 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Recurrent Reinforcement Learning with Memory Monoids
Paper and Code
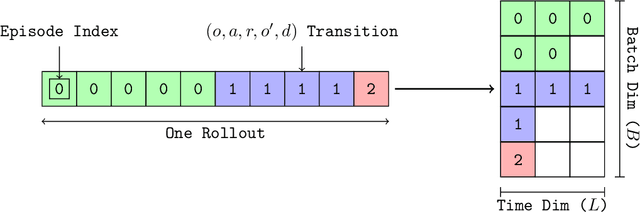
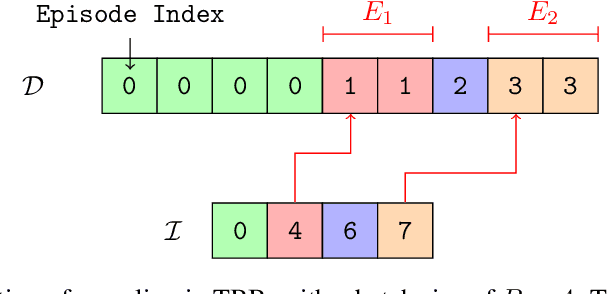
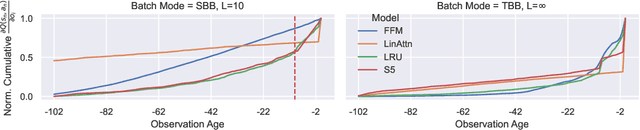

In RL, memory models such as RNNs and transformers address Partially Observable Markov Decision Processes (POMDPs) by mapping trajectories to latent Markov states. Neither model scales particularly well to long sequences, especially compared to an emerging class of memory models sometimes called linear recurrent models. We discover that the recurrent update of these models is a monoid, leading us to formally define a novel memory monoid framework. We revisit the traditional approach to batching in recurrent RL, highlighting both theoretical and empirical deficiencies. Leveraging the properties of memory monoids, we propose a new batching method that improves sample efficiency, increases the return, and simplifies the implementation of recurrent loss functions in RL.