 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOPGym Arcade: Parallel Pixelated POMDPs
Mar 04, 2025We introduce POPGym Arcade, a benchmark consisting of 7 pixel-based environments each with three difficulties, utilizing a single observation and action space. Each environment offers both fully observable and partially observable variants, enabling counterfactual studies on partial observability. POPGym Arcade utilizes JIT compilation on hardware accelerators to achieve substantial speedups over CPU-bound environments. Moreover, this enables Podracer-style architectures to further increase hardware utilization and training speed. We evaluate memory models on our environments using a Podracer variant of Q learning, and examine the results. Finally, we generate memory saliency maps, uncovering how memories propagate through policies. Our library is available at https://github.com/bolt-research/popgym_arcade.
Language-Conditioned Offline RL for Multi-Robot Navigation
Jul 29, 2024We present a method for developing navigation policies for multi-robot teams that interpret and follow natural language instructions. We condition these policies on embeddings from pretrained Large Language Models (LLMs), and train them via offline reinforcement learning with as little as 20 minutes of randomly-collected data. Experiments on a team of five real robots show that these policies generalize well to unseen commands, indicating an understanding of the LLM latent space. Our method requires no simulators or environment models, and produces low-latency control policies that can be deployed directly to real robots without finetuning. We provide videos of our experiments at https://sites.google.com/view/llm-marl.
CoViS-Net: A Cooperative Visual Spatial Foundation Model for Multi-Robot Applications
May 02, 2024Spatial understanding from vision is crucial for robots operating in unstructured environments. In the real world, spatial understanding is often an ill-posed problem. There are a number of powerful classical methods that accurately regress relative pose, however, these approaches often lack the ability to leverage data-derived priors to resolve ambiguities. In multi-robot systems, these challenges are exacerbated by the need for accurate and frequent position estimates of cooperating agents. To this end, we propose CoViS-Net, a cooperative, multi-robot, visual spatial foundation model that learns spatial priors from data. Unlike prior work evaluated primarily on offline datasets, we design our model specifically for online evaluation and real-world deployment on cooperative robots. Our model is completely decentralized, platform agnostic, executable in real-time using onboard compute, and does not require existing network infrastructure. In this work, we focus on relative pose estimation and local Bird's Eye View (BEV) prediction tasks. Unlike classical approaches, we show that our model can accurately predict relative poses without requiring camera overlap, and predict BEVs of regions not visible to the ego-agent. We demonstrate our model on a multi-robot formation control task outside the confines of the laboratory.
Generalising Multi-Agent Cooperation through Task-Agnostic Communication
Mar 11, 2024Existing communication methods for multi-agent reinforcement learning (MARL) in cooperative multi-robot problems are almost exclusively task-specific, training new communication strategies for each unique task. We address this inefficiency by introducing a communication strategy applicable to any task within a given environment. We pre-train the communication strategy without task-specific reward guidance in a self-supervised manner using a set autoencoder. Our objective is to learn a fixed-size latent Markov state from a variable number of agent observations. Under mild assumptions, we prove that policies using our latent representations are guaranteed to converge, and upper bound the value error introduced by our Markov state approximation. Our method enables seamless adaptation to novel tasks without fine-tuning the communication strategy, gracefully supports scaling to more agents than present during training, and detects out-of-distribution events in an environment. Empirical results on diverse MARL scenarios validate the effectiveness of our approach, surpassing task-specific communication strategies in unseen tasks. Our implementation of this work is available at https://github.com/proroklab/task-agnostic-comms.
