 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLF: Online Multi-Robot Path Planning Meets Optimal Trajectory Control
Jul 15, 2025We propose a multi-robot control paradigm to solve point-to-point navigation tasks for a team of holonomic robots with access to the full environment information. The framework invokes two processes asynchronously at high frequency: (i) a centralized, discrete, and full-horizon planner for computing collision- and deadlock-free paths rapidly, leveraging recent advances in multi-agent pathfinding (MAPF), and (ii) dynamics-aware, robot-wise optimal trajectory controllers that ensure all robots independently follow their assigned paths reliably. This hierarchical shift in planning representation from (i) discrete and coupled to (ii) continuous and decoupled domains enables the framework to maintain long-term scalable motion synthesis. As an instantiation of this idea, we present LF, which combines a fast state-of-the-art MAPF solver (LaCAM), and a robust feedback control stack (Freyja) for executing agile robot maneuvers. LF provides a robust and versatile mechanism for lifelong multi-robot navigation even under asynchronous and partial goal updates, and adapts to dynamic workspaces simply by quick replanning. We present various multirotor and ground robot demonstrations, including the deployment of 15 real multirotors with random, consecutive target updates while a person walks through the operational workspace.
D4orm: Multi-Robot Trajectories with Dynamics-aware Diffusion Denoised Deformations
Mar 15, 2025This work presents an optimization method for generating kinodynamically feasible and collision-free multi-robot trajectories that exploits an incremental denoising scheme in diffusion models. Our key insight is that high-quality trajectories can be discovered merely by denoising noisy trajectories sampled from a distribution. This approach has no learning component, relying instead on only two ingredients: a dynamical model of the robots to obtain feasible trajectories via rollout, and a score function to guide denoising with Monte Carlo gradient approximation. The proposed framework iteratively optimizes the deformation from the previous round with this denoising process, allows \textit{anytime} refinement as time permits, supports different dynamics, and benefits from GPU acceleration. Our evaluations for differential-drive and holonomic teams with up to 16 robots in 2D and 3D worlds show its ability to discover high-quality solutions faster than other black-box optimization methods such as MPPI, approximately three times faster in a 3D holonomic case with 16 robots. As evidence for feasibility, we demonstrate zero-shot deployment of the planned trajectories on eight multirotors.
Language-Conditioned Offline RL for Multi-Robot Navigation
Jul 29, 2024We present a method for developing navigation policies for multi-robot teams that interpret and follow natural language instructions. We condition these policies on embeddings from pretrained Large Language Models (LLMs), and train them via offline reinforcement learning with as little as 20 minutes of randomly-collected data. Experiments on a team of five real robots show that these policies generalize well to unseen commands, indicating an understanding of the LLM latent space. Our method requires no simulators or environment models, and produces low-latency control policies that can be deployed directly to real robots without finetuning. We provide videos of our experiments at https://sites.google.com/view/llm-marl.
The Cambridge RoboMaster: An Agile Multi-Robot Research Platform
May 03, 2024Compact robotic platforms with powerful compute and actuation capabilities are key enablers for practical, real-world deployments of multi-agent research. This article introduces a tightly integrated hardware, control, and simulation software stack on a fleet of holonomic ground robot platforms designed with this motivation. Our robots, a fleet of customised DJI Robomaster S1 vehicles, offer a balance between small robots that do not possess sufficient compute or actuation capabilities and larger robots that are unsuitable for indoor multi-robot tests. They run a modular ROS2-based optimal estimation and control stack for full onboard autonomy, contain ad-hoc peer-to-peer communication infrastructure, and can zero-shot run multi-agent reinforcement learning (MARL) policies trained in our vectorized multi-agent simulation framework. We present an in-depth review of other platforms currently available, showcase new experimental validation of our system's capabilities, and introduce case studies that highlight the versatility and reliabilty of our system as a testbed for a wide range of research demonstrations. Our system as well as supplementary material is available online: https://proroklab.github.io/cambridge-robomaster
Modeling Aggregate Downwash Forces for Dense Multirotor Flight
Dec 06, 2023Dense formation flight with multirotor swarms is a powerful, nature-inspired flight regime with numerous applications in the realworld. However, when multirotors fly in close vertical proximity to each other, the propeller downwash from the vehicles can have a destabilising effect on each other. Unfortunately, even in a homogeneous team, an accurate model of downwash forces from one vehicle is unlikely to be sufficient for predicting aggregate forces from multiple vehicles in formation. In this work, we model the interaction patterns produced by one or more vehicles flying in close proximity to an ego-vehicle. We first present an experimental test rig designed to capture 6-DOF exogenic forces acting on a multirotor frame. We then study and characterize these measured forces as a function of the relative states of two multirotors flying various patterns in its vicinity. Our analysis captures strong non-linearities present in the aggregation of these interactions. Then, by modeling the formation as a graph, we present a novel approach for learning the force aggregation function, and contrast it against simpler linear models. Finally, we explore how our proposed models generalize when a fourth vehicle is added to the formation.
Docking Multirotors in Close Proximity using Learnt Downwash Models
Nov 23, 2023Unmodeled aerodynamic disturbances pose a key challenge for multirotor flight when multiple vehicles are in close proximity to each other. However, certain missions \textit{require} two multirotors to approach each other within 1-2 body-lengths of each other and hold formation -- we consider one such practical instance: vertically docking two multirotors in the air. In this leader-follower setting, the follower experiences significant downwash interference from the leader in its final docking stages. To compensate for this, we employ a learnt downwash model online within an optimal feedback controller to accurately track a docking maneuver and then hold formation. Through real-world flights with different maneuvers, we demonstrate that this compensation is crucial for reducing the large vertical separation otherwise required by conventional/naive approaches. Our evaluations show a tracking error of less than 0.06m for the follower (a 3-4x reduction) when approaching vertically within two body-lengths of the leader. Finally, we deploy the complete system to effect a successful physical docking between two airborne multirotors in a single smooth planned trajectory.
