 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning Should Move Beyond Incremental Classification
Feb 17, 2025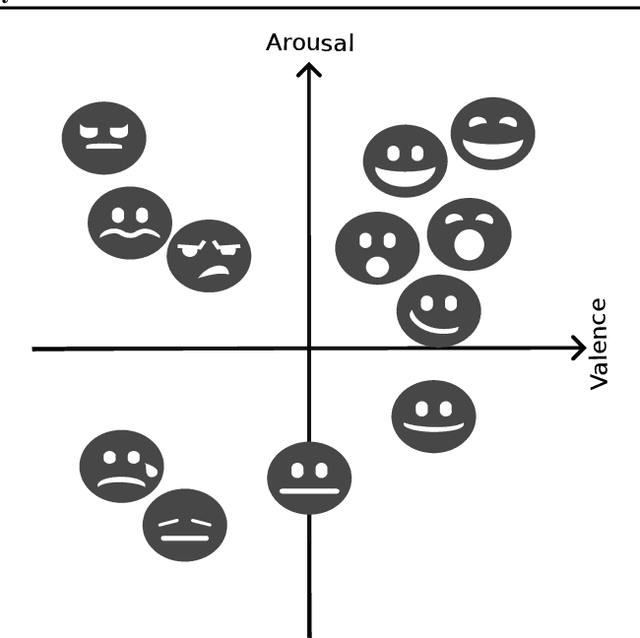


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
Where is the Truth? The Risk of Getting Confounded in a Continual World
Feb 09, 2024A dataset is confounded if it is most easily solved via a spurious correlation which fails to generalize to new data. We will show that, in a continual learning setting where confounders may vary in time across tasks, the resulting challenge far exceeds the standard forgetting problem normally considered. In particular, we derive mathematically the effect of such confounders on the space of valid joint solutions to sets of confounded tasks. Interestingly, our theory predicts that for many such continual datasets, spurious correlations are easily ignored when the tasks are trained on jointly, but it is far harder to avoid confounding when they are considered sequentially. We construct such a dataset and demonstrate empirically that standard continual learning methods fail to ignore confounders, while training jointly on all tasks is successful. Our continually confounded dataset, ConCon, is based on CLEVR images and demonstrates the need for continual learning methods with more robust behavior with respect to confounding.
BOWLL: A Deceptively Simple Open World Lifelong Learner
Feb 07, 2024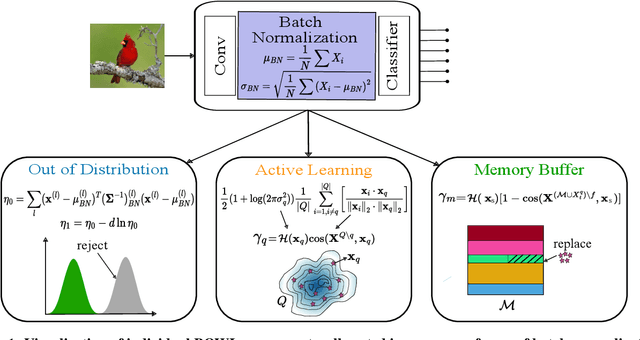
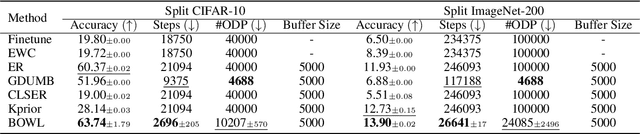
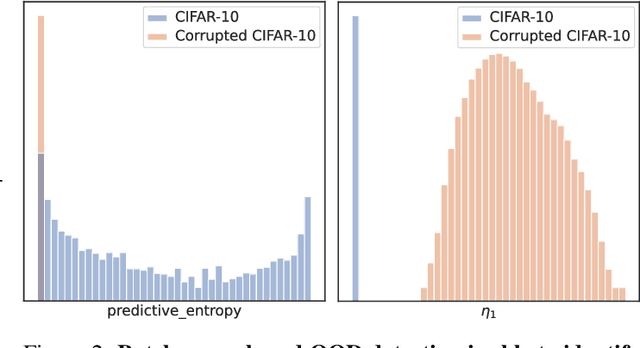
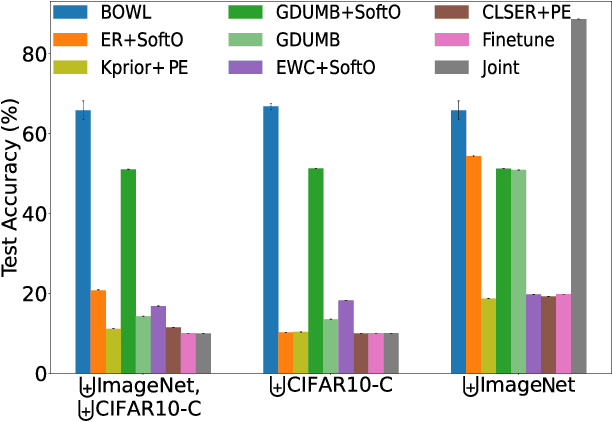
The quest to improve scalar performance numbers on predetermined benchmarks seems to be deeply engraved in deep learning. However, the real world is seldom carefully curated and applications are seldom limited to excelling on test sets. A practical system is generally required to recognize novel concepts, refrain from actively including uninformative data, and retain previously acquired knowledge throughout its lifetime. Despite these key elements being rigorously researched individually, the study of their conjunction, open world lifelong learning, is only a recent trend. To accelerate this multifaceted field's exploration, we introduce its first monolithic and much-needed baseline. Leveraging the ubiquitous use of batch normalization across deep neural networks, we propose a deceptively simple yet highly effective way to repurpose standard models for open world lifelong learning. Through extensive empirical evaluation, we highlight why our approach should serve as a future standard for models that are able to effectively maintain their knowledge, selectively focus on informative data, and accelerate future learning.
Self Expanding Neural Networks
Jul 11, 2023



