 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Do Not Simulate Human Psychology
Aug 13, 2025Large Language Models (LLMs),such as ChatGPT, are increasingly used in research, ranging from simple writing assistance to complex data annotation tasks. Recently, some research has suggested that LLMs may even be able to simulate human psychology and can, hence, replace human participants in psychological studies. We caution against this approach. We provide conceptual arguments against the hypothesis that LLMs simulate human psychology. We then present empiric evidence illustrating our arguments by demonstrating that slight changes to wording that correspond to large changes in meaning lead to notable discrepancies between LLMs' and human responses, even for the recent CENTAUR model that was specifically fine-tuned on psychological responses. Additionally, different LLMs show very different responses to novel items, further illustrating their lack of reliability. We conclude that LLMs do not simulate human psychology and recommend that psychological researchers should treat LLMs as useful but fundamentally unreliable tools that need to be validated against human responses for every new application.
When Bias Backfires: The Modulatory Role of Counterfactual Explanations on the Adoption of Algorithmic Bias in XAI-Supported Human Decision-Making
May 20, 2025Although the integration of artificial intelligence (AI) into everyday tasks improves efficiency and objectivity, it also risks transmitting bias to human decision-making. In this study, we conducted a controlled experiment that simulated hiring decisions to examine how biased AI recommendations - augmented with or without counterfactual explanations - influence human judgment over time. Participants, acting as hiring managers, completed 60 decision trials divided into a baseline phase without AI, followed by a phase with biased (X)AI recommendations (favoring either male or female candidates), and a final post-interaction phase without AI. Our results indicate that the participants followed the AI recommendations 70% of the time when the qualifications of the given candidates were comparable. Yet, only a fraction of participants detected the gender bias (8 out of 294). Crucially, exposure to biased AI altered participants' inherent preferences: in the post-interaction phase, participants' independent decisions aligned with the bias when no counterfactual explanations were provided before, but reversed the bias when explanations were given. Reported trust did not differ significantly across conditions. Confidence varied throughout the study phases after exposure to male-biased AI, indicating nuanced effects of AI bias on decision certainty. Our findings point to the importance of calibrating XAI to avoid unintended behavioral shifts in order to safeguard equitable decision-making and prevent the adoption of algorithmic bias.
Interpretable Event Diagnosis in Water Distribution Networks
May 12, 2025The increasing penetration of information and communication technologies in the design, monitoring, and control of water systems enables the use of algorithms for detecting and identifying unanticipated events (such as leakages or water contamination) using sensor measurements. However, data-driven methodologies do not always give accurate results and are often not trusted by operators, who may prefer to use their engineering judgment and experience to deal with such events. In this work, we propose a framework for interpretable event diagnosis -- an approach that assists the operators in associating the results of algorithmic event diagnosis methodologies with their own intuition and experience. This is achieved by providing contrasting (i.e., counterfactual) explanations of the results provided by fault diagnosis algorithms; their aim is to improve the understanding of the algorithm's inner workings by the operators, thus enabling them to take a more informed decision by combining the results with their personal experiences. Specifically, we propose counterfactual event fingerprints, a representation of the difference between the current event diagnosis and the closest alternative explanation, which can be presented in a graphical way. The proposed methodology is applied and evaluated on a realistic use case using the L-Town benchmark.
Toward enriched Cognitive Learning with XAI
Dec 19, 2023As computational systems supported by artificial intelligence (AI) techniques continue to play an increasingly pivotal role in making high-stakes recommendations and decisions across various domains, the demand for explainable AI (XAI) has grown significantly, extending its impact into cognitive learning research. Providing explanations for novel concepts is recognised as a fundamental aid in the learning process, particularly when addressing challenges stemming from knowledge deficiencies and skill application. Addressing these difficulties involves timely explanations and guidance throughout the learning process, prompting the interest of AI experts in developing explainer models. In this paper, we introduce an intelligent system (CL-XAI) for Cognitive Learning which is supported by XAI, focusing on two key research objectives: exploring how human learners comprehend the internal mechanisms of AI models using XAI tools and evaluating the effectiveness of such tools through human feedback. The use of CL-XAI is illustrated with a game-inspired virtual use case where learners tackle combinatorial problems to enhance problem-solving skills and deepen their understanding of complex concepts, highlighting the potential for transformative advances in cognitive learning and co-learning.
For Better or Worse: The Impact of Counterfactual Explanations' Directionality on User Behavior in xAI
Jun 13, 2023Counterfactual explanations (CFEs) are a popular approach in explainable artificial intelligence (xAI), highlighting changes to input data necessary for altering a model's output. A CFE can either describe a scenario that is better than the factual state (upward CFE), or a scenario that is worse than the factual state (downward CFE). However, potential benefits and drawbacks of the directionality of CFEs for user behavior in xAI remain unclear. The current user study (N=161) compares the impact of CFE directionality on behavior and experience of participants tasked to extract new knowledge from an automated system based on model predictions and CFEs. Results suggest that upward CFEs provide a significant performance advantage over other forms of counterfactual feedback. Moreover, the study highlights potential benefits of mixed CFEs improving user performance compared to downward CFEs or no explanations. In line with the performance results, users' explicit knowledge of the system is statistically higher after receiving upward CFEs compared to downward comparisons. These findings imply that the alignment between explanation and task at hand, the so-called regulatory fit, may play a crucial role in determining the effectiveness of model explanations, informing future research directions in xAI. To ensure reproducible research, the entire code, underlying models and user data of this study is openly available: https://github.com/ukuhl/DirectionalAlienZoo
Keep Your Friends Close and Your Counterfactuals Closer: Improved Learning From Closest Rather Than Plausible Counterfactual Explanations in an Abstract Setting
May 11, 2022

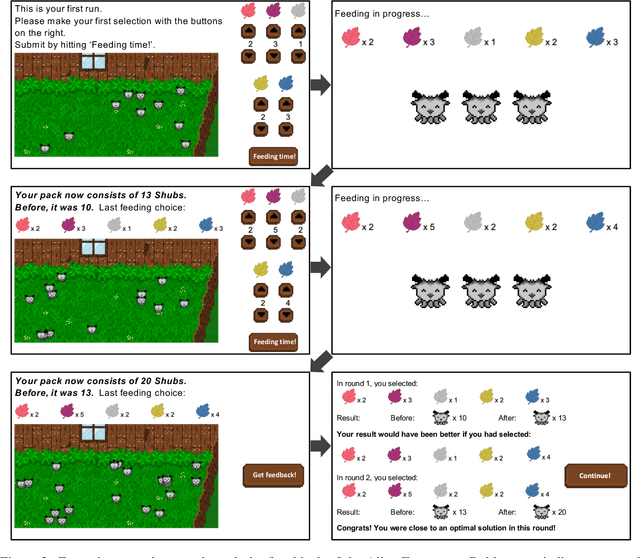
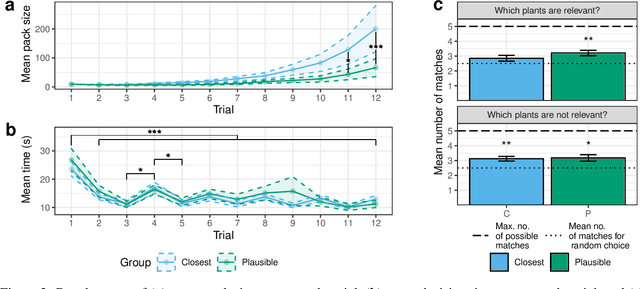
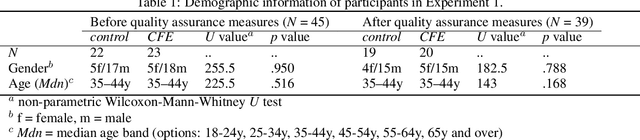
Counterfactual explanations (CFEs) highlight what changes to a model's input would have changed its prediction in a particular way. CFEs have gained considerable traction as a psychologically grounded solution for explainable artificial intelligence (XAI). Recent innovations introduce the notion of computational plausibility for automatically generated CFEs, enhancing their robustness by exclusively creating plausible explanations. However, practical benefits of such a constraint on user experience and behavior is yet unclear. In this study, we evaluate objective and subjective usability of computationally plausible CFEs in an iterative learning design targeting novice users. We rely on a novel, game-like experimental design, revolving around an abstract scenario. Our results show that novice users actually benefit less from receiving computationally plausible rather than closest CFEs that produce minimal changes leading to the desired outcome. Responses in a post-game survey reveal no differences in terms of subjective user experience between both groups. Following the view of psychological plausibility as comparative similarity, this may be explained by the fact that users in the closest condition experience their CFEs as more psychologically plausible than the computationally plausible counterpart. In sum, our work highlights a little-considered divergence of definitions of computational plausibility and psychological plausibility, critically confirming the need to incorporate human behavior, preferences and mental models already at the design stages of XAI approaches. In the interest of reproducible research, all source code, acquired user data, and evaluation scripts of the current study are available: https://github.com/ukuhl/PlausibleAlienZoo
Let's Go to the Alien Zoo: Introducing an Experimental Framework to Study Usability of Counterfactual Explanations for Machine Learning
May 06, 2022
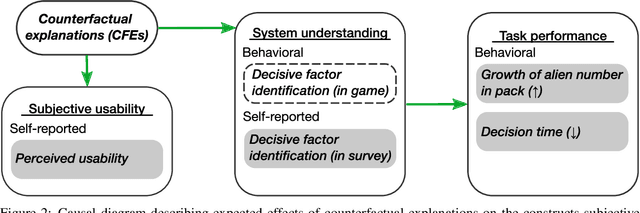
To foster usefulness and accountability of machine learning (ML), it is essential to explain a model's decisions in addition to evaluating its performance. Accordingly, the field of explainable artificial intelligence (XAI) has resurfaced as a topic of active research, offering approaches to address the "how" and "why" of automated decision-making. Within this domain, counterfactual explanations (CFEs) have gained considerable traction as a psychologically grounded approach to generate post-hoc explanations. To do so, CFEs highlight what changes to a model's input would have changed its prediction in a particular way. However, despite the introduction of numerous CFE approaches, their usability has yet to be thoroughly validated at the human level. Thus, to advance the field of XAI, we introduce the Alien Zoo, an engaging, web-based and game-inspired experimental framework. The Alien Zoo provides the means to evaluate usability of CFEs for gaining new knowledge from an automated system, targeting novice users in a domain-general context. As a proof of concept, we demonstrate the practical efficacy and feasibility of this approach in a user study. Our results suggest that users benefit from receiving CFEs compared to no explanation, both in terms of objective performance in the proposed iterative learning task, and subjective usability. With this work, we aim to equip research groups and practitioners with the means to easily run controlled and well-powered user studies to complement their otherwise often more technology-oriented work. Thus, in the interest of reproducible research, we provide the entire code, together with the underlying models and user data.
Intuitiveness in Active Teaching
Dec 25, 2020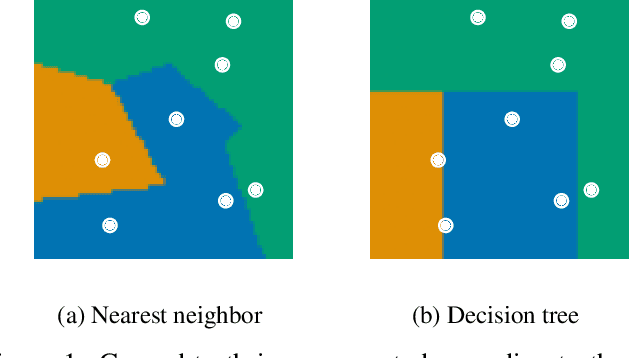
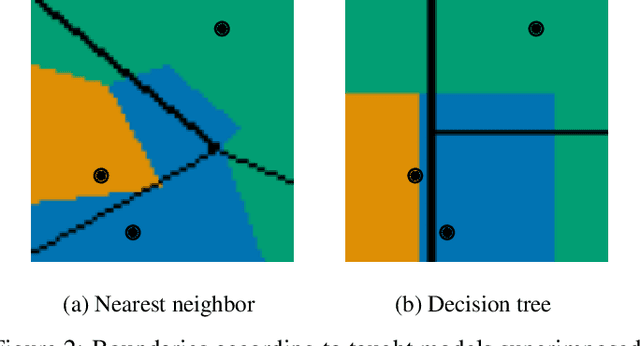
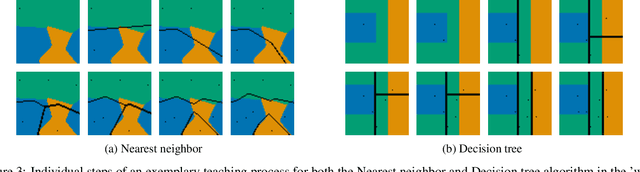
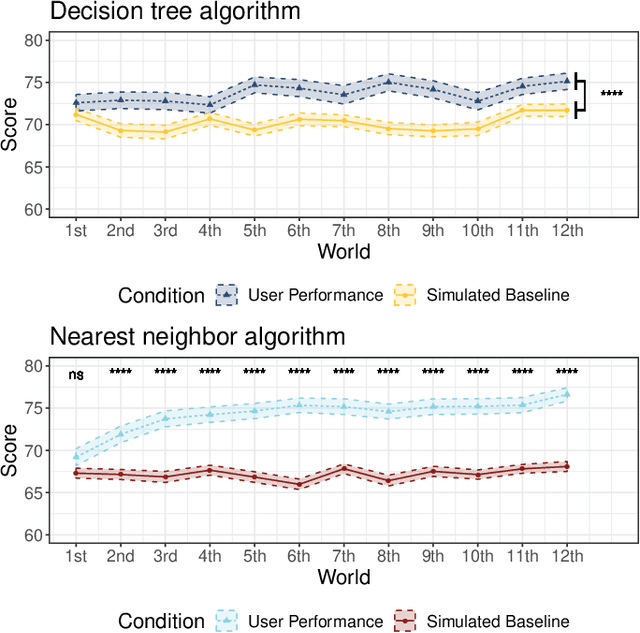
Machine learning is a double-edged sword: it gives rise to astonishing results in automated systems, but at the cost of tremendously large data requirements. This makes many successful algorithms from machine learning unsuitable for human-machine interaction, where the machine must learn from a small number of training samples that can be provided by a user within a reasonable time frame. Fortunately, the user can tailor the training data they create to be as useful as possible, severely limiting its necessary size -- as long as they know about the machine's requirements and limitations. Of course, acquiring this knowledge can in turn be cumbersome and costly. This raises the question how easy machine learning algorithms are to interact with. In this work we address this issue by analyzing the intuitiveness of certain algorithms when they are actively taught by users. After developing a theoretical framework of intuitiveness as a property of algorithms, we present and discuss the results of a large-scale user study into the performance and teaching strategies of 800 users interacting with prominent machine learning algorithms. Via this extensive examination we offer a systematic method to judge the efficacy of human-machine interactions and thus, to scrutinize how accessible, understandable, and fair, a system is.