 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHRONOBERG: Capturing Language Evolution and Temporal Awareness in Foundation Models
Sep 26, 2025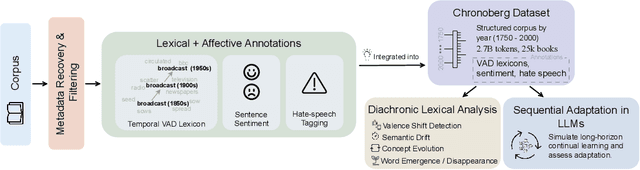



Large language models (LLMs) excel at operating at scale by leveraging social media and various data crawled from the web. Whereas existing corpora are diverse, their frequent lack of long-term temporal structure may however limit an LLM's ability to contextualize semantic and normative evolution of language and to capture diachronic variation. To support analysis and training for the latter, we introduce CHRONOBERG, a temporally structured corpus of English book texts spanning 250 years, curated from Project Gutenberg and enriched with a variety of temporal annotations. First, the edited nature of books enables us to quantify lexical semantic change through time-sensitive Valence-Arousal-Dominance (VAD) analysis and to construct historically calibrated affective lexicons to support temporally grounded interpretation. With the lexicons at hand, we demonstrate a need for modern LLM-based tools to better situate their detection of discriminatory language and contextualization of sentiment across various time-periods. In fact, we show how language models trained sequentially on CHRONOBERG struggle to encode diachronic shifts in meaning, emphasizing the need for temporally aware training and evaluation pipelines, and positioning CHRONOBERG as a scalable resource for the study of linguistic change and temporal generalization. Disclaimer: This paper includes language and display of samples that could be offensive to readers. Open Access: Chronoberg is available publicly on HuggingFace at ( https://huggingface.co/datasets/spaul25/Chronoberg). Code is available at (https://github.com/paulsubarna/Chronoberg).
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
The Cake that is Intelligence and Who Gets to Bake it: An AI Analogy and its Implications for Participation
Feb 06, 2025In a widely popular analogy by Turing Award Laureate Yann LeCun, machine intelligence has been compared to cake - where unsupervised learning forms the base, supervised learning adds the icing, and reinforcement learning is the cherry on top. We expand this 'cake that is intelligence' analogy from a simple structural metaphor to the full life-cycle of AI systems, extending it to sourcing of ingredients (data), conception of recipes (instructions), the baking process (training), and the tasting and selling of the cake (evaluation and distribution). Leveraging our re-conceptualization, we describe each step's entailed social ramifications and how they are bounded by statistical assumptions within machine learning. Whereas these technical foundations and social impacts are deeply intertwined, they are often studied in isolation, creating barriers that restrict meaningful participation. Our re-conceptualization paves the way to bridge this gap by mapping where technical foundations interact with social outcomes, highlighting opportunities for cross-disciplinary dialogue. Finally, we conclude with actionable recommendations at each stage of the metaphorical AI cake's life-cycle, empowering prospective AI practitioners, users, and researchers, with increased awareness and ability to engage in broader AI discourse.
Core Tokensets for Data-efficient Sequential Training of Transformers
Oct 08, 2024



