vision transformer foundation models to estimate remaining lifespan from facial and whole-body images, alongside robust uncertainty quantification. We show that predictive uncertainty varies systematically with the true remaining lifespan, and that this uncertainty can be effectively modeled by learning a Gaussian distribution for each sample. Our approach achieves state-of-the-art mean absolute error (MAE) of 7.48 years on an established Dataset, and further improves to 4.79 and 5.07 years MAE on two new, higher-quality datasets curated and published in this work. Importantly, our models provide well-calibrated uncertainty estimates, as demonstrated by a bucketed expected calibration error of 0.62 years. While not intended for clinical deployment, these results highlight the potential of extracting medically relevant signals from images. We make all code and datasets available to facilitate further research.
JEPA for RL: Investigating Joint-Embedding Predictive Architectures for Reinforcement Learning
Apr 23, 2025


Joint-Embedding Predictive Architectures (JEPA) have recently become popular as promising architectures for self-supervised learning. Vision transformers have been trained using JEPA to produce embeddings from images and videos, which have been shown to be highly suitable for downstream tasks like classification and segmentation. In this paper, we show how to adapt the JEPA architecture to reinforcement learning from images. We discuss model collapse, show how to prevent it, and provide exemplary data on the classical Cart Pole task.
No learning rates needed: Introducing SALSA -- Stable Armijo Line Search Adaptation
Jul 30, 2024In recent studies, line search methods have been demonstrated to significantly enhance the performance of conventional stochastic gradient descent techniques across various datasets and architectures, while making an otherwise critical choice of learning rate schedule superfluous. In this paper, we identify problems of current state-of-the-art of line search methods, propose enhancements, and rigorously assess their effectiveness. Furthermore, we evaluate these methods on orders of magnitude larger datasets and more complex data domains than previously done. More specifically, we enhance the Armijo line search method by speeding up its computation and incorporating a momentum term into the Armijo criterion, making it better suited for stochastic mini-batching. Our optimization approach outperforms both the previous Armijo implementation and a tuned learning rate schedule for the Adam and SGD optimizers. Our evaluation covers a diverse range of architectures, such as Transformers, CNNs, and MLPs, as well as data domains, including NLP and image data. Our work is publicly available as a Python package, which provides a simple Pytorch optimizer.
Neural Architecture Search for Sentence Classification with BERT
Mar 27, 2024
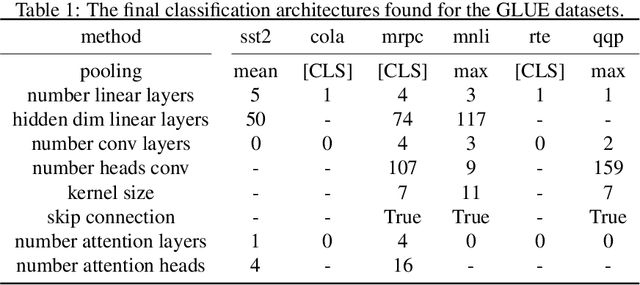


Pre training of language models on large text corpora is common practice in Natural Language Processing. Following, fine tuning of these models is performed to achieve the best results on a variety of tasks. In this paper we question the common practice of only adding a single output layer as a classification head on top of the network. We perform an AutoML search to find architectures that outperform the current single layer at only a small compute cost. We validate our classification architecture on a variety of NLP benchmarks from the GLUE dataset.
Intelligent Learning Rate Distribution to reduce Catastrophic Forgetting in Transformers
Mar 27, 2024Pretraining language models on large text corpora is a common practice in natural language processing. Fine-tuning of these models is then performed to achieve the best results on a variety of tasks. In this paper, we investigate the problem of catastrophic forgetting in transformer neural networks and question the common practice of fine-tuning with a flat learning rate for the entire network in this context. We perform a hyperparameter optimization process to find learning rate distributions that are better than a flat learning rate. We combine the learning rate distributions thus found and show that they generalize to better performance with respect to the problem of catastrophic forgetting. We validate these learning rate distributions with a variety of NLP benchmarks from the GLUE dataset.