The results of training a neural network are heavily dependent on the architecture chosen; and even a modification of only the size of the network, however small, typically involves restarting the training process. In contrast to this, we begin training with a small architecture, only increase its capacity as necessary for the problem, and avoid interfering with previous optimization while doing so. We thereby introduce a natural gradient based approach which intuitively expands both the width and depth of a neural network when this is likely to substantially reduce the hypothetical converged training loss. We prove an upper bound on the "rate" at which neurons are added, and a computationally cheap lower bound on the expansion score. We illustrate the benefits of such Self-Expanding Neural Networks in both classification and regression problems, including those where the appropriate architecture size is substantially uncertain a priori.
Gaussian Process Based Message Filtering for Robust Multi-Agent Cooperation in the Presence of Adversarial Communication
Dec 01, 2020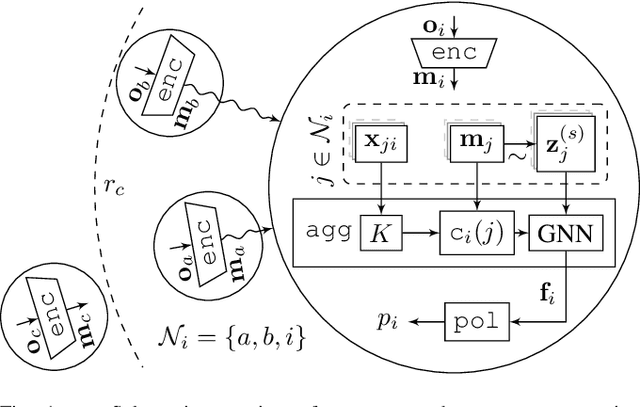

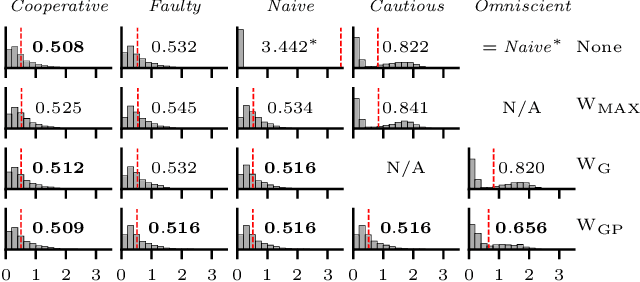

In this paper, we consider the problem of providing robustness to adversarial communication in multi-agent systems. Specifically, we propose a solution towards robust cooperation, which enables the multi-agent system to maintain high performance in the presence of anonymous non-cooperative agents that communicate faulty, misleading or manipulative information. In pursuit of this goal, we propose a communication architecture based on Graph Neural Networks (GNNs), which is amenable to a novel Gaussian Process (GP)-based probabilistic model characterizing the mutual information between the simultaneous communications of different agents due to their physical proximity and relative position. This model allows agents to locally compute approximate posterior probabilities, or confidences, that any given one of their communication partners is being truthful. These confidences can be used as weights in a message filtering scheme, thereby suppressing the influence of suspicious communication on the receiving agent's decisions. In order to assess the efficacy of our method, we introduce a taxonomy of non-cooperative agents, which distinguishes them by the amount of information available to them. We demonstrate in two distinct experiments that our method performs well across this taxonomy, outperforming alternative methods. For all but the best informed adversaries, our filtering method is able to reduce the impact that non-cooperative agents cause, reducing it to the point of negligibility, and with negligible cost to performance in the absence of adversaries.
Multi-Vehicle Mixed-Reality Reinforcement Learning for Autonomous Multi-Lane Driving
Nov 26, 2019
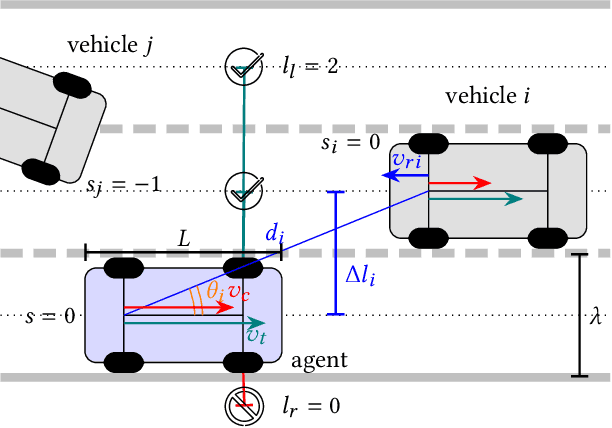

Autonomous driving promises to transform road transport. Multi-vehicle and multi-lane scenarios, however, present unique challenges due to constrained navigation and unpredictable vehicle interactions. Learning-based methods---such as deep reinforcement learning---are emerging as a promising approach to automatically design intelligent driving policies that can cope with these challenges. Yet, the process of safely learning multi-vehicle driving behaviours is hard: while collisions---and their near-avoidance---are essential to the learning process, directly executing immature policies on autonomous vehicles raises considerable safety concerns. In this article, we present a safe and efficient framework that enables the learning of driving policies for autonomous vehicles operating in a shared workspace, where the absence of collisions cannot be guaranteed. Key to our learning procedure is a sim2real approach that uses real-world online policy adaptation in a mixed-reality setup, where other vehicles and static obstacles exist in the virtual domain. This allows us to perform safe learning by simulating (and learning from) collisions between the learning agent(s) and other objects in virtual reality. Our results demonstrate that, after only a few runs in mixed-reality, collisions are significantly reduced.