 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Navigate using Visual Sensor Networks
Aug 05, 2022
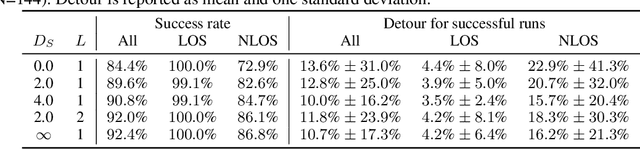
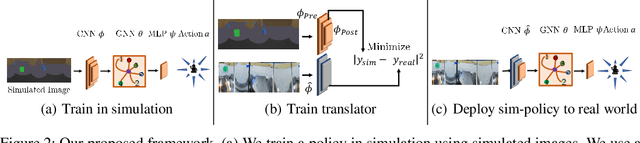
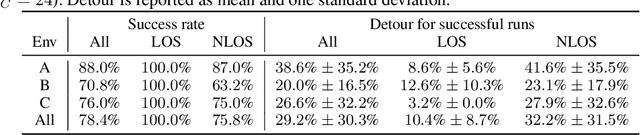
We consider the problem of navigating a mobile robot towards a target in an unknown environment that is endowed with visual sensors, where neither the robot nor the sensors have access to global positioning information and only use first-person-view images. While prior work in sensor network-based navigation uses explicit mapping and planning techniques, and is often aided by external positioning systems, we propose a vision-only based learning approach that leverages a Graph Neural Network (GNN) to encode and communicate relevant viewpoint information to the mobile robot. During navigation, the robot is guided by a model that we train through imitation learning to approximate optimal motion primitives, thereby predicting the effective cost-to-go (to the target). In our experiments, we first demonstrate generalizability to previously unseen environments with various sensor layouts. The results show that communication among the sensors and robot facilitates a significant improvement in success rate while decreasing path detour mean and variability. This is done without requiring a global map, positioning data, nor pre-calibration of the sensor network. Second, we perform a zero-shot transfer of our model from simulation to the real world. To this end, we train a`translator' model that translates between {latent encodings of} real and simulated images so that the navigation policy (which is trained entirely in simulation) can be used directly on the real robot, without additional fine-tuning. Physical experiments demonstrate the feasibility of our approach in various cluttered environments.
Mobile Robot Path Planning in Dynamic Environments through Globally Guided Reinforcement Learning
May 11, 2020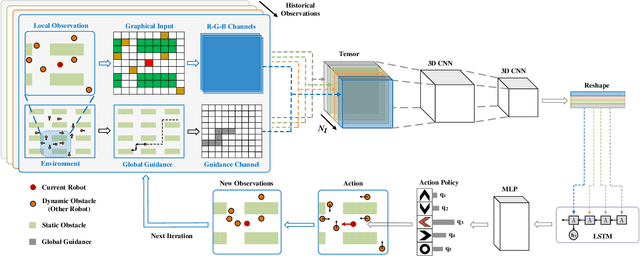

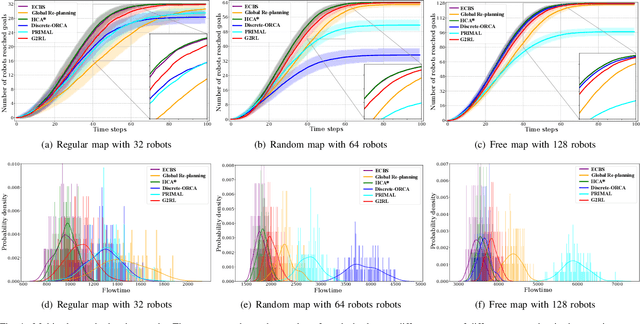
Path planning for mobile robots in large dynamic environments is a challenging problem, as the robots are required to efficiently reach their given goals while simultaneously avoiding potential conflicts with other robots or dynamic objects. In the presence of dynamic obstacles, traditional solutions usually employ re-planning strategies, which re-call a planning algorithm to search for an alternative path whenever the robot encounters a conflict. However, such re-planning strategies often cause unnecessary detours. To address this issue, we propose a learning-based technique that exploits environmental spatio-temporal information. Different from existing learning-based methods, we introduce a globally guided reinforcement learning approach (G2RL), which incorporates a novel reward structure that generalizes to arbitrary environments. We apply G2RL to solve the multi-robot path planning problem in a fully distributed reactive manner. We evaluate our method across different map types, obstacle densities, and the number of robots. Experimental results show that G2RL generalizes well, outperforming existing distributed methods, and performing very similarly to fully centralized state-of-the-art benchmarks.