Improving Line Search Methods for Large Scale Neural Network Training
Mar 27, 2024
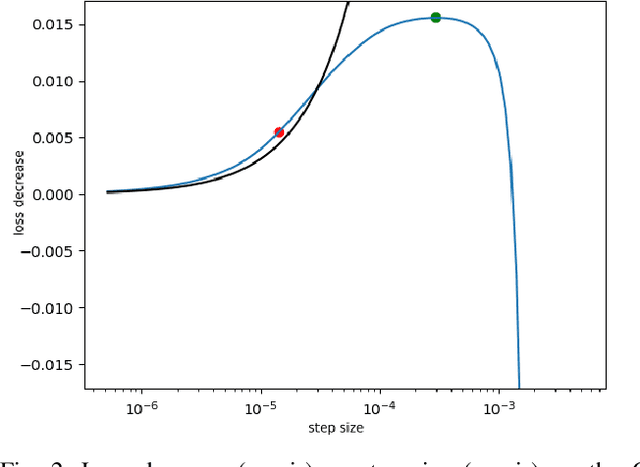
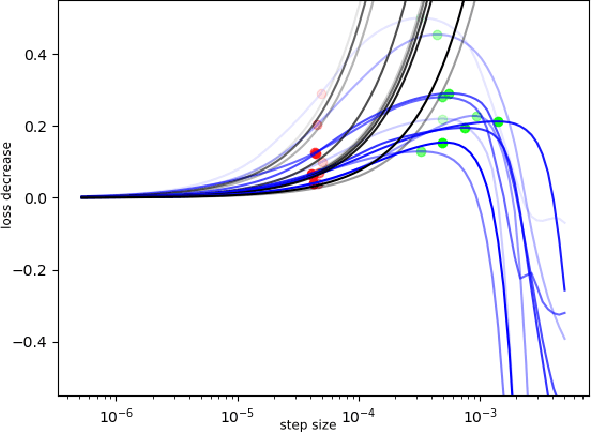
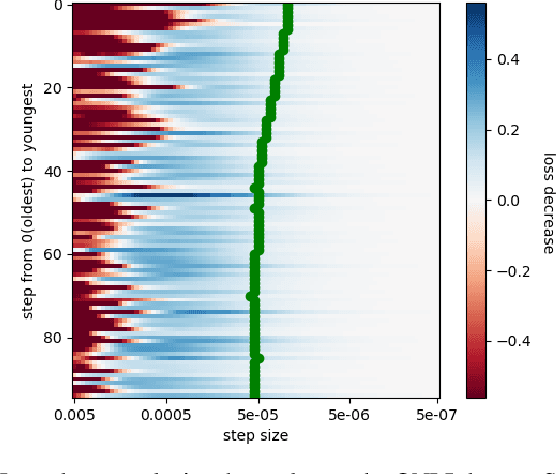
In recent studies, line search methods have shown significant improvements in the performance of traditional stochastic gradient descent techniques, eliminating the need for a specific learning rate schedule. In this paper, we identify existing issues in state-of-the-art line search methods, propose enhancements, and rigorously evaluate their effectiveness. We test these methods on larger datasets and more complex data domains than before. Specifically, we improve the Armijo line search by integrating the momentum term from ADAM in its search direction, enabling efficient large-scale training, a task that was previously prone to failure using Armijo line search methods. Our optimization approach outperforms both the previous Armijo implementation and tuned learning rate schedules for Adam. Our evaluation focuses on Transformers and CNNs in the domains of NLP and image data. Our work is publicly available as a Python package, which provides a hyperparameter free Pytorch optimizer.
Debiasing Sentence Embedders through Contrastive Word Pairs
Mar 27, 2024Over the last years, various sentence embedders have been an integral part in the success of current machine learning approaches to Natural Language Processing (NLP). Unfortunately, multiple sources have shown that the bias, inherent in the datasets upon which these embedding methods are trained, is learned by them. A variety of different approaches to remove biases in embeddings exists in the literature. Most of these approaches are applicable to word embeddings and in fewer cases to sentence embeddings. It is problematic that most debiasing approaches are directly transferred from word embeddings, therefore these approaches fail to take into account the nonlinear nature of sentence embedders and the embeddings they produce. It has been shown in literature that bias information is still present if sentence embeddings are debiased using such methods. In this contribution, we explore an approach to remove linear and nonlinear bias information for NLP solutions, without impacting downstream performance. We compare our approach to common debiasing methods on classical bias metrics and on bias metrics which take nonlinear information into account.
Faster Convergence for Transformer Fine-tuning with Line Search Methods
Mar 27, 2024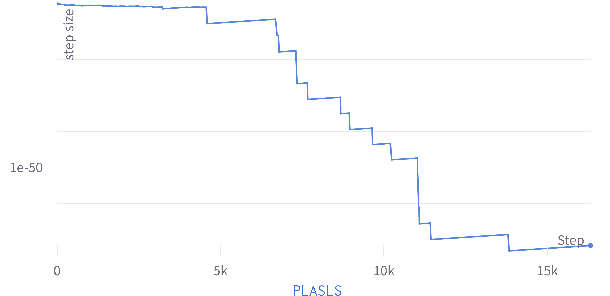
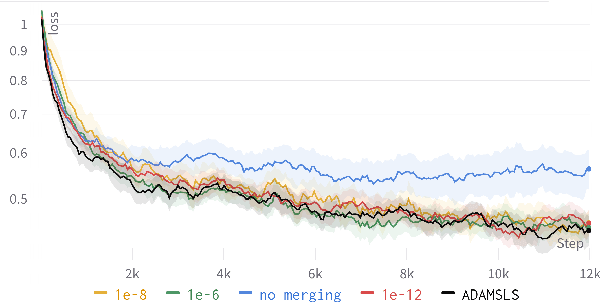
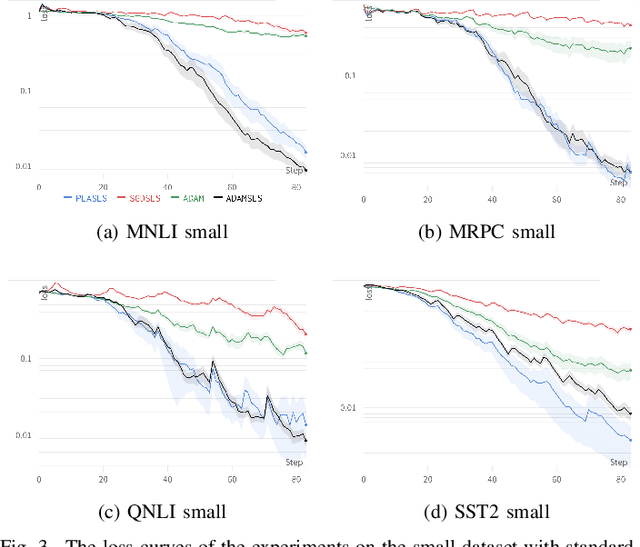
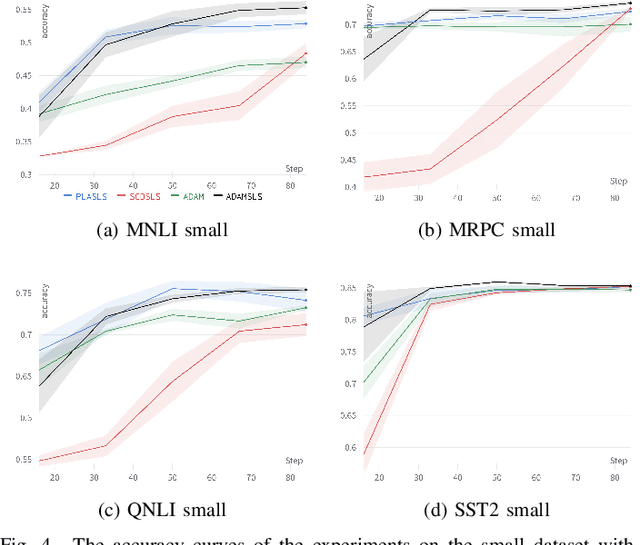
Recent works have shown that line search methods greatly increase performance of traditional stochastic gradient descent methods on a variety of datasets and architectures [1], [2]. In this work we succeed in extending line search methods to the novel and highly popular Transformer architecture and dataset domains in natural language processing. More specifically, we combine the Armijo line search with the Adam optimizer and extend it by subdividing the networks architecture into sensible units and perform the line search separately on these local units. Our optimization method outperforms the traditional Adam optimizer and achieves significant performance improvements for small data sets or small training budgets, while performing equal or better for other tested cases. Our work is publicly available as a python package, which provides a hyperparameter-free pytorch optimizer that is compatible with arbitrary network architectures.
