 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVM-SLAM: Decentralized Visual Monocular Simultaneous Localization and Mapping for Multi-Agent Systems
Mar 06, 2025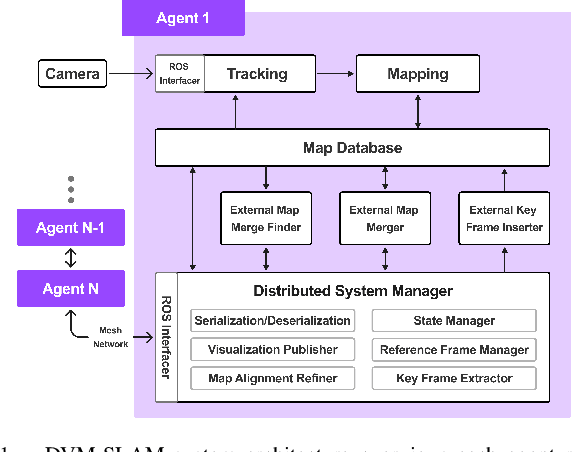
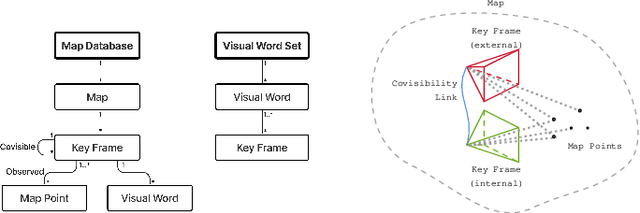
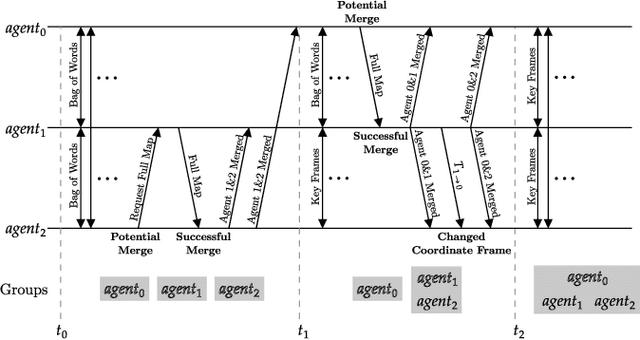
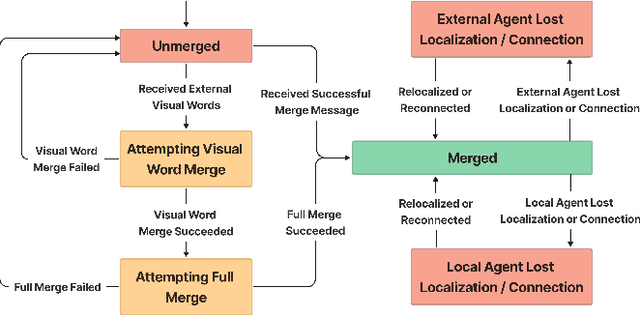
Cooperative Simultaneous Localization and Mapping (C-SLAM) enables multiple agents to work together in mapping unknown environments while simultaneously estimating their own positions. This approach enhances robustness, scalability, and accuracy by sharing information between agents, reducing drift, and enabling collective exploration of larger areas. In this paper, we present Decentralized Visual Monocular SLAM (DVM-SLAM), the first open-source decentralized monocular C-SLAM system. By only utilizing low-cost and light-weight monocular vision sensors, our system is well suited for small robots and micro aerial vehicles (MAVs). DVM-SLAM's real-world applicability is validated on physical robots with a custom collision avoidance framework, showcasing its potential in real-time multi-agent autonomous navigation scenarios. We also demonstrate comparable accuracy to state-of-the-art centralized monocular C-SLAM systems. We open-source our code and provide supplementary material online.
Language-Conditioned Offline RL for Multi-Robot Navigation
Jul 29, 2024We present a method for developing navigation policies for multi-robot teams that interpret and follow natural language instructions. We condition these policies on embeddings from pretrained Large Language Models (LLMs), and train them via offline reinforcement learning with as little as 20 minutes of randomly-collected data. Experiments on a team of five real robots show that these policies generalize well to unseen commands, indicating an understanding of the LLM latent space. Our method requires no simulators or environment models, and produces low-latency control policies that can be deployed directly to real robots without finetuning. We provide videos of our experiments at https://sites.google.com/view/llm-marl.
