 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural diversity is key to collective artificial learning
Dec 19, 2024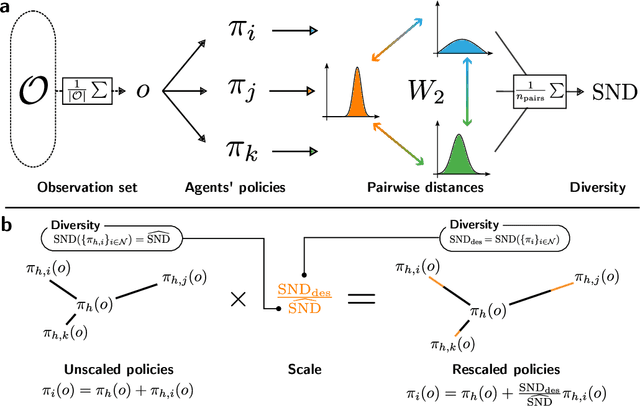
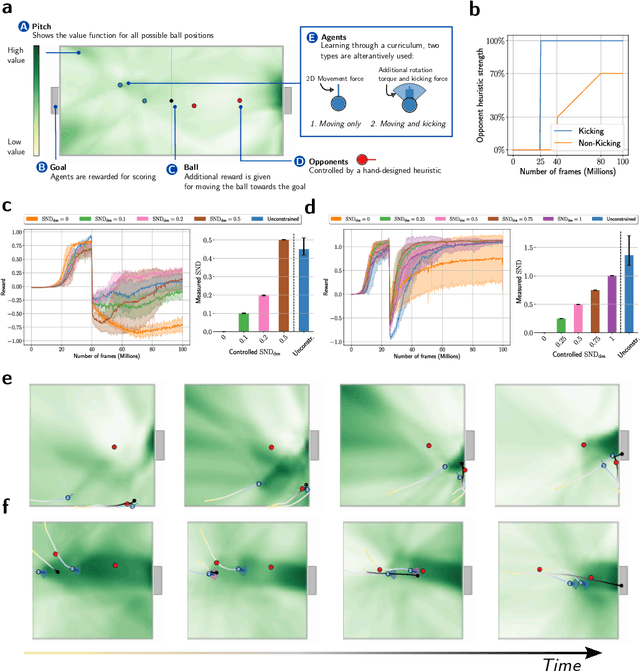
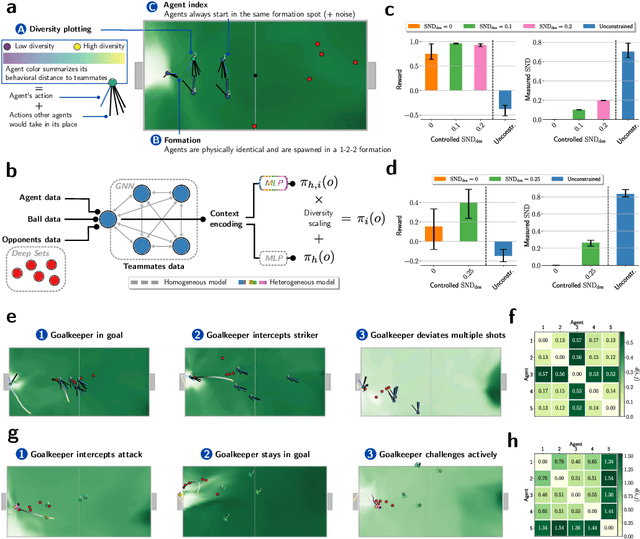
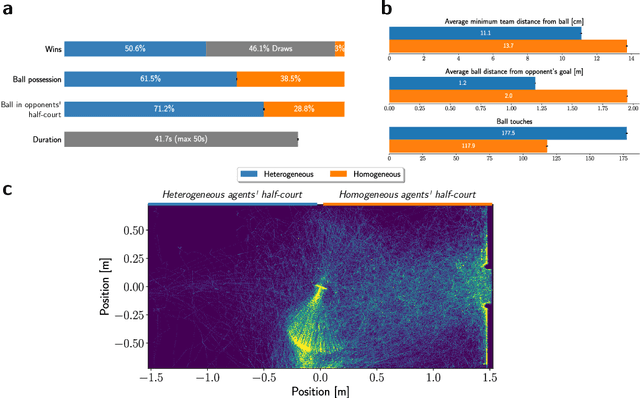
Many of the world's most pressing issues, such as climate change and global peace, require complex collective problem-solving skills. Recent studies indicate that diversity in individuals' behaviors is key to developing such skills and increasing collective performance. Yet behavioral diversity in collective artificial learning is understudied, with today's machine learning paradigms commonly favoring homogeneous agent strategies over heterogeneous ones, mainly due to computational considerations. In this work, we employ novel diversity measurement and control paradigms to study the impact of behavioral heterogeneity in several facets of collective artificial learning. Through experiments in team play and other cooperative tasks, we show the emergence of unbiased behavioral roles that improve team outcomes; how neural diversity synergizes with morphological diversity; how diverse agents are more effective at finding cooperative solutions in sparse reward settings; and how behaviorally heterogeneous teams learn and retain latent skills to overcome repeated disruptions. Overall, our results indicate that, by controlling diversity, we can obtain non-trivial benefits over homogeneous training paradigms, demonstrating that diversity is a fundamental component of collective artificial learning, an insight thus far overlooked.
