 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
Feb 12, 2026We introduce Gaia2, a benchmark for evaluating large language model agents in realistic, asynchronous environments. Unlike prior static or synchronous evaluations, Gaia2 introduces scenarios where environments evolve independently of agent actions, requiring agents to operate under temporal constraints, adapt to noisy and dynamic events, resolve ambiguity, and collaborate with other agents. Each scenario is paired with a write-action verifier, enabling fine-grained, action-level evaluation and making Gaia2 directly usable for reinforcement learning from verifiable rewards. Our evaluation of state-of-the-art proprietary and open-source models shows that no model dominates across capabilities: GPT-5 (high) reaches the strongest overall score of 42% pass@1 but fails on time-sensitive tasks, Claude-4 Sonnet trades accuracy and speed for cost, Kimi-K2 leads among open-source models with 21% pass@1. These results highlight fundamental trade-offs between reasoning, efficiency, robustness, and expose challenges in closing the "sim2real" gap. Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform and designed to be easy to extend. By releasing Gaia2 alongside the foundational ARE framework, we aim to provide the community with a flexible infrastructure for developing, benchmarking, and training the next generation of practical agent systems.
When Is Diversity Rewarded in Cooperative Multi-Agent Learning?
Jun 11, 2025The success of teams in robotics, nature, and society often depends on the division of labor among diverse specialists; however, a principled explanation for when such diversity surpasses a homogeneous team is still missing. Focusing on multi-agent task allocation problems, our goal is to study this question from the perspective of reward design: what kinds of objectives are best suited for heterogeneous teams? We first consider an instantaneous, non-spatial setting where the global reward is built by two generalized aggregation operators: an inner operator that maps the $N$ agents' effort allocations on individual tasks to a task score, and an outer operator that merges the $M$ task scores into the global team reward. We prove that the curvature of these operators determines whether heterogeneity can increase reward, and that for broad reward families this collapses to a simple convexity test. Next, we ask what