 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFRESH: Responsible and Efficient Feature Reselection Guided by SHAP Values
Mar 13, 2024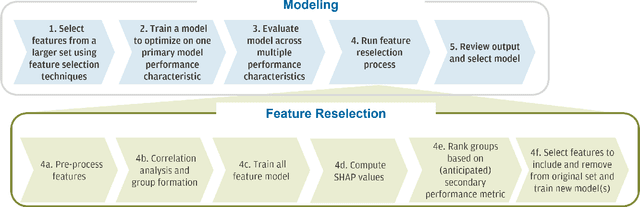


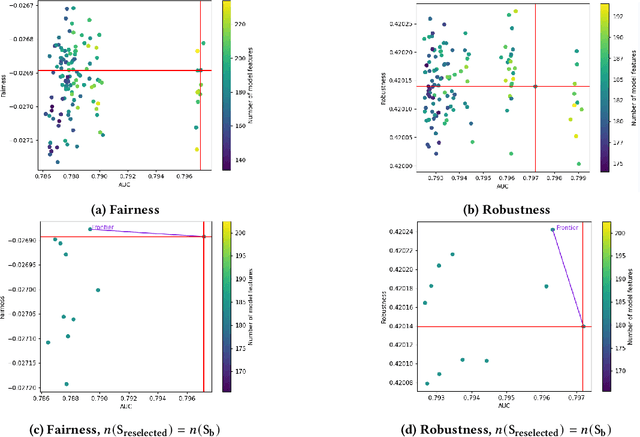
Feature selection is a crucial step in building machine learning models. This process is often achieved with accuracy as an objective, and can be cumbersome and computationally expensive for large-scale datasets. Several additional model performance characteristics such as fairness and robustness are of importance for model development. As regulations are driving the need for more trustworthy models, deployed models need to be corrected for model characteristics associated with responsible artificial intelligence. When feature selection is done with respect to one model performance characteristic (eg. accuracy), feature selection with secondary model performance characteristics (eg. fairness and robustness) as objectives would require going through the computationally expensive selection process from scratch. In this paper, we introduce the problem of feature \emph{reselection}, so that features can be selected with respect to secondary model performance characteristics efficiently even after a feature selection process has been done with respect to a primary objective. To address this problem, we propose REFRESH, a method to reselect features so that additional constraints that are desirable towards model performance can be achieved without having to train several new models. REFRESH's underlying algorithm is a novel technique using SHAP values and correlation analysis that can approximate for the predictions of a model without having to train these models. Empirical evaluations on three datasets, including a large-scale loan defaulting dataset show that REFRESH can help find alternate models with better model characteristics efficiently. We also discuss the need for reselection and REFRESH based on regulation desiderata.
On the Connection between Game-Theoretic Feature Attributions and Counterfactual Explanations
Jul 13, 2023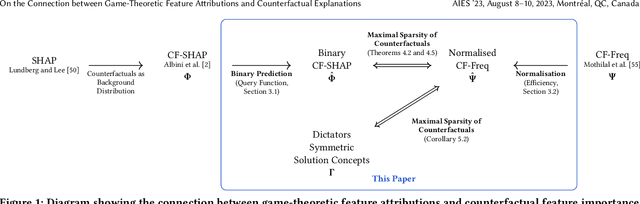


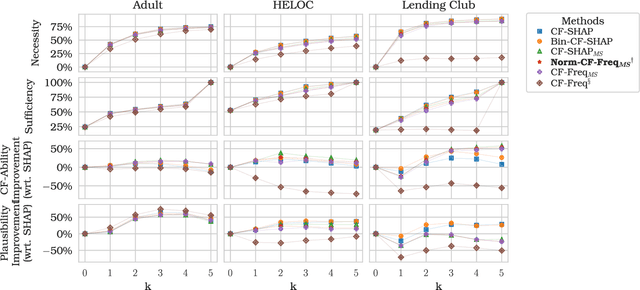
Explainable Artificial Intelligence (XAI) has received widespread interest in recent years, and two of the most popular types of explanations are feature attributions, and counterfactual explanations. These classes of approaches have been largely studied independently and the few attempts at reconciling them have been primarily empirical. This work establishes a clear theoretical connection between game-theoretic feature attributions, focusing on but not limited to SHAP, and counterfactuals explanations. After motivating operative changes to Shapley values based feature attributions and counterfactual explanations, we prove that, under conditions, they are in fact equivalent. We then extend the equivalency result to game-theoretic solution concepts beyond Shapley values. Moreover, through the analysis of the conditions of such equivalence, we shed light on the limitations of naively using counterfactual explanations to provide feature importances. Experiments on three datasets quantitatively show the difference in explanations at every stage of the connection between the two approaches and corroborate the theoretical findings.
* Accepted at AIES 2023
Counterfactual Shapley Additive Explanations
Nov 02, 2021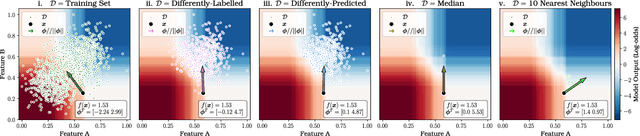

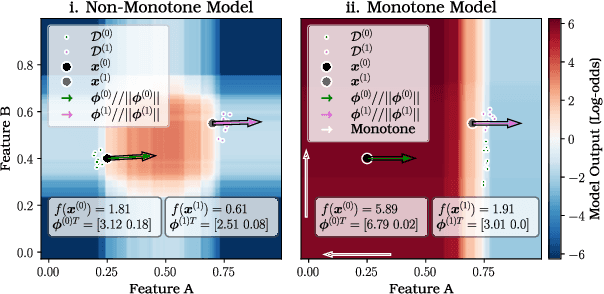
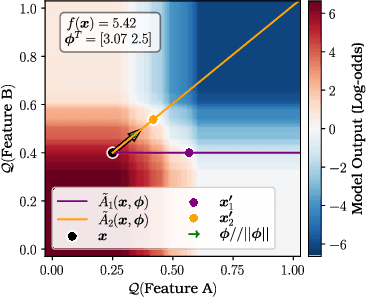
Feature attributions are a common paradigm for model explanations due to their simplicity in assigning a single numeric score for each input feature to a model. In the actionable recourse setting, wherein the goal of the explanations is to improve outcomes for model consumers, it is often unclear how feature attributions should be correctly used. With this work, we aim to strengthen and clarify the link between actionable recourse and feature attributions. Concretely, we propose a variant of SHAP, CoSHAP, that uses counterfactual generation techniques to produce a background dataset for use within the marginal (a.k.a. interventional) Shapley value framework. We motivate the need within the actionable recourse setting for careful consideration of background datasets when using Shapley values for feature attributions, alongside the requirement for monotonicity, with numerous synthetic examples. Moreover, we demonstrate the efficacy of CoSHAP by proposing and justifying a quantitative score for feature attributions, counterfactual-ability, showing that as measured by this metric, CoSHAP is superior to existing methods when evaluated on public datasets using monotone tree ensembles.
Argumentative XAI: A Survey
May 24, 2021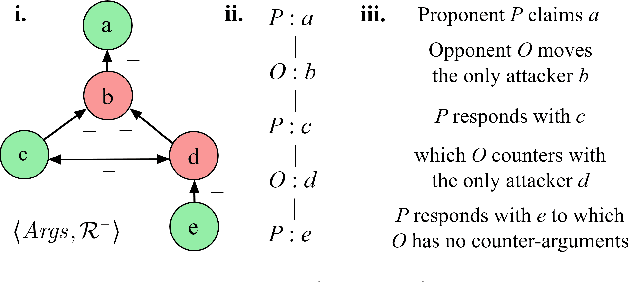