Controlling Behavioral Diversity in Multi-Agent Reinforcement Learning
May 23, 2024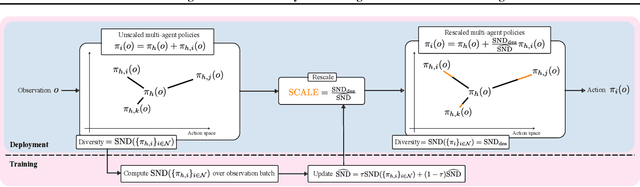
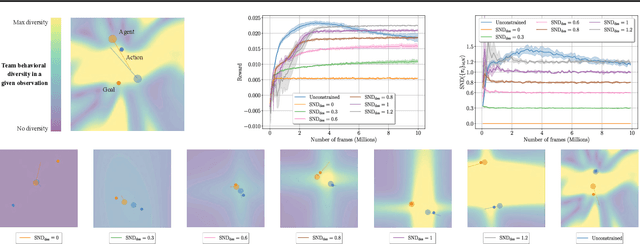
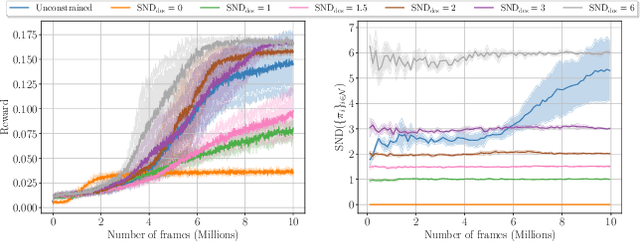
The study of behavioral diversity in Multi-Agent Reinforcement Learning (MARL) is a nascent yet promising field. In this context, the present work deals with the question of how to control the diversity of a multi-agent system. With no existing approaches to control diversity to a set value, current solutions focus on blindly promoting it via intrinsic rewards or additional loss functions, effectively changing the learning objective and lacking a principled measure for it. To address this, we introduce Diversity Control (DiCo), a method able to control diversity to an exact value of a given metric by representing policies as the sum of a parameter-shared component and dynamically scaled per-agent components. By applying constraints directly to the policy architecture, DiCo leaves the learning objective unchanged, enabling its applicability to any actor-critic MARL algorithm. We theoretically prove that DiCo achieves the desired diversity, and we provide several experiments, both in cooperative and competitive tasks, that show how DiCo can be employed as a novel paradigm to increase performance and sample efficiency in MARL. Multimedia results are available on the paper's website: https://sites.google.com/view/dico-marl.