incentivizes heterogeneity to emerge when embodied, time-extended agents must learn an effort allocation policy. To study heterogeneity in such settings, we use multi-agent reinforcement learning (MARL) as our computational paradigm, and introduce Heterogeneous Environment Design (HED), a gradient-based algorithm that optimizes the parameter space of underspecified MARL environments to find scenarios where heterogeneity is advantageous. Experiments in matrix games and an embodied Multi-Goal-Capture environment show that, despite the difference in settings, HED rediscovers the reward regimes predicted by our theory to maximize the advantage of heterogeneity, both validating HED and connecting our theoretical insights to reward design in MARL. Together, these results help us understand when behavioral diversity delivers a measurable benefit.
Neural diversity is key to collective artificial learning
Dec 19, 2024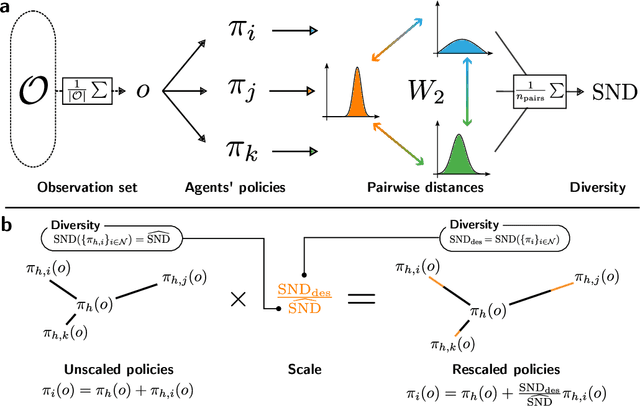
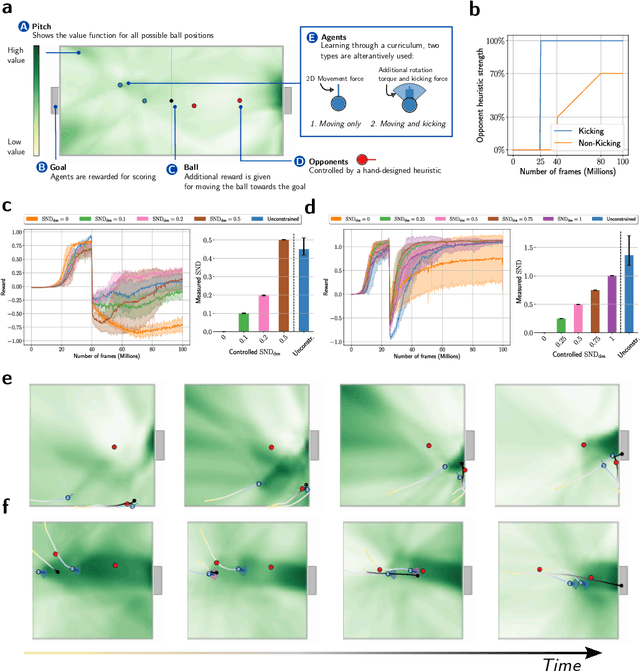
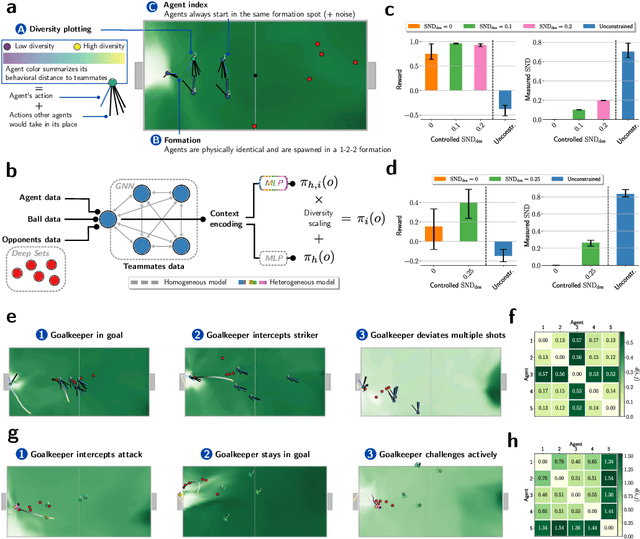
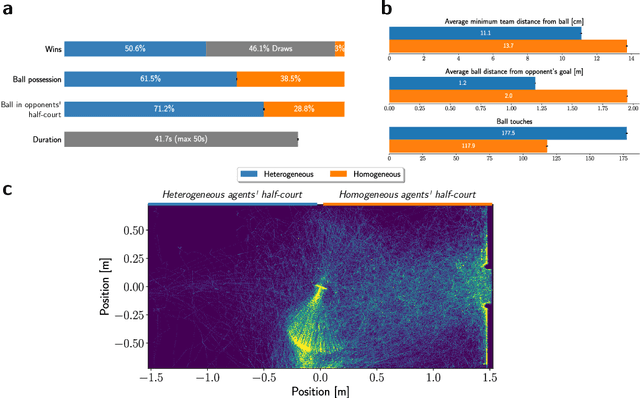
Many of the world's most pressing issues, such as climate change and global peace, require complex collective problem-solving skills. Recent studies indicate that diversity in individuals' behaviors is key to developing such skills and increasing collective performance. Yet behavioral diversity in collective artificial learning is understudied, with today's machine learning paradigms commonly favoring homogeneous agent strategies over heterogeneous ones, mainly due to computational considerations. In this work, we employ novel diversity measurement and control paradigms to study the impact of behavioral heterogeneity in several facets of collective artificial learning. Through experiments in team play and other cooperative tasks, we show the emergence of unbiased behavioral roles that improve team outcomes; how neural diversity synergizes with morphological diversity; how diverse agents are more effective at finding cooperative solutions in sparse reward settings; and how behaviorally heterogeneous teams learn and retain latent skills to overcome repeated disruptions. Overall, our results indicate that, by controlling diversity, we can obtain non-trivial benefits over homogeneous training paradigms, demonstrating that diversity is a fundamental component of collective artificial learning, an insight thus far overlooked.
