 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel transfer learning schemes based on Siamese networks and synthetic data
Nov 22, 2022Transfer learning schemes based on deep networks which have been trained on huge image corpora offer state-of-the-art technologies in computer vision. Here, supervised and semi-supervised approaches constitute efficient technologies which work well with comparably small data sets. Yet, such applications are currently restricted to application domains where suitable deepnetwork models are readily available. In this contribution, we address an important application area in the domain of biotechnology, the automatic analysis of CHO-K1 suspension growth in microfluidic single-cell cultivation, where data characteristics are very dissimilar to existing domains and trained deep networks cannot easily be adapted by classical transfer learning. We propose a novel transfer learning scheme which expands a recently introduced Twin-VAE architecture, which is trained on realistic and synthetic data, and we modify its specialized training procedure to the transfer learning domain. In the specific domain, often only few to no labels exist and annotations are costly. We investigate a novel transfer learning strategy, which incorporates a simultaneous retraining on natural and synthetic data using an invariant shared representation as well as suitable target variables, while it learns to handle unseen data from a different microscopy tech nology. We show the superiority of the variation of our Twin-VAE architecture over the state-of-the-art transfer learning methodology in image processing as well as classical image processing technologies, which persists, even with strongly shortened training times and leads to satisfactory results in this domain. The source code is available at https://github.com/dstallmann/transfer_learning_twinvae, works cross-platform, is open-source and free (MIT licensed) software. We make the data sets available at https://pub.uni-bielefeld.de/record/2960030.
Towards an Automatic Analysis of CHO-K1 Suspension Growth in Microfluidic Single-cell Cultivation
Oct 20, 2020

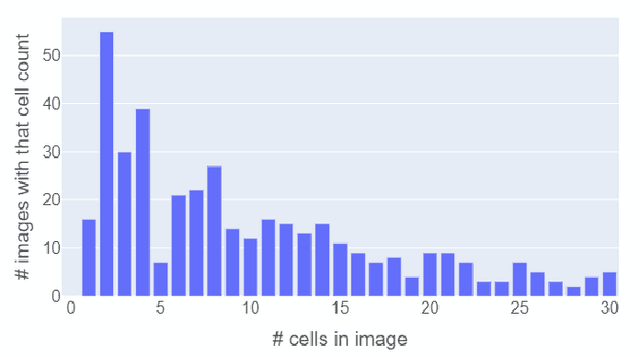

Motivation: Innovative microfluidic systems carry the promise to greatly facilitate spatio-temporal analysis of single cells under well-defined environmental conditions, allowing novel insights into population heterogeneity and opening new opportunities for fundamental and applied biotechnology. Microfluidics experiments, however, are accompanied by vast amounts of data, such as time series of microscopic images, for which manual evaluation is infeasible due to the sheer number of samples. While classical image processing technologies do not lead to satisfactory results in this domain, modern deep learning technologies such as convolutional networks can be sufficiently versatile for diverse tasks, including automatic cell tracking and counting as well as the extraction of critical parameters, such as growth rate. However, for successful training, current supervised deep learning requires label information, such as the number or positions of cells for each image in a series; obtaining these annotations is very costly in this setting. Results: We propose a novel Machine Learning architecture together with a specialized training procedure, which allows us to infuse a deep neural network with human-powered abstraction on the level of data, leading to a high-performing regression model that requires only a very small amount of labeled data. Specifically, we train a generative model simultaneously on natural and synthetic data, so that it learns a shared representation, from which a target variable, such as the cell count, can be reliably estimated.