Revisiting Recurrent Reinforcement Learning with Memory Monoids
Feb 15, 2024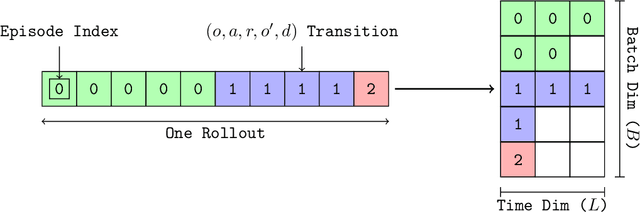
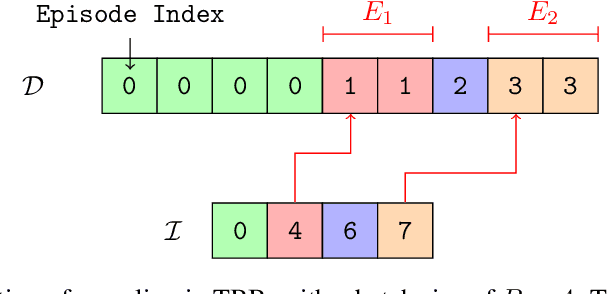
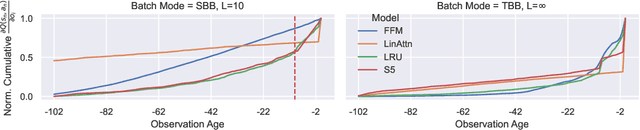

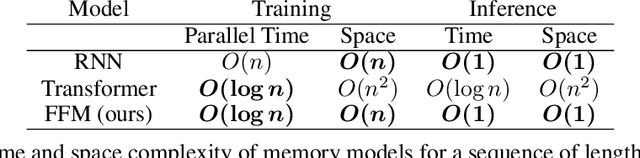
In RL, memory models such as RNNs and transformers address Partially Observable Markov Decision Processes (POMDPs) by mapping trajectories to latent Markov states. Neither model scales particularly well to long sequences, especially compared to an emerging class of memory models sometimes called linear recurrent models. We discover that the recurrent update of these models is a monoid, leading us to formally define a novel memory monoid framework. We revisit the traditional approach to batching in recurrent RL, highlighting both theoretical and empirical deficiencies. Leveraging the properties of memory monoids, we propose a new batching method that improves sample efficiency, increases the return, and simplifies the implementation of recurrent loss functions in RL.
Reinforcement Learning with Fast and Forgetful Memory
Oct 06, 2023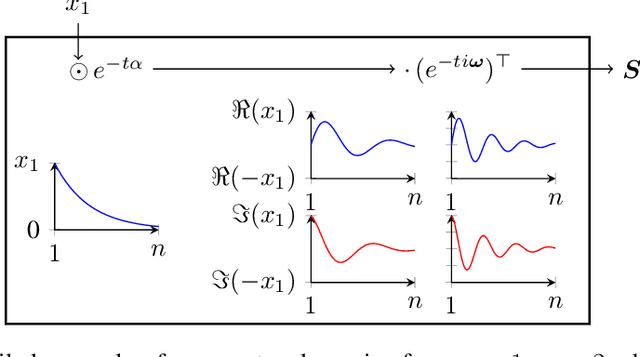
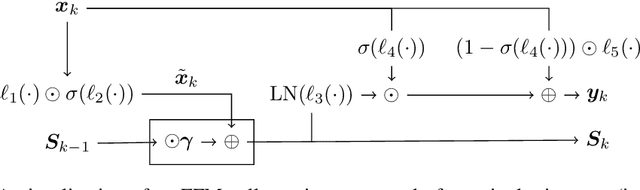
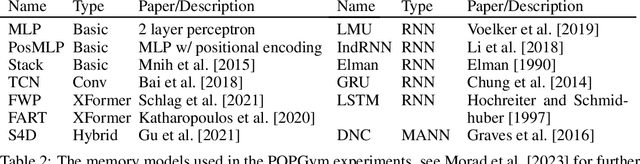
Nearly all real world tasks are inherently partially observable, necessitating the use of memory in Reinforcement Learning (RL). Most model-free approaches summarize the trajectory into a latent Markov state using memory models borrowed from Supervised Learning (SL), even though RL tends to exhibit different training and efficiency characteristics. Addressing this discrepancy, we introduce Fast and Forgetful Memory, an algorithm-agnostic memory model designed specifically for RL. Our approach constrains the model search space via strong structural priors inspired by computational psychology. It is a drop-in replacement for recurrent neural networks (RNNs) in recurrent RL algorithms, achieving greater reward than RNNs across various recurrent benchmarks and algorithms without changing any hyperparameters. Moreover, Fast and Forgetful Memory exhibits training speeds two orders of magnitude faster than RNNs, attributed to its logarithmic time and linear space complexity. Our implementation is available at https://github.com/proroklab/ffm.