Revisiting Recurrent Reinforcement Learning with Memory Monoids
Feb 15, 2024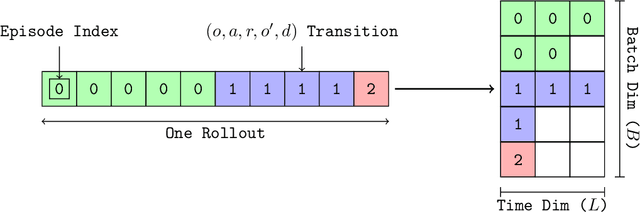
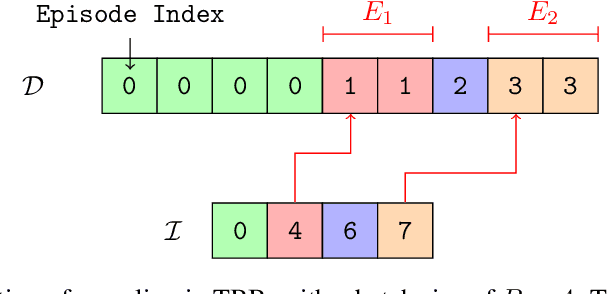
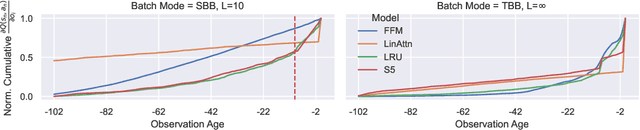

In RL, memory models such as RNNs and transformers address Partially Observable Markov Decision Processes (POMDPs) by mapping trajectories to latent Markov states. Neither model scales particularly well to long sequences, especially compared to an emerging class of memory models sometimes called linear recurrent models. We discover that the recurrent update of these models is a monoid, leading us to formally define a novel memory monoid framework. We revisit the traditional approach to batching in recurrent RL, highlighting both theoretical and empirical deficiencies. Leveraging the properties of memory monoids, we propose a new batching method that improves sample efficiency, increases the return, and simplifies the implementation of recurrent loss functions in RL.
Modeling Aggregate Downwash Forces for Dense Multirotor Flight
Dec 06, 2023Dense formation flight with multirotor swarms is a powerful, nature-inspired flight regime with numerous applications in the realworld. However, when multirotors fly in close vertical proximity to each other, the propeller downwash from the vehicles can have a destabilising effect on each other. Unfortunately, even in a homogeneous team, an accurate model of downwash forces from one vehicle is unlikely to be sufficient for predicting aggregate forces from multiple vehicles in formation. In this work, we model the interaction patterns produced by one or more vehicles flying in close proximity to an ego-vehicle. We first present an experimental test rig designed to capture 6-DOF exogenic forces acting on a multirotor frame. We then study and characterize these measured forces as a function of the relative states of two multirotors flying various patterns in its vicinity. Our analysis captures strong non-linearities present in the aggregation of these interactions. Then, by modeling the formation as a graph, we present a novel approach for learning the force aggregation function, and contrast it against simpler linear models. Finally, we explore how our proposed models generalize when a fourth vehicle is added to the formation.