Controlling Behavioral Diversity in Multi-Agent Reinforcement Learning
May 23, 2024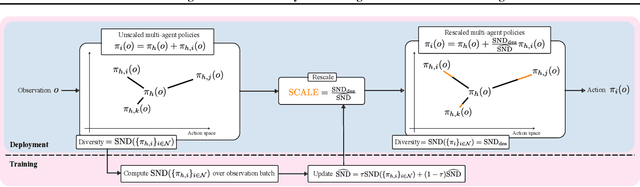
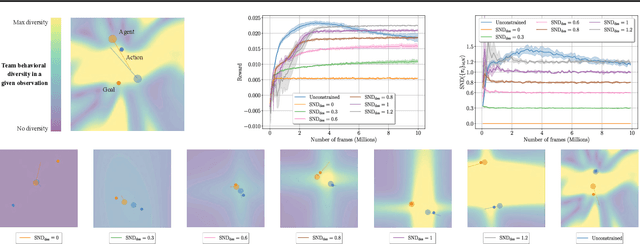
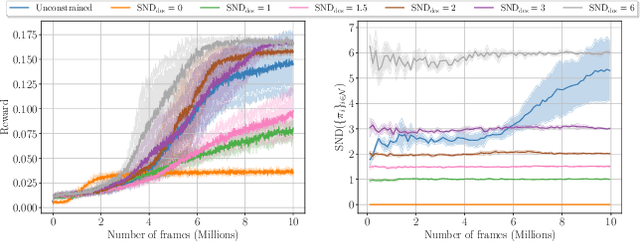
The study of behavioral diversity in Multi-Agent Reinforcement Learning (MARL) is a nascent yet promising field. In this context, the present work deals with the question of how to control the diversity of a multi-agent system. With no existing approaches to control diversity to a set value, current solutions focus on blindly promoting it via intrinsic rewards or additional loss functions, effectively changing the learning objective and lacking a principled measure for it. To address this, we introduce Diversity Control (DiCo), a method able to control diversity to an exact value of a given metric by representing policies as the sum of a parameter-shared component and dynamically scaled per-agent components. By applying constraints directly to the policy architecture, DiCo leaves the learning objective unchanged, enabling its applicability to any actor-critic MARL algorithm. We theoretically prove that DiCo achieves the desired diversity, and we provide several experiments, both in cooperative and competitive tasks, that show how DiCo can be employed as a novel paradigm to increase performance and sample efficiency in MARL. Multimedia results are available on the paper's website: https://sites.google.com/view/dico-marl.
The Cambridge RoboMaster: An Agile Multi-Robot Research Platform
May 03, 2024



Compact robotic platforms with powerful compute and actuation capabilities are key enablers for practical, real-world deployments of multi-agent research. This article introduces a tightly integrated hardware, control, and simulation software stack on a fleet of holonomic ground robot platforms designed with this motivation. Our robots, a fleet of customised DJI Robomaster S1 vehicles, offer a balance between small robots that do not possess sufficient compute or actuation capabilities and larger robots that are unsuitable for indoor multi-robot tests. They run a modular ROS2-based optimal estimation and control stack for full onboard autonomy, contain ad-hoc peer-to-peer communication infrastructure, and can zero-shot run multi-agent reinforcement learning (MARL) policies trained in our vectorized multi-agent simulation framework. We present an in-depth review of other platforms currently available, showcase new experimental validation of our system's capabilities, and introduce case studies that highlight the versatility and reliabilty of our system as a testbed for a wide range of research demonstrations. Our system as well as supplementary material is available online: https://proroklab.github.io/cambridge-robomaster
BenchMARL: Benchmarking Multi-Agent Reinforcement Learning
Dec 03, 2023The field of Multi-Agent Reinforcement Learning (MARL) is currently facing a reproducibility crisis. While solutions for standardized reporting have been proposed to address the issue, we still lack a benchmarking tool that enables standardization and reproducibility, while leveraging cutting-edge Reinforcement Learning (RL) implementations. In this paper, we introduce BenchMARL, the first MARL training library created to enable standardized benchmarking across different algorithms, models, and environments. BenchMARL uses TorchRL as its backend, granting it high performance and maintained state-of-the-art implementations while addressing the broad community of MARL PyTorch users. Its design enables systematic configuration and reporting, thus allowing users to create and run complex benchmarks from simple one-line inputs. BenchMARL is open-sourced on GitHub: https://github.com/facebookresearch/BenchMARL
TorchRL: A data-driven decision-making library for PyTorch
Jun 01, 2023Striking a balance between integration and modularity is crucial for a machine learning library to be versatile and user-friendly, especially in handling decision and control tasks that involve large development teams and complex, real-world data, and environments. To address this issue, we propose TorchRL, a generalistic control library for PyTorch that provides well-integrated, yet standalone components. With a versatile and robust primitive design, TorchRL facilitates streamlined algorithm development across the many branches of Reinforcement Learning (RL) and control. We introduce a new PyTorch primitive, TensorDict, as a flexible data carrier that empowers the integration of the library's components while preserving their modularity. Hence replay buffers, datasets, distributed data collectors, environments, transforms and objectives can be effortlessly used in isolation or combined. We provide a detailed description of the building blocks, supporting code examples and an extensive overview of the library across domains and tasks. Finally, we show comparative benchmarks to demonstrate its computational efficiency. TorchRL fosters long-term support and is publicly available on GitHub for greater reproducibility and collaboration within the research community. The code is opensourced on https://github.com/pytorch/rl.