Generalised $f$-Mean Aggregation for Graph Neural Networks
Jun 24, 2023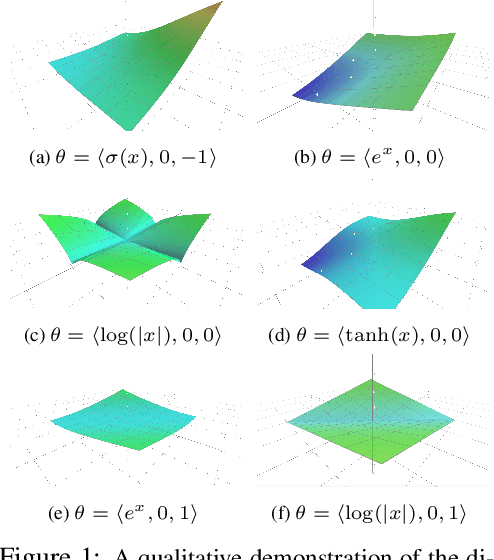
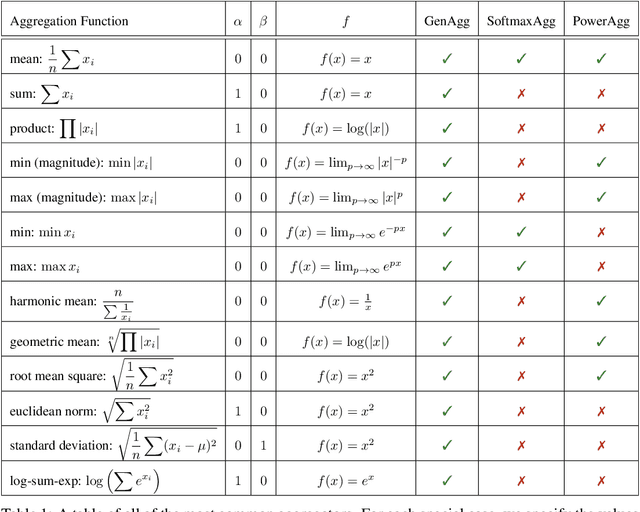

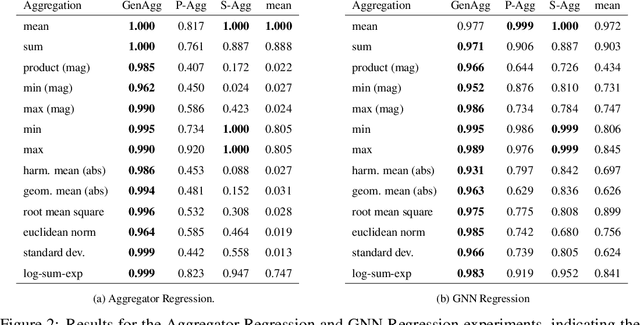
Graph Neural Network (GNN) architectures are defined by their implementations of update and aggregation modules. While many works focus on new ways to parametrise the update modules, the aggregation modules receive comparatively little attention. Because it is difficult to parametrise aggregation functions, currently most methods select a "standard aggregator" such as $\mathrm{mean}$, $\mathrm{sum}$, or $\mathrm{max}$. While this selection is often made without any reasoning, it has been shown that the choice in aggregator has a significant impact on performance, and the best choice in aggregator is problem-dependent. Since aggregation is a lossy operation, it is crucial to select the most appropriate aggregator in order to minimise information loss. In this paper, we present GenAgg, a generalised aggregation operator, which parametrises a function space that includes all standard aggregators. In our experiments, we show that GenAgg is able to represent the standard aggregators with much higher accuracy than baseline methods. We also show that using GenAgg as a drop-in replacement for an existing aggregator in a GNN often leads to a significant boost in performance across various tasks.
POPGym: Benchmarking Partially Observable Reinforcement Learning
Mar 03, 2023Real world applications of Reinforcement Learning (RL) are often partially observable, thus requiring memory. Despite this, partial observability is still largely ignored by contemporary RL benchmarks and libraries. We introduce Partially Observable Process Gym (POPGym), a two-part library containing (1) a diverse collection of 15 partially observable environments, each with multiple difficulties and (2) implementations of 13 memory model baselines -- the most in a single RL library. Existing partially observable benchmarks tend to fixate on 3D visual navigation, which is computationally expensive and only one type of POMDP. In contrast, POPGym environments are diverse, produce smaller observations, use less memory, and often converge within two hours of training on a consumer-grade GPU. We implement our high-level memory API and memory baselines on top of the popular RLlib framework, providing plug-and-play compatibility with various training algorithms, exploration strategies, and distributed training paradigms. Using POPGym, we execute the largest comparison across RL memory models to date. POPGym is available at https://github.com/proroklab/popgym.