The Cambridge RoboMaster: An Agile Multi-Robot Research Platform
May 03, 2024



Compact robotic platforms with powerful compute and actuation capabilities are key enablers for practical, real-world deployments of multi-agent research. This article introduces a tightly integrated hardware, control, and simulation software stack on a fleet of holonomic ground robot platforms designed with this motivation. Our robots, a fleet of customised DJI Robomaster S1 vehicles, offer a balance between small robots that do not possess sufficient compute or actuation capabilities and larger robots that are unsuitable for indoor multi-robot tests. They run a modular ROS2-based optimal estimation and control stack for full onboard autonomy, contain ad-hoc peer-to-peer communication infrastructure, and can zero-shot run multi-agent reinforcement learning (MARL) policies trained in our vectorized multi-agent simulation framework. We present an in-depth review of other platforms currently available, showcase new experimental validation of our system's capabilities, and introduce case studies that highlight the versatility and reliabilty of our system as a testbed for a wide range of research demonstrations. Our system as well as supplementary material is available online: https://proroklab.github.io/cambridge-robomaster
CoViS-Net: A Cooperative Visual Spatial Foundation Model for Multi-Robot Applications
May 02, 2024Spatial understanding from vision is crucial for robots operating in unstructured environments. In the real world, spatial understanding is often an ill-posed problem. There are a number of powerful classical methods that accurately regress relative pose, however, these approaches often lack the ability to leverage data-derived priors to resolve ambiguities. In multi-robot systems, these challenges are exacerbated by the need for accurate and frequent position estimates of cooperating agents. To this end, we propose CoViS-Net, a cooperative, multi-robot, visual spatial foundation model that learns spatial priors from data. Unlike prior work evaluated primarily on offline datasets, we design our model specifically for online evaluation and real-world deployment on cooperative robots. Our model is completely decentralized, platform agnostic, executable in real-time using onboard compute, and does not require existing network infrastructure. In this work, we focus on relative pose estimation and local Bird's Eye View (BEV) prediction tasks. Unlike classical approaches, we show that our model can accurately predict relative poses without requiring camera overlap, and predict BEVs of regions not visible to the ego-agent. We demonstrate our model on a multi-robot formation control task outside the confines of the laboratory.
Learning to Navigate using Visual Sensor Networks
Aug 05, 2022
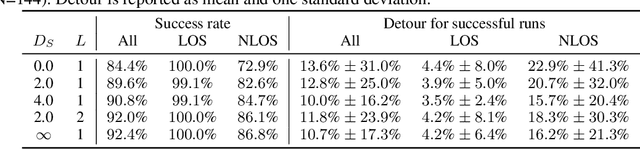
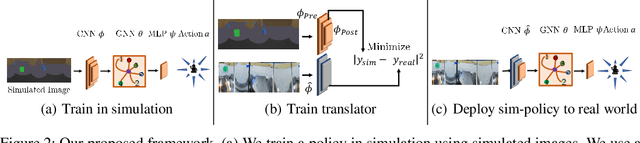
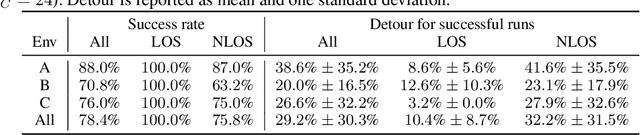
We consider the problem of navigating a mobile robot towards a target in an unknown environment that is endowed with visual sensors, where neither the robot nor the sensors have access to global positioning information and only use first-person-view images. While prior work in sensor network-based navigation uses explicit mapping and planning techniques, and is often aided by external positioning systems, we propose a vision-only based learning approach that leverages a Graph Neural Network (GNN) to encode and communicate relevant viewpoint information to the mobile robot. During navigation, the robot is guided by a model that we train through imitation learning to approximate optimal motion primitives, thereby predicting the effective cost-to-go (to the target). In our experiments, we first demonstrate generalizability to previously unseen environments with various sensor layouts. The results show that communication among the sensors and robot facilitates a significant improvement in success rate while decreasing path detour mean and variability. This is done without requiring a global map, positioning data, nor pre-calibration of the sensor network. Second, we perform a zero-shot transfer of our model from simulation to the real world. To this end, we train a`translator' model that translates between {latent encodings of} real and simulated images so that the navigation policy (which is trained entirely in simulation) can be used directly on the real robot, without additional fine-tuning. Physical experiments demonstrate the feasibility of our approach in various cluttered environments.