Reinforcement Learning with Fast and Forgetful Memory
Oct 06, 2023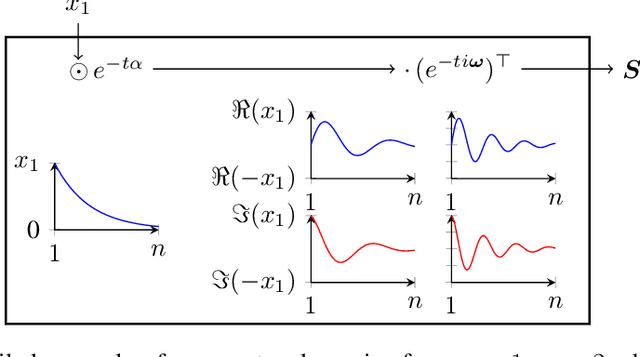
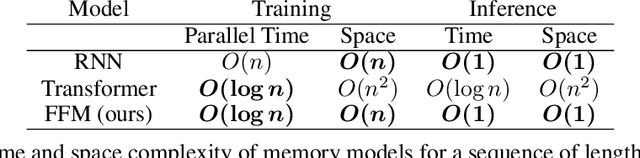
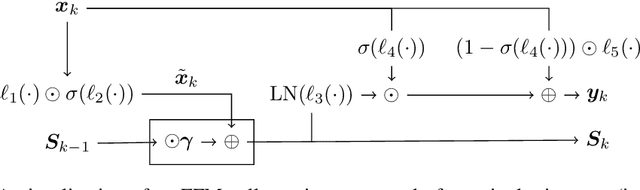
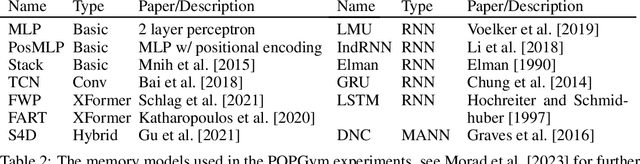
Nearly all real world tasks are inherently partially observable, necessitating the use of memory in Reinforcement Learning (RL). Most model-free approaches summarize the trajectory into a latent Markov state using memory models borrowed from Supervised Learning (SL), even though RL tends to exhibit different training and efficiency characteristics. Addressing this discrepancy, we introduce Fast and Forgetful Memory, an algorithm-agnostic memory model designed specifically for RL. Our approach constrains the model search space via strong structural priors inspired by computational psychology. It is a drop-in replacement for recurrent neural networks (RNNs) in recurrent RL algorithms, achieving greater reward than RNNs across various recurrent benchmarks and algorithms without changing any hyperparameters. Moreover, Fast and Forgetful Memory exhibits training speeds two orders of magnitude faster than RNNs, attributed to its logarithmic time and linear space complexity. Our implementation is available at https://github.com/proroklab/ffm.
Fixed Integral Neural Networks
Jul 26, 2023It is often useful to perform integration over learned functions represented by neural networks. However, this integration is usually performed numerically, as analytical integration over learned functions (especially neural networks) is generally viewed as intractable. In this work, we present a method for representing the analytical integral of a learned function $f$. This allows the exact integral of a neural network to be computed, and enables constrained neural networks to be parametrised by applying constraints directly to the integral. Crucially, we also introduce a method to constrain $f$ to be positive, a necessary condition for many applications (e.g. probability distributions, distance metrics, etc). Finally, we introduce several applications where our fixed-integral neural network (FINN) can be utilised.