System Neural Diversity: Measuring Behavioral Heterogeneity in Multi-Agent Learning
May 03, 2023Evolutionary science provides evidence that diversity confers resilience. Yet, traditional multi-agent reinforcement learning techniques commonly enforce homogeneity to increase training sample efficiency. When a system of learning agents is not constrained to homogeneous policies, individual agents may develop diverse behaviors, resulting in emergent complementarity that benefits the system. Despite this feat, there is a surprising lack of tools that measure behavioral diversity in systems of learning agents. Such techniques would pave the way towards understanding the impact of diversity in collective resilience and performance. In this paper, we introduce System Neural Diversity (SND): a measure of behavioral heterogeneity for multi-agent systems where agents have stochastic policies. %over a continuous state space. We discuss and prove its theoretical properties, and compare it with alternate, state-of-the-art behavioral diversity metrics used in cross-disciplinary domains. Through simulations of a variety of multi-agent tasks, we show how our metric constitutes an important diagnostic tool to analyze latent properties of behavioral heterogeneity. By comparing SND with task reward in static tasks, where the problem does not change during training, we show that it is key to understanding the effectiveness of heterogeneous vs homogeneous agents. In dynamic tasks, where the problem is affected by repeated disturbances during training, we show that heterogeneous agents are first able to learn specialized roles that allow them to cope with the disturbance, and then retain these roles when the disturbance is removed. SND allows a direct measurement of this latent resilience, while other proxies such as task performance (reward) fail to.
Heterogeneous Multi-Robot Reinforcement Learning
Jan 17, 2023Cooperative multi-robot tasks can benefit from heterogeneity in the robots' physical and behavioral traits. In spite of this, traditional Multi-Agent Reinforcement Learning (MARL) frameworks lack the ability to explicitly accommodate policy heterogeneity, and typically constrain agents to share neural network parameters. This enforced homogeneity limits application in cases where the tasks benefit from heterogeneous behaviors. In this paper, we crystallize the role of heterogeneity in MARL policies. Towards this end, we introduce Heterogeneous Graph Neural Network Proximal Policy Optimization (HetGPPO), a paradigm for training heterogeneous MARL policies that leverages a Graph Neural Network for differentiable inter-agent communication. HetGPPO allows communicating agents to learn heterogeneous behaviors while enabling fully decentralized training in partially observable environments. We complement this with a taxonomical overview that exposes more heterogeneity classes than previously identified. To motivate the need for our model, we present a characterization of techniques that homogeneous models can leverage to emulate heterogeneous behavior, and show how this "apparent heterogeneity" is brittle in real-world conditions. Through simulations and real-world experiments, we show that: (i) when homogeneous methods fail due to strong heterogeneous requirements, HetGPPO succeeds, and, (ii) when homogeneous methods are able to learn apparently heterogeneous behaviors, HetGPPO achieves higher resilience to both training and deployment noise.
A Critical Review of Communications in Multi-Robot Systems
Jun 19, 2022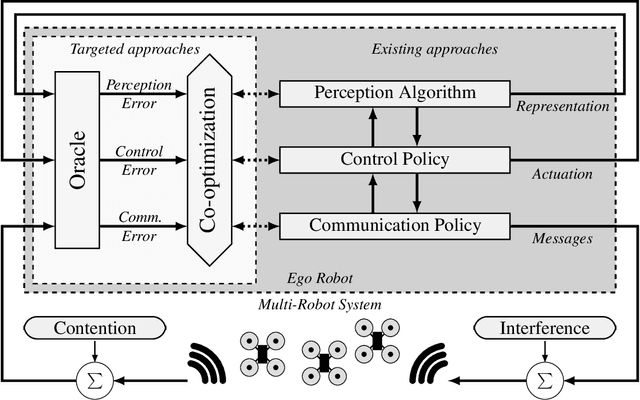
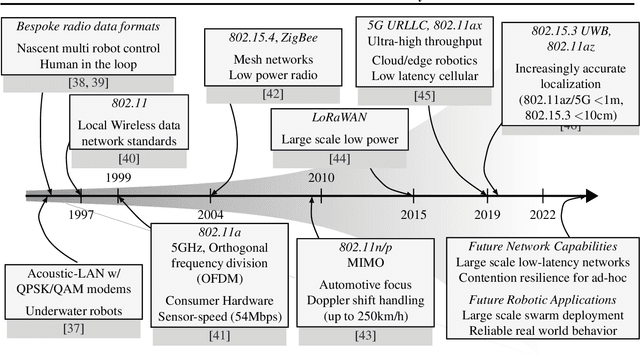
Purpose of Review. This review summarizes the broad roles that communication formats and technologies have played in enabling multi-robot systems. We approach this field from two perspectives: of robotic applications that need communication capabilities in order to accomplish tasks, and of networking technologies that have enabled newer and more advanced multi-robot systems. Recent Findings. Through this review, we identify a dearth of work that holistically tackles the problem of co-design and co-optimization of robots and the networks they employ. We also highlight the role that data-driven and machine learning approaches play in evolving communication pipelines for multi-robot systems. In particular, we refer to recent work that diverges from hand-designed communication patterns, and also discuss the "sim-to-real" gap in this context. Summary. We present a critical view of the way robotic algorithms and their networking systems have evolved, and make the case for a more synergistic approach. Finally, we also identify four broad Open Problems for research and development, while offering a data-driven perspective for solving some of them.