VMAS: A Vectorized Multi-Agent Simulator for Collective Robot Learning
Jul 07, 2022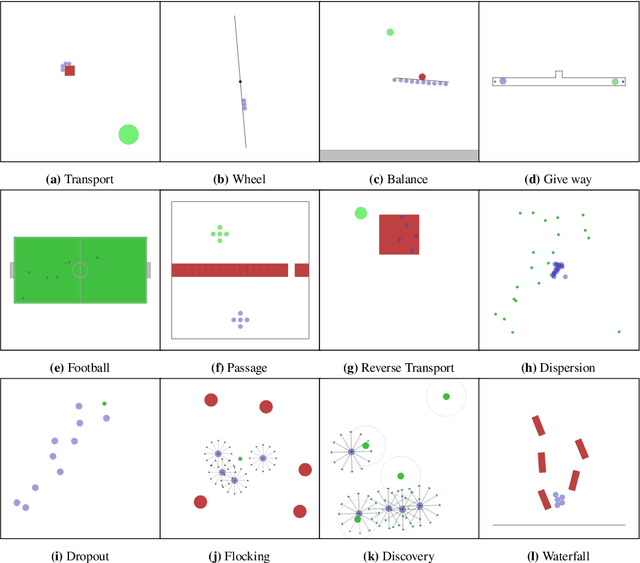
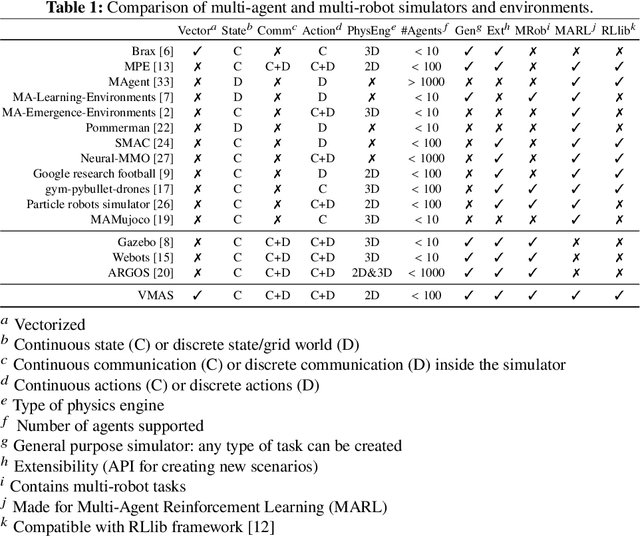
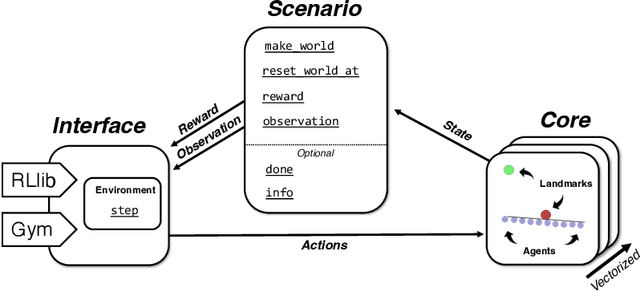
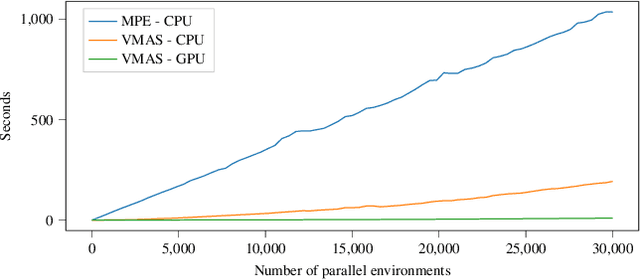
While many multi-robot coordination problems can be solved optimally by exact algorithms, solutions are often not scalable in the number of robots. Multi-Agent Reinforcement Learning (MARL) is gaining increasing attention in the robotics community as a promising solution to tackle such problems. Nevertheless, we still lack the tools that allow us to quickly and efficiently find solutions to large-scale collective learning tasks. In this work, we introduce the Vectorized Multi-Agent Simulator (VMAS). VMAS is an open-source framework designed for efficient MARL benchmarking. It is comprised of a vectorized 2D physics engine written in PyTorch and a set of twelve challenging multi-robot scenarios. Additional scenarios can be implemented through a simple and modular interface. We demonstrate how vectorization enables parallel simulation on accelerated hardware without added complexity. When comparing VMAS to OpenAI MPE, we show how MPE's execution time increases linearly in the number of simulations while VMAS is able to execute 30,000 parallel simulations in under 10s, proving more than 100x faster. Using VMAS's RLlib interface, we benchmark our multi-robot scenarios using various Proximal Policy Optimization (PPO)-based MARL algorithms. VMAS's scenarios prove challenging in orthogonal ways for state-of-the-art MARL algorithms. The VMAS framework is available at https://github.com/proroklab/VectorizedMultiAgentSimulator. A video of VMAS scenarios and experiments is available at https://youtu.be/aaDRYfiesAY}{here}\footnote{\url{https://youtu.be/aaDRYfiesAY.
A Framework for Real-World Multi-Robot Systems Running Decentralized GNN-Based Policies
Nov 02, 2021