Generalised $f$-Mean Aggregation for Graph Neural Networks
Jun 24, 2023
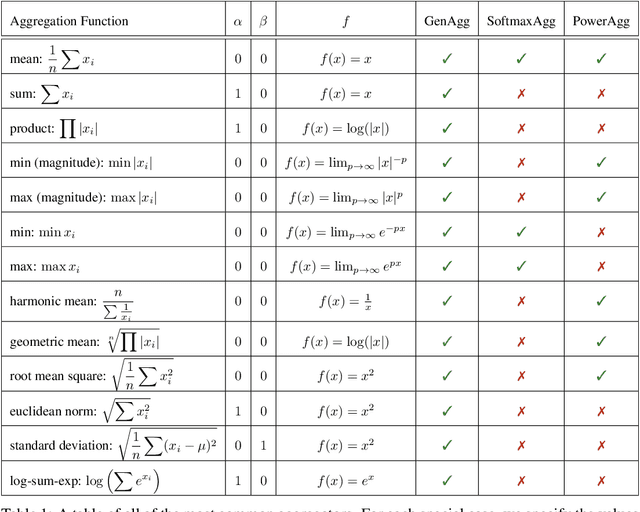

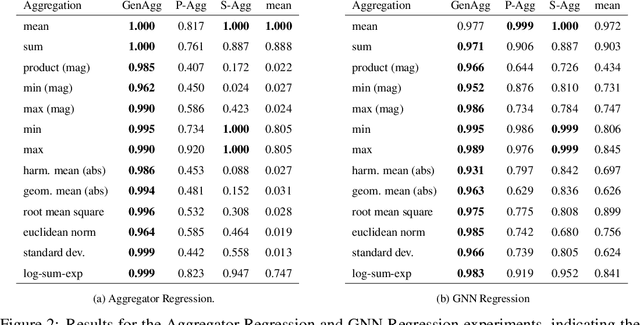
Graph Neural Network (GNN) architectures are defined by their implementations of update and aggregation modules. While many works focus on new ways to parametrise the update modules, the aggregation modules receive comparatively little attention. Because it is difficult to parametrise aggregation functions, currently most methods select a "standard aggregator" such as $\mathrm{mean}$, $\mathrm{sum}$, or $\mathrm{max}$. While this selection is often made without any reasoning, it has been shown that the choice in aggregator has a significant impact on performance, and the best choice in aggregator is problem-dependent. Since aggregation is a lossy operation, it is crucial to select the most appropriate aggregator in order to minimise information loss. In this paper, we present GenAgg, a generalised aggregation operator, which parametrises a function space that includes all standard aggregators. In our experiments, we show that GenAgg is able to represent the standard aggregators with much higher accuracy than baseline methods. We also show that using GenAgg as a drop-in replacement for an existing aggregator in a GNN often leads to a significant boost in performance across various tasks.
POPGym: Benchmarking Partially Observable Reinforcement Learning
Mar 03, 2023Real world applications of Reinforcement Learning (RL) are often partially observable, thus requiring memory. Despite this, partial observability is still largely ignored by contemporary RL benchmarks and libraries. We introduce Partially Observable Process Gym (POPGym), a two-part library containing (1) a diverse collection of 15 partially observable environments, each with multiple difficulties and (2) implementations of 13 memory model baselines -- the most in a single RL library. Existing partially observable benchmarks tend to fixate on 3D visual navigation, which is computationally expensive and only one type of POMDP. In contrast, POPGym environments are diverse, produce smaller observations, use less memory, and often converge within two hours of training on a consumer-grade GPU. We implement our high-level memory API and memory baselines on top of the popular RLlib framework, providing plug-and-play compatibility with various training algorithms, exploration strategies, and distributed training paradigms. Using POPGym, we execute the largest comparison across RL memory models to date. POPGym is available at https://github.com/proroklab/popgym.