Deep networks are frequently tuned to novel tasks and continue learning from ongoing data streams. Such sequential training requires consolidation of new and past information, a challenge predominantly addressed by retaining the most important data points - formally known as coresets. Traditionally, these coresets consist of entire samples, such as images or sentences. However, recent transformer architectures operate on tokens, leading to the famous assertion that an image is worth 16x16 words. Intuitively, not all of these tokens are equally informative or memorable. Going beyond coresets, we thus propose to construct a deeper-level data summary on the level of tokens. Our respectively named core tokensets both select the most informative data points and leverage feature attribution to store only their most relevant features. We demonstrate that core tokensets yield significant performance retention in incremental image classification, open-ended visual question answering, and continual image captioning with significantly reduced memory. In fact, we empirically find that a core tokenset of 1\% of the data performs comparably to at least a twice as large and up to 10 times larger coreset.
BOWLL: A Deceptively Simple Open World Lifelong Learner
Feb 07, 2024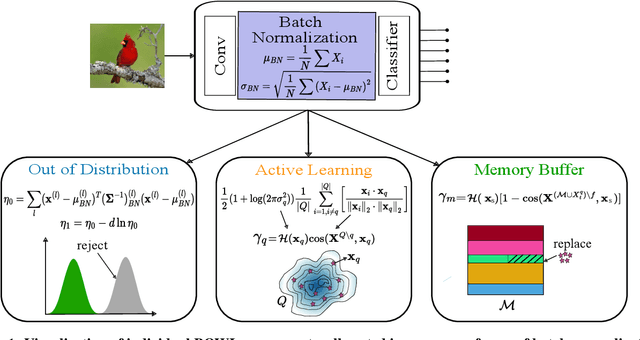
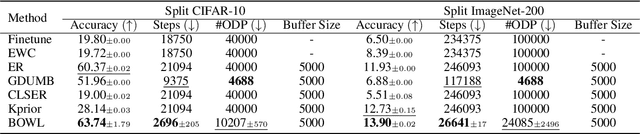
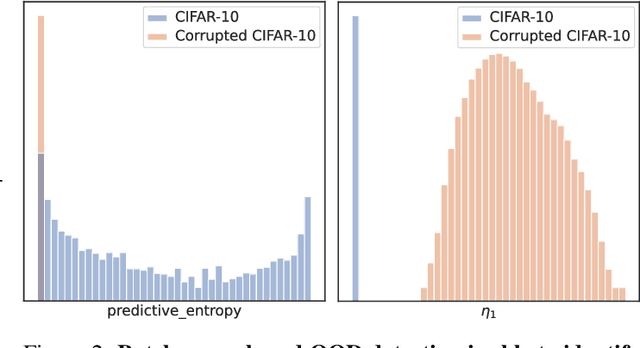
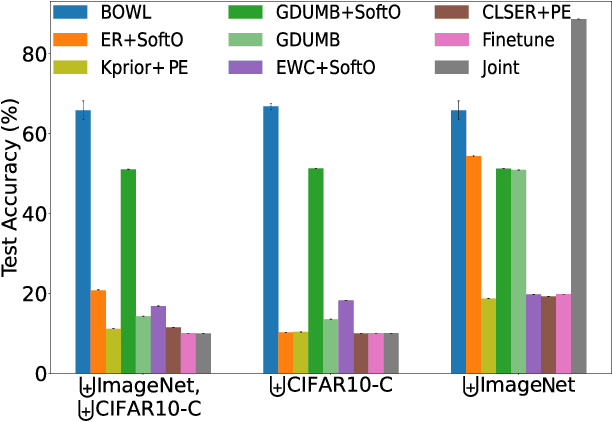
The quest to improve scalar performance numbers on predetermined benchmarks seems to be deeply engraved in deep learning. However, the real world is seldom carefully curated and applications are seldom limited to excelling on test sets. A practical system is generally required to recognize novel concepts, refrain from actively including uninformative data, and retain previously acquired knowledge throughout its lifetime. Despite these key elements being rigorously researched individually, the study of their conjunction, open world lifelong learning, is only a recent trend. To accelerate this multifaceted field's exploration, we introduce its first monolithic and much-needed baseline. Leveraging the ubiquitous use of batch normalization across deep neural networks, we propose a deceptively simple yet highly effective way to repurpose standard models for open world lifelong learning. Through extensive empirical evaluation, we highlight why our approach should serve as a future standard for models that are able to effectively maintain their knowledge, selectively focus on informative data, and accelerate future learning.
Masked Autoencoders are Efficient Continual Federated Learners
Jun 06, 2023



Machine learning is typically framed from a perspective of i.i.d., and more importantly, isolated data. In parts, federated learning lifts this assumption, as it sets out to solve the real-world challenge of collaboratively learning a shared model from data distributed across clients. However, motivated primarily by privacy and computational constraints, the fact that data may change, distributions drift, or even tasks advance individually on clients, is seldom taken into account. The field of continual learning addresses this separate challenge and first steps have recently been taken to leverage synergies in distributed supervised settings, in which several clients learn to solve changing classification tasks over time without forgetting previously seen ones. Motivated by these prior works, we posit that such federated continual learning should be grounded in unsupervised learning of representations that are shared across clients; in the loose spirit of how humans can indirectly leverage others' experience without exposure to a specific task. For this purpose, we demonstrate that masked autoencoders for distribution estimation are particularly amenable to this setup. Specifically, their masking strategy can be seamlessly integrated with task attention mechanisms to enable selective knowledge transfer between clients. We empirically corroborate the latter statement through several continual federated scenarios on both image and binary datasets.