Retrieval Augmented Generation Systems: Automatic Dataset Creation, Evaluation and Boolean Agent Setup
Feb 26, 2024



Retrieval Augmented Generation (RAG) systems have seen huge popularity in augmenting Large-Language Model (LLM) outputs with domain specific and time sensitive data. Very recently a shift is happening from simple RAG setups that query a vector database for additional information with every user input to more sophisticated forms of RAG. However, different concrete approaches compete on mostly anecdotal evidence at the moment. In this paper we present a rigorous dataset creation and evaluation workflow to quantitatively compare different RAG strategies. We use a dataset created this way for the development and evaluation of a boolean agent RAG setup: A system in which a LLM can decide whether to query a vector database or not, thus saving tokens on questions that can be answered with internal knowledge. We publish our code and generated dataset online.
Novel transfer learning schemes based on Siamese networks and synthetic data
Nov 22, 2022Transfer learning schemes based on deep networks which have been trained on huge image corpora offer state-of-the-art technologies in computer vision. Here, supervised and semi-supervised approaches constitute efficient technologies which work well with comparably small data sets. Yet, such applications are currently restricted to application domains where suitable deepnetwork models are readily available. In this contribution, we address an important application area in the domain of biotechnology, the automatic analysis of CHO-K1 suspension growth in microfluidic single-cell cultivation, where data characteristics are very dissimilar to existing domains and trained deep networks cannot easily be adapted by classical transfer learning. We propose a novel transfer learning scheme which expands a recently introduced Twin-VAE architecture, which is trained on realistic and synthetic data, and we modify its specialized training procedure to the transfer learning domain. In the specific domain, often only few to no labels exist and annotations are costly. We investigate a novel transfer learning strategy, which incorporates a simultaneous retraining on natural and synthetic data using an invariant shared representation as well as suitable target variables, while it learns to handle unseen data from a different microscopy tech nology. We show the superiority of the variation of our Twin-VAE architecture over the state-of-the-art transfer learning methodology in image processing as well as classical image processing technologies, which persists, even with strongly shortened training times and leads to satisfactory results in this domain. The source code is available at https://github.com/dstallmann/transfer_learning_twinvae, works cross-platform, is open-source and free (MIT licensed) software. We make the data sets available at https://pub.uni-bielefeld.de/record/2960030.