Permutation-Invariant Set Autoencoders with Fixed-Size Embeddings for Multi-Agent Learning
Feb 24, 2023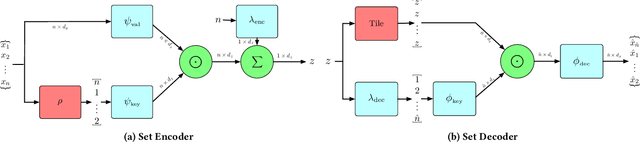
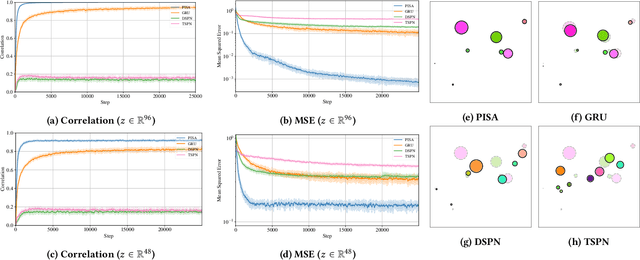
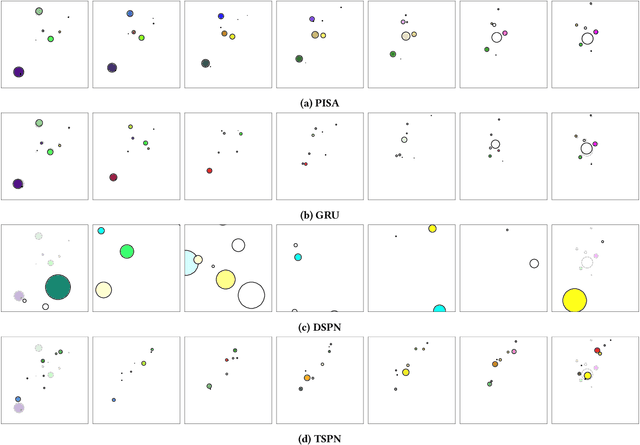
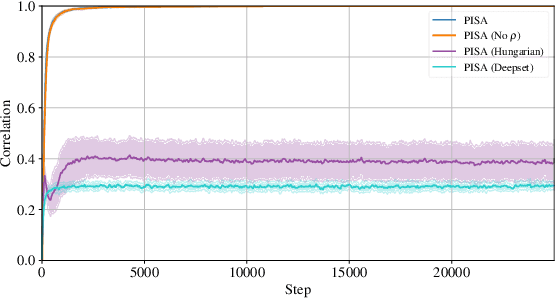
The problem of permutation-invariant learning over set representations is particularly relevant in the field of multi-agent systems -- a few potential applications include unsupervised training of aggregation functions in graph neural networks (GNNs), neural cellular automata on graphs, and prediction of scenes with multiple objects. Yet existing approaches to set encoding and decoding tasks present a host of issues, including non-permutation-invariance, fixed-length outputs, reliance on iterative methods, non-deterministic outputs, computationally expensive loss functions, and poor reconstruction accuracy. In this paper we introduce a Permutation-Invariant Set Autoencoder (PISA), which tackles these problems and produces encodings with significantly lower reconstruction error than existing baselines. PISA also provides other desirable properties, including a similarity-preserving latent space, and the ability to insert or remove elements from the encoding. After evaluating PISA against baseline methods, we demonstrate its usefulness in a multi-agent application. Using PISA as a subcomponent, we introduce a novel GNN architecture which serves as a generalised communication scheme, allowing agents to use communication to gain full observability of a system.
VMAS: A Vectorized Multi-Agent Simulator for Collective Robot Learning
Jul 07, 2022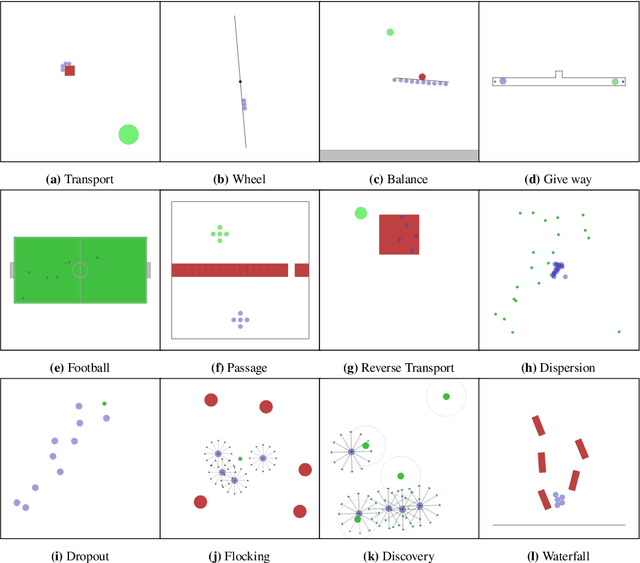
