 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Do Not Simulate Human Psychology
Aug 13, 2025Large Language Models (LLMs),such as ChatGPT, are increasingly used in research, ranging from simple writing assistance to complex data annotation tasks. Recently, some research has suggested that LLMs may even be able to simulate human psychology and can, hence, replace human participants in psychological studies. We caution against this approach. We provide conceptual arguments against the hypothesis that LLMs simulate human psychology. We then present empiric evidence illustrating our arguments by demonstrating that slight changes to wording that correspond to large changes in meaning lead to notable discrepancies between LLMs' and human responses, even for the recent CENTAUR model that was specifically fine-tuned on psychological responses. Additionally, different LLMs show very different responses to novel items, further illustrating their lack of reliability. We conclude that LLMs do not simulate human psychology and recommend that psychological researchers should treat LLMs as useful but fundamentally unreliable tools that need to be validated against human responses for every new application.
Neural Architecture Search for Sentence Classification with BERT
Mar 27, 2024
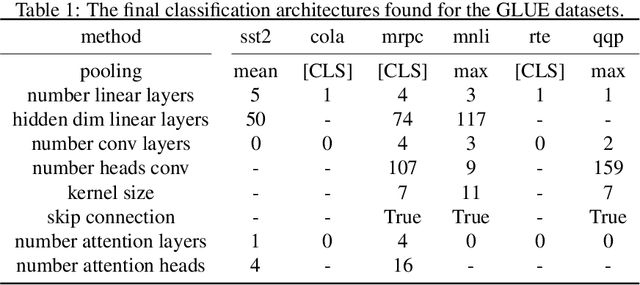


Pre training of language models on large text corpora is common practice in Natural Language Processing. Following, fine tuning of these models is performed to achieve the best results on a variety of tasks. In this paper we question the common practice of only adding a single output layer as a classification head on top of the network. We perform an AutoML search to find architectures that outperform the current single layer at only a small compute cost. We validate our classification architecture on a variety of NLP benchmarks from the GLUE dataset.
Debiasing Sentence Embedders through Contrastive Word Pairs
Mar 27, 2024Over the last years, various sentence embedders have been an integral part in the success of current machine learning approaches to Natural Language Processing (NLP). Unfortunately, multiple sources have shown that the bias, inherent in the datasets upon which these embedding methods are trained, is learned by them. A variety of different approaches to remove biases in embeddings exists in the literature. Most of these approaches are applicable to word embeddings and in fewer cases to sentence embeddings. It is problematic that most debiasing approaches are directly transferred from word embeddings, therefore these approaches fail to take into account the nonlinear nature of sentence embedders and the embeddings they produce. It has been shown in literature that bias information is still present if sentence embeddings are debiased using such methods. In this contribution, we explore an approach to remove linear and nonlinear bias information for NLP solutions, without impacting downstream performance. We compare our approach to common debiasing methods on classical bias metrics and on bias metrics which take nonlinear information into account.
Intelligent Learning Rate Distribution to reduce Catastrophic Forgetting in Transformers
Mar 27, 2024Pretraining language models on large text corpora is a common practice in natural language processing. Fine-tuning of these models is then performed to achieve the best results on a variety of tasks. In this paper, we investigate the problem of catastrophic forgetting in transformer neural networks and question the common practice of fine-tuning with a flat learning rate for the entire network in this context. We perform a hyperparameter optimization process to find learning rate distributions that are better than a flat learning rate. We combine the learning rate distributions thus found and show that they generalize to better performance with respect to the problem of catastrophic forgetting. We validate these learning rate distributions with a variety of NLP benchmarks from the GLUE dataset.
Semantic Properties of cosine based bias scores for word embeddings
Jan 27, 2024Plenty of works have brought social biases in language models to attention and proposed methods to detect such biases. As a result, the literature contains a great deal of different bias tests and scores, each introduced with the premise to uncover yet more biases that other scores fail to detect. What severely lacks in the literature, however, are comparative studies that analyse such bias scores and help researchers to understand the benefits or limitations of the existing methods. In this work, we aim to close this gap for cosine based bias scores. By building on a geometric definition of bias, we propose requirements for bias scores to be considered meaningful for quantifying biases. Furthermore, we formally analyze cosine based scores from the literature with regard to these requirements. We underline these findings with experiments to show that the bias scores' limitations have an impact in the application case.
The SAME score: Improved cosine based bias score for word embeddings
Mar 28, 2022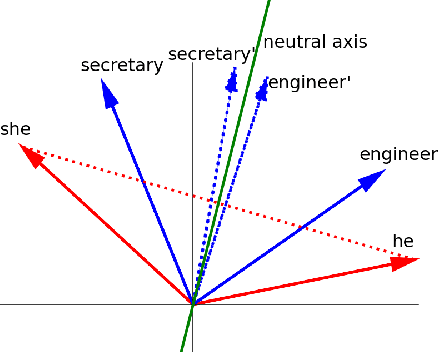