Graph Neural Networks (GNNs) are a paradigm-shifting neural architecture to facilitate the learning of complex multi-agent behaviors. Recent work has demonstrated remarkable performance in tasks such as flocking, multi-agent path planning and cooperative coverage. However, the policies derived through GNN-based learning schemes have not yet been deployed to the real-world on physical multi-robot systems. In this work, we present the design of a system that allows for fully decentralized execution of GNN-based policies. We create a framework based on ROS2 and elaborate its details in this paper. We demonstrate our framework on a case-study that requires tight coordination between robots, and present first-of-a-kind results that show successful real-world deployment of GNN-based policies on a decentralized multi-robot system relying on Adhoc communication. A video demonstration of this case-study can be found online. https://www.youtube.com/watch?v=COh-WLn4iO4
The Holy Grail of Multi-Robot Planning: Learning to Generate Online-Scalable Solutions from Offline-Optimal Experts
Jul 26, 2021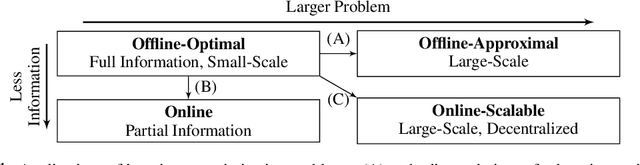
Many multi-robot planning problems are burdened by the curse of dimensionality, which compounds the difficulty of applying solutions to large-scale problem instances. The use of learning-based methods in multi-robot planning holds great promise as it enables us to offload the online computational burden of expensive, yet optimal solvers, to an offline learning procedure. Simply put, the idea is to train a policy to copy an optimal pattern generated by a small-scale system, and then transfer that policy to much larger systems, in the hope that the learned strategy scales, while maintaining near-optimal performance. Yet, a number of issues impede us from leveraging this idea to its full potential. This blue-sky paper elaborates some of the key challenges that remain.