System Neural Diversity: Measuring Behavioral Heterogeneity in Multi-Agent Learning
May 03, 2023Evolutionary science provides evidence that diversity confers resilience. Yet, traditional multi-agent reinforcement learning techniques commonly enforce homogeneity to increase training sample efficiency. When a system of learning agents is not constrained to homogeneous policies, individual agents may develop diverse behaviors, resulting in emergent complementarity that benefits the system. Despite this feat, there is a surprising lack of tools that measure behavioral diversity in systems of learning agents. Such techniques would pave the way towards understanding the impact of diversity in collective resilience and performance. In this paper, we introduce System Neural Diversity (SND): a measure of behavioral heterogeneity for multi-agent systems where agents have stochastic policies. %over a continuous state space. We discuss and prove its theoretical properties, and compare it with alternate, state-of-the-art behavioral diversity metrics used in cross-disciplinary domains. Through simulations of a variety of multi-agent tasks, we show how our metric constitutes an important diagnostic tool to analyze latent properties of behavioral heterogeneity. By comparing SND with task reward in static tasks, where the problem does not change during training, we show that it is key to understanding the effectiveness of heterogeneous vs homogeneous agents. In dynamic tasks, where the problem is affected by repeated disturbances during training, we show that heterogeneous agents are first able to learn specialized roles that allow them to cope with the disturbance, and then retain these roles when the disturbance is removed. SND allows a direct measurement of this latent resilience, while other proxies such as task performance (reward) fail to.
POPGym: Benchmarking Partially Observable Reinforcement Learning
Mar 03, 2023Real world applications of Reinforcement Learning (RL) are often partially observable, thus requiring memory. Despite this, partial observability is still largely ignored by contemporary RL benchmarks and libraries. We introduce Partially Observable Process Gym (POPGym), a two-part library containing (1) a diverse collection of 15 partially observable environments, each with multiple difficulties and (2) implementations of 13 memory model baselines -- the most in a single RL library. Existing partially observable benchmarks tend to fixate on 3D visual navigation, which is computationally expensive and only one type of POMDP. In contrast, POPGym environments are diverse, produce smaller observations, use less memory, and often converge within two hours of training on a consumer-grade GPU. We implement our high-level memory API and memory baselines on top of the popular RLlib framework, providing plug-and-play compatibility with various training algorithms, exploration strategies, and distributed training paradigms. Using POPGym, we execute the largest comparison across RL memory models to date. POPGym is available at https://github.com/proroklab/popgym.
Heterogeneous Multi-Robot Reinforcement Learning
Jan 17, 2023Cooperative multi-robot tasks can benefit from heterogeneity in the robots' physical and behavioral traits. In spite of this, traditional Multi-Agent Reinforcement Learning (MARL) frameworks lack the ability to explicitly accommodate policy heterogeneity, and typically constrain agents to share neural network parameters. This enforced homogeneity limits application in cases where the tasks benefit from heterogeneous behaviors. In this paper, we crystallize the role of heterogeneity in MARL policies. Towards this end, we introduce Heterogeneous Graph Neural Network Proximal Policy Optimization (HetGPPO), a paradigm for training heterogeneous MARL policies that leverages a Graph Neural Network for differentiable inter-agent communication. HetGPPO allows communicating agents to learn heterogeneous behaviors while enabling fully decentralized training in partially observable environments. We complement this with a taxonomical overview that exposes more heterogeneity classes than previously identified. To motivate the need for our model, we present a characterization of techniques that homogeneous models can leverage to emulate heterogeneous behavior, and show how this "apparent heterogeneity" is brittle in real-world conditions. Through simulations and real-world experiments, we show that: (i) when homogeneous methods fail due to strong heterogeneous requirements, HetGPPO succeeds, and, (ii) when homogeneous methods are able to learn apparently heterogeneous behaviors, HetGPPO achieves higher resilience to both training and deployment noise.