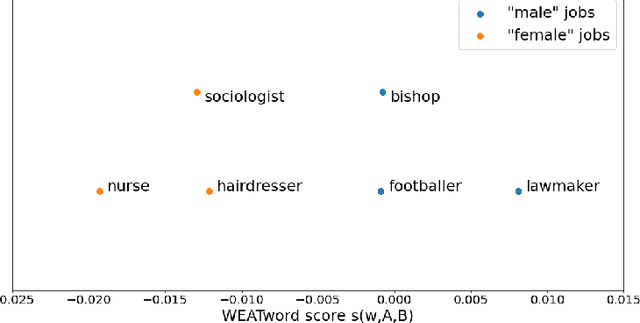
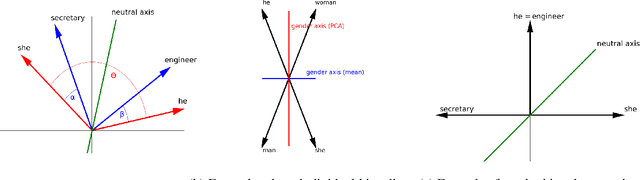
Over the last years, word and sentence embeddings have established as text preprocessing for all kinds of NLP tasks and improved performances in these tasks significantly. Unfortunately, it has also been shown that these embeddings inherit various kinds of biases from the training data and thereby pass on biases present in society to NLP solutions. Many papers attempted to quantify bias in word or sentence embeddings to evaluate debiasing methods or compare different embedding models, often with cosine-based scores. However, some works have raised doubts about these scores showing that even though they report low biases, biases persist and can be shown with other tests. In fact, there is a great variety of bias scores or tests proposed in the literature without any consensus on the optimal solutions. We lack works that study the behavior of bias scores and elaborate their advantages and disadvantages. In this work, we will explore different cosine-based bias scores. We provide a bias definition based on the ideas from the literature and derive novel requirements for bias scores. Furthermore, we thoroughly investigate the existing cosine-based scores and their limitations in order to show why these scores fail to report biases in some situations. Finally, we propose a new bias score, SAME, to address the shortcomings of existing bias scores and show empirically that SAME is better suited to quantify biases in word embeddings.
Evaluating Metrics for Bias in Word Embeddings
Nov 15, 2021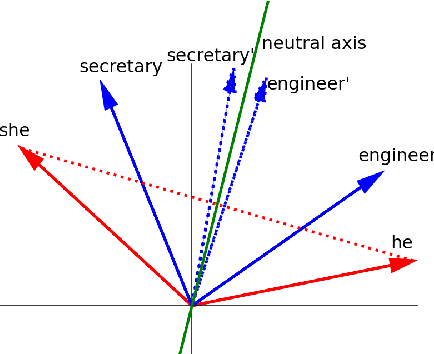

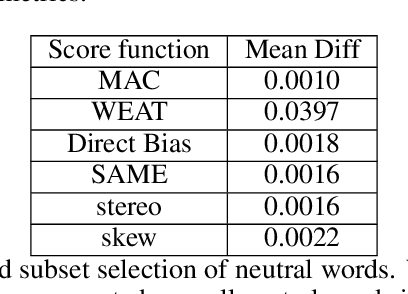
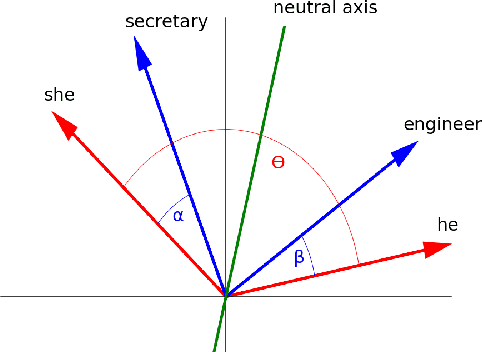
Over the last years, word and sentence embeddings have established as text preprocessing for all kinds of NLP tasks and improved the performances significantly. Unfortunately, it has also been shown that these embeddings inherit various kinds of biases from the training data and thereby pass on biases present in society to NLP solutions. Many papers attempted to quantify bias in word or sentence embeddings to evaluate debiasing methods or compare different embedding models, usually with cosine-based metrics. However, lately some works have raised doubts about these metrics showing that even though such metrics report low biases, other tests still show biases. In fact, there is a great variety of bias metrics or tests proposed in the literature without any consensus on the optimal solutions. Yet we lack works that evaluate bias metrics on a theoretical level or elaborate the advantages and disadvantages of different bias metrics. In this work, we will explore different cosine based bias metrics. We formalize a bias definition based on the ideas from previous works and derive conditions for bias metrics. Furthermore, we thoroughly investigate the existing cosine-based metrics and their limitations to show why these metrics can fail to report biases in some cases. Finally, we propose a new metric, SAME, to address the shortcomings of existing metrics and mathematically prove that SAME behaves appropriately.