Gaussian Process Based Message Filtering for Robust Multi-Agent Cooperation in the Presence of Adversarial Communication
Dec 01, 2020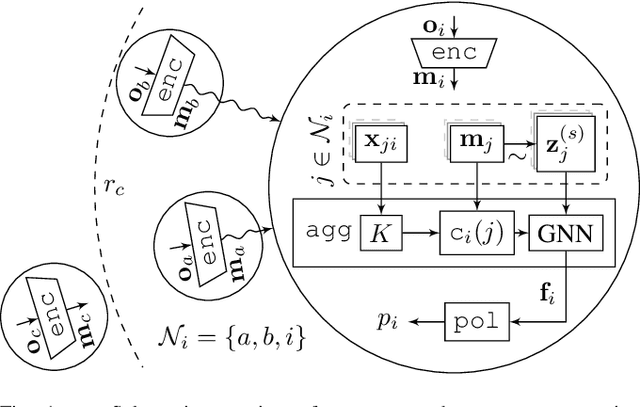

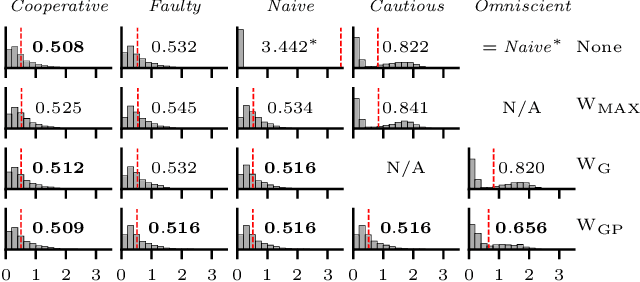

In this paper, we consider the problem of providing robustness to adversarial communication in multi-agent systems. Specifically, we propose a solution towards robust cooperation, which enables the multi-agent system to maintain high performance in the presence of anonymous non-cooperative agents that communicate faulty, misleading or manipulative information. In pursuit of this goal, we propose a communication architecture based on Graph Neural Networks (GNNs), which is amenable to a novel Gaussian Process (GP)-based probabilistic model characterizing the mutual information between the simultaneous communications of different agents due to their physical proximity and relative position. This model allows agents to locally compute approximate posterior probabilities, or confidences, that any given one of their communication partners is being truthful. These confidences can be used as weights in a message filtering scheme, thereby suppressing the influence of suspicious communication on the receiving agent's decisions. In order to assess the efficacy of our method, we introduce a taxonomy of non-cooperative agents, which distinguishes them by the amount of information available to them. We demonstrate in two distinct experiments that our method performs well across this taxonomy, outperforming alternative methods. For all but the best informed adversaries, our filtering method is able to reduce the impact that non-cooperative agents cause, reducing it to the point of negligibility, and with negligible cost to performance in the absence of adversaries.
The Emergence of Adversarial Communication in Multi-Agent Reinforcement Learning
Aug 06, 2020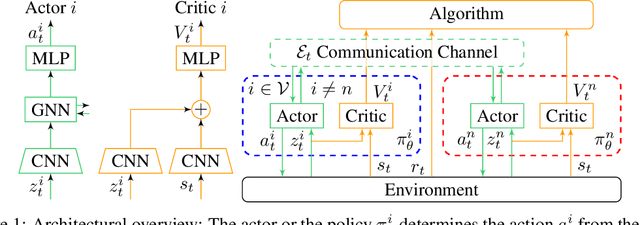

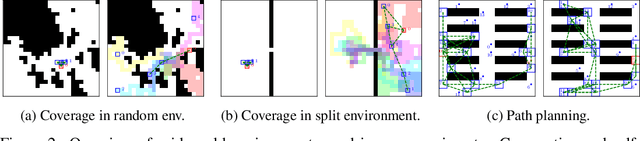

Many real-world problems require the coordination of multiple autonomous agents. Recent work has shown the promise of Graph Neural Networks (GNNs) to learn explicit communication strategies that enable complex multi-agent coordination. These works use models of cooperative multi-agent systems whereby agents strive to achieve a shared global goal. When considering agents with self-interested local objectives, the standard design choice is to model these as separate learning systems (albeit sharing the same environment). Such a design choice, however, precludes the existence of a single, differentiable communication channel, and consequently prohibits the learning of inter-agent communication strategies. In this work, we address this gap by presenting a learning model that accommodates individual non-shared rewards and a differentiable communication channel that is common among all agents. We focus on the case where agents have self-interested objectives, and develop a learning algorithm that elicits the emergence of adversarial communications. We perform experiments on multi-agent coverage and path planning problems, and employ a post-hoc interpretability technique to visualize the messages that agents communicate to each other. We show how a single self-interested agent is capable of learning highly manipulative communication strategies that allows it to significantly outperform a cooperative team of agents.