 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere is the Truth? The Risk of Getting Confounded in a Continual World
Feb 09, 2024A dataset is confounded if it is most easily solved via a spurious correlation which fails to generalize to new data. We will show that, in a continual learning setting where confounders may vary in time across tasks, the resulting challenge far exceeds the standard forgetting problem normally considered. In particular, we derive mathematically the effect of such confounders on the space of valid joint solutions to sets of confounded tasks. Interestingly, our theory predicts that for many such continual datasets, spurious correlations are easily ignored when the tasks are trained on jointly, but it is far harder to avoid confounding when they are considered sequentially. We construct such a dataset and demonstrate empirically that standard continual learning methods fail to ignore confounders, while training jointly on all tasks is successful. Our continually confounded dataset, ConCon, is based on CLEVR images and demonstrates the need for continual learning methods with more robust behavior with respect to confounding.
BOWLL: A Deceptively Simple Open World Lifelong Learner
Feb 07, 2024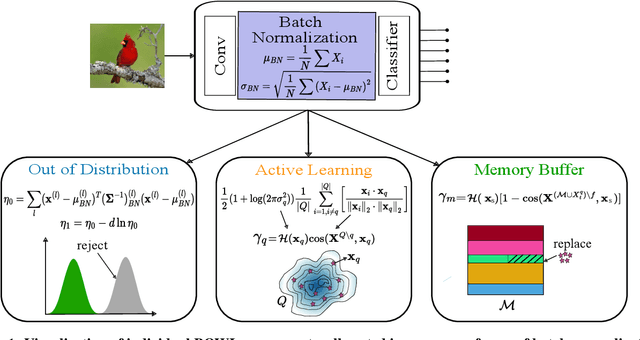
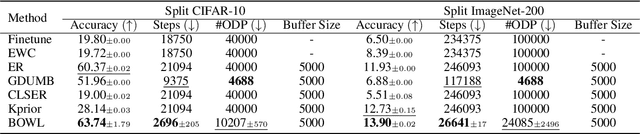
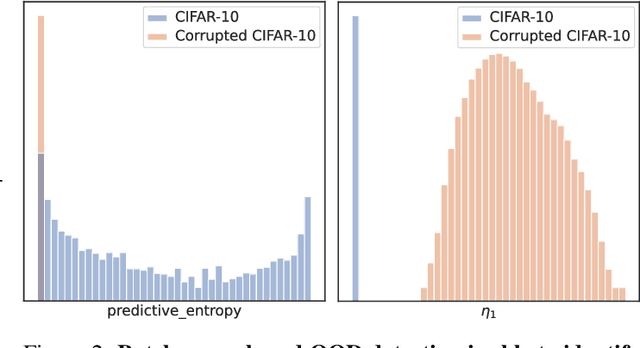
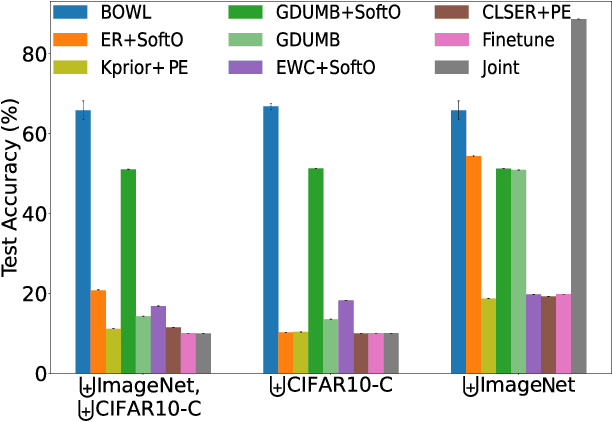
The quest to improve scalar performance numbers on predetermined benchmarks seems to be deeply engraved in deep learning. However, the real world is seldom carefully curated and applications are seldom limited to excelling on test sets. A practical system is generally required to recognize novel concepts, refrain from actively including uninformative data, and retain previously acquired knowledge throughout its lifetime. Despite these key elements being rigorously researched individually, the study of their conjunction, open world lifelong learning, is only a recent trend. To accelerate this multifaceted field's exploration, we introduce its first monolithic and much-needed baseline. Leveraging the ubiquitous use of batch normalization across deep neural networks, we propose a deceptively simple yet highly effective way to repurpose standard models for open world lifelong learning. Through extensive empirical evaluation, we highlight why our approach should serve as a future standard for models that are able to effectively maintain their knowledge, selectively focus on informative data, and accelerate future learning.
Masked Autoencoders are Efficient Continual Federated Learners
Jun 06, 2023



Machine learning is typically framed from a perspective of i.i.d., and more importantly, isolated data. In parts, federated learning lifts this assumption, as it sets out to solve the real-world challenge of collaboratively learning a shared model from data distributed across clients. However, motivated primarily by privacy and computational constraints, the fact that data may change, distributions drift, or even tasks advance individually on clients, is seldom taken into account. The field of continual learning addresses this separate challenge and first steps have recently been taken to leverage synergies in distributed supervised settings, in which several clients learn to solve changing classification tasks over time without forgetting previously seen ones. Motivated by these prior works, we posit that such federated continual learning should be grounded in unsupervised learning of representations that are shared across clients; in the loose spirit of how humans can indirectly leverage others' experience without exposure to a specific task. For this purpose, we demonstrate that masked autoencoders for distribution estimation are particularly amenable to this setup. Specifically, their masking strategy can be seamlessly integrated with task attention mechanisms to enable selective knowledge transfer between clients. We empirically corroborate the latter statement through several continual federated scenarios on both image and binary datasets.