Permutation-Invariant Set Autoencoders with Fixed-Size Embeddings for Multi-Agent Learning
Feb 24, 2023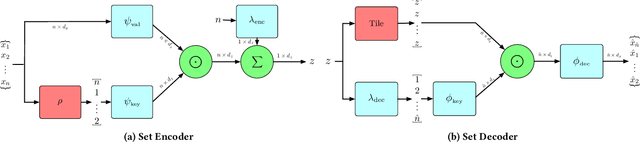
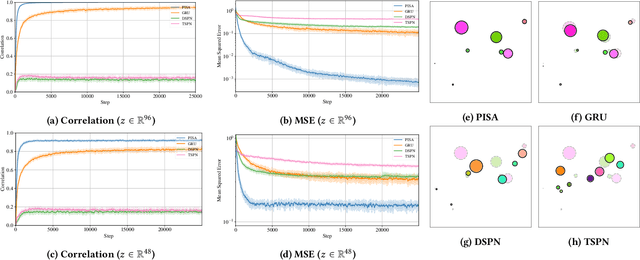
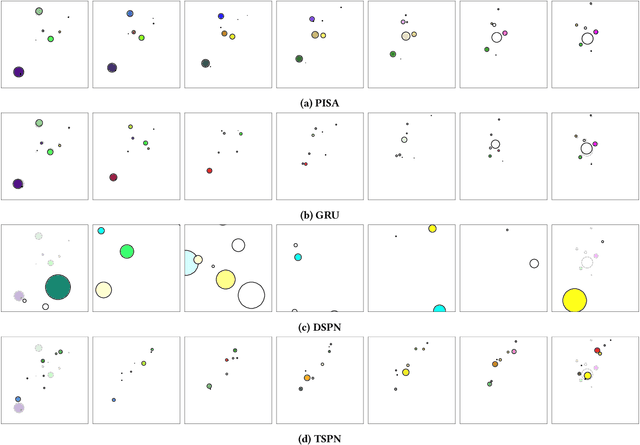
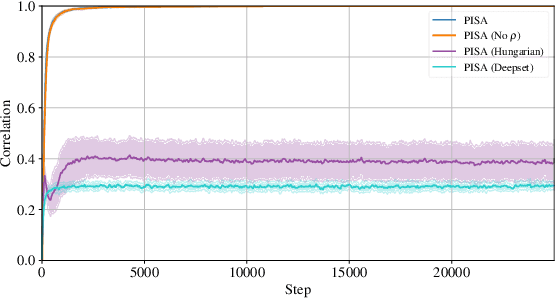
The problem of permutation-invariant learning over set representations is particularly relevant in the field of multi-agent systems -- a few potential applications include unsupervised training of aggregation functions in graph neural networks (GNNs), neural cellular automata on graphs, and prediction of scenes with multiple objects. Yet existing approaches to set encoding and decoding tasks present a host of issues, including non-permutation-invariance, fixed-length outputs, reliance on iterative methods, non-deterministic outputs, computationally expensive loss functions, and poor reconstruction accuracy. In this paper we introduce a Permutation-Invariant Set Autoencoder (PISA), which tackles these problems and produces encodings with significantly lower reconstruction error than existing baselines. PISA also provides other desirable properties, including a similarity-preserving latent space, and the ability to insert or remove elements from the encoding. After evaluating PISA against baseline methods, we demonstrate its usefulness in a multi-agent application. Using PISA as a subcomponent, we introduce a novel GNN architecture which serves as a generalised communication scheme, allowing agents to use communication to gain full observability of a system.
A Framework for Real-World Multi-Robot Systems Running Decentralized GNN-Based Policies
Nov 02, 2021



Graph Neural Networks (GNNs) are a paradigm-shifting neural architecture to facilitate the learning of complex multi-agent behaviors. Recent work has demonstrated remarkable performance in tasks such as flocking, multi-agent path planning and cooperative coverage. However, the policies derived through GNN-based learning schemes have not yet been deployed to the real-world on physical multi-robot systems. In this work, we present the design of a system that allows for fully decentralized execution of GNN-based policies. We create a framework based on ROS2 and elaborate its details in this paper. We demonstrate our framework on a case-study that requires tight coordination between robots, and present first-of-a-kind results that show successful real-world deployment of GNN-based policies on a decentralized multi-robot system relying on Adhoc communication. A video demonstration of this case-study can be found online. https://www.youtube.com/watch?v=COh-WLn4iO4