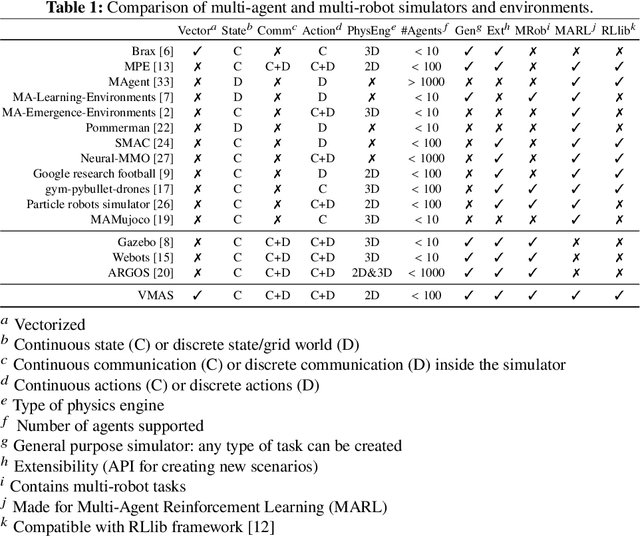
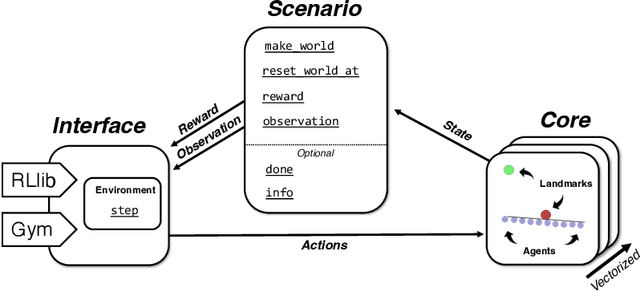
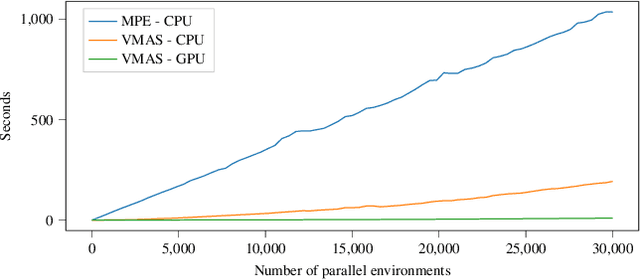
While many multi-robot coordination problems can be solved optimally by exact algorithms, solutions are often not scalable in the number of robots. Multi-Agent Reinforcement Learning (MARL) is gaining increasing attention in the robotics community as a promising solution to tackle such problems. Nevertheless, we still lack the tools that allow us to quickly and efficiently find solutions to large-scale collective learning tasks. In this work, we introduce the Vectorized Multi-Agent Simulator (VMAS). VMAS is an open-source framework designed for efficient MARL benchmarking. It is comprised of a vectorized 2D physics engine written in PyTorch and a set of twelve challenging multi-robot scenarios. Additional scenarios can be implemented through a simple and modular interface. We demonstrate how vectorization enables parallel simulation on accelerated hardware without added complexity. When comparing VMAS to OpenAI MPE, we show how MPE's execution time increases linearly in the number of simulations while VMAS is able to execute 30,000 parallel simulations in under 10s, proving more than 100x faster. Using VMAS's RLlib interface, we benchmark our multi-robot scenarios using various Proximal Policy Optimization (PPO)-based MARL algorithms. VMAS's scenarios prove challenging in orthogonal ways for state-of-the-art MARL algorithms. The VMAS framework is available at https://github.com/proroklab/VectorizedMultiAgentSimulator. A video of VMAS scenarios and experiments is available at https://youtu.be/aaDRYfiesAY}{here}\footnote{\url{https://youtu.be/aaDRYfiesAY.