 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Subspaces for Out-of-Distribution Detection
Aug 29, 2025To ensure the reliability of deep models in real-world applications, out-of-distribution (OOD) detection methods aim to distinguish samples close to the training distribution (in-distribution, ID) from those farther away (OOD). In this work, we propose a novel OOD detection method that utilizes singular value decomposition of the weight matrix of the classification head to decompose the model's activations into decisive and insignificant components, which contribute maximally, respectively minimally, to the final classifier output. We find that the subspace of insignificant components more effectively distinguishes ID from OOD data than raw activations in regimes of large distribution shifts (Far-OOD). This occurs because the classification objective leaves the insignificant subspace largely unaffected, yielding features that are ''untainted'' by the target classification task. Conversely, in regimes of smaller distribution shifts (Near-OOD), we find that activation shaping methods profit from only considering the decisive subspace, as the insignificant component can cause interference in the activation space. By combining two findings into a single approach, termed ActSub, we achieve state-of-the-art results in various standard OOD benchmarks.
Disentangling Polysemantic Channels in Convolutional Neural Networks
Apr 17, 2025Mechanistic interpretability is concerned with analyzing individual components in a (convolutional) neural network (CNN) and how they form larger circuits representing decision mechanisms. These investigations are challenging since CNNs frequently learn polysemantic channels that encode distinct concepts, making them hard to interpret. To address this, we propose an algorithm to disentangle a specific kind of polysemantic channel into multiple channels, each responding to a single concept. Our approach restructures weights in a CNN, utilizing that different concepts within the same channel exhibit distinct activation patterns in the previous layer. By disentangling these polysemantic features, we enhance the interpretability of CNNs, ultimately improving explanatory techniques such as feature visualizations.
Beyond Accuracy: What Matters in Designing Well-Behaved Models?
Mar 21, 2025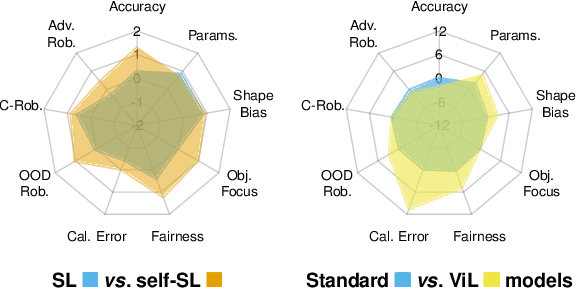

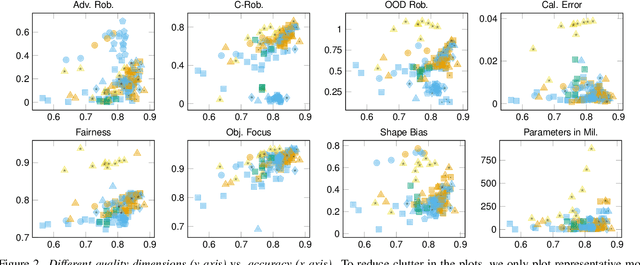
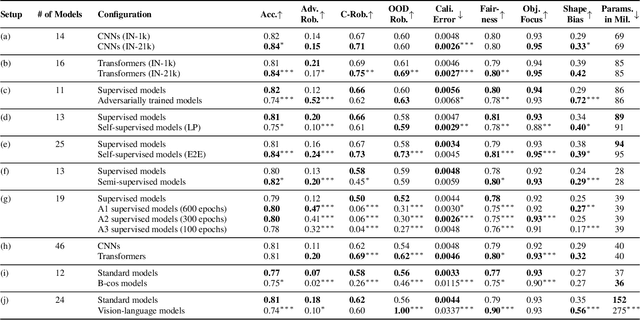
Deep learning has become an essential part of computer vision, with deep neural networks (DNNs) excelling in predictive performance. However, they often fall short in other critical quality dimensions, such as robustness, calibration, or fairness. While existing studies have focused on a subset of these quality dimensions, none have explored a more general form of "well-behavedness" of DNNs. With this work, we address this gap by simultaneously studying nine different quality dimensions for image classification. Through a large-scale study, we provide a bird's-eye view by analyzing 326 backbone models and how different training paradigms and model architectures affect the quality dimensions. We reveal various new insights such that (i) vision-language models exhibit high fairness on ImageNet-1k classification and strong robustness against domain changes; (ii) self-supervised learning is an effective training paradigm to improve almost all considered quality dimensions; and (iii) the training dataset size is a major driver for most of the quality dimensions. We conclude our study by introducing the QUBA score (Quality Understanding Beyond Accuracy), a novel metric that ranks models across multiple dimensions of quality, enabling tailored recommendations based on specific user needs.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025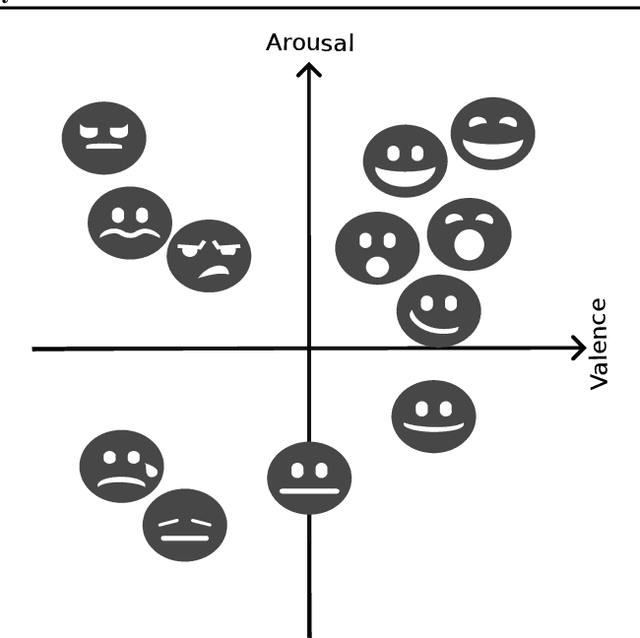


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
Benchmarking the Attribution Quality of Vision Models
Jul 16, 2024Attribution maps are one of the most established tools to explain the functioning of computer vision models. They assign importance scores to input features, indicating how relevant each feature is for the prediction of a deep neural network. While much research has gone into proposing new attribution methods, their proper evaluation remains a difficult challenge. In this work, we propose a novel evaluation protocol that overcomes two fundamental limitations of the widely used incremental-deletion protocol, i.e., the out-of-domain issue and lacking inter-model comparisons. This allows us to evaluate 23 attribution methods and how eight different design choices of popular vision models affect their attribution quality. We find that intrinsically explainable models outperform standard models and that raw attribution values exhibit a higher attribution quality than what is known from previous work. Further, we show consistent changes in the attribution quality when varying the network design, indicating that some standard design choices promote attribution quality.
FunnyBirds: A Synthetic Vision Dataset for a Part-Based Analysis of Explainable AI Methods
Aug 11, 2023The field of explainable artificial intelligence (XAI) aims to uncover the inner workings of complex deep neural models. While being crucial for safety-critical domains, XAI inherently lacks ground-truth explanations, making its automatic evaluation an unsolved problem. We address this challenge by proposing a novel synthetic vision dataset, named FunnyBirds, and accompanying automatic evaluation protocols. Our dataset allows performing semantically meaningful image interventions, e.g., removing individual object parts, which has three important implications. First, it enables analyzing explanations on a part level, which is closer to human comprehension than existing methods that evaluate on a pixel level. Second, by comparing the model output for inputs with removed parts, we can estimate ground-truth part importances that should be reflected in the explanations. Third, by mapping individual explanations into a common space of part importances, we can analyze a variety of different explanation types in a single common framework. Using our tools, we report results for 24 different combinations of neural models and XAI methods, demonstrating the strengths and weaknesses of the assessed methods in a fully automatic and systematic manner.
Content-Adaptive Downsampling in Convolutional Neural Networks
May 16, 2023Many convolutional neural networks (CNNs) rely on progressive downsampling of their feature maps to increase the network's receptive field and decrease computational cost. However, this comes at the price of losing granularity in the feature maps, limiting the ability to correctly understand images or recover fine detail in dense prediction tasks. To address this, common practice is to replace the last few downsampling operations in a CNN with dilated convolutions, allowing to retain the feature map resolution without reducing the receptive field, albeit increasing the computational cost. This allows to trade off predictive performance against cost, depending on the output feature resolution. By either regularly downsampling or not downsampling the entire feature map, existing work implicitly treats all regions of the input image and subsequent feature maps as equally important, which generally does not hold. We propose an adaptive downsampling scheme that generalizes the above idea by allowing to process informative regions at a higher resolution than less informative ones. In a variety of experiments, we demonstrate the versatility of our adaptive downsampling strategy and empirically show that it improves the cost-accuracy trade-off of various established CNNs.
Fast Axiomatic Attribution for Neural Networks
Nov 15, 2021
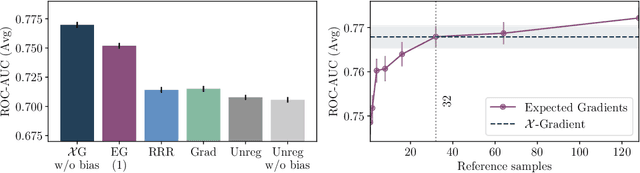


Mitigating the dependence on spurious correlations present in the training dataset is a quickly emerging and important topic of deep learning. Recent approaches include priors on the feature attribution of a deep neural network (DNN) into the training process to reduce the dependence on unwanted features. However, until now one needed to trade off high-quality attributions, satisfying desirable axioms, against the time required to compute them. This in turn either led to long training times or ineffective attribution priors. In this work, we break this trade-off by considering a special class of efficiently axiomatically attributable DNNs for which an axiomatic feature attribution can be computed with only a single forward/backward pass. We formally prove that nonnegatively homogeneous DNNs, here termed $\mathcal{X}$-DNNs, are efficiently axiomatically attributable and show that they can be effortlessly constructed from a wide range of regular DNNs by simply removing the bias term of each layer. Various experiments demonstrate the advantages of $\mathcal{X}$-DNNs, beating state-of-the-art generic attribution methods on regular DNNs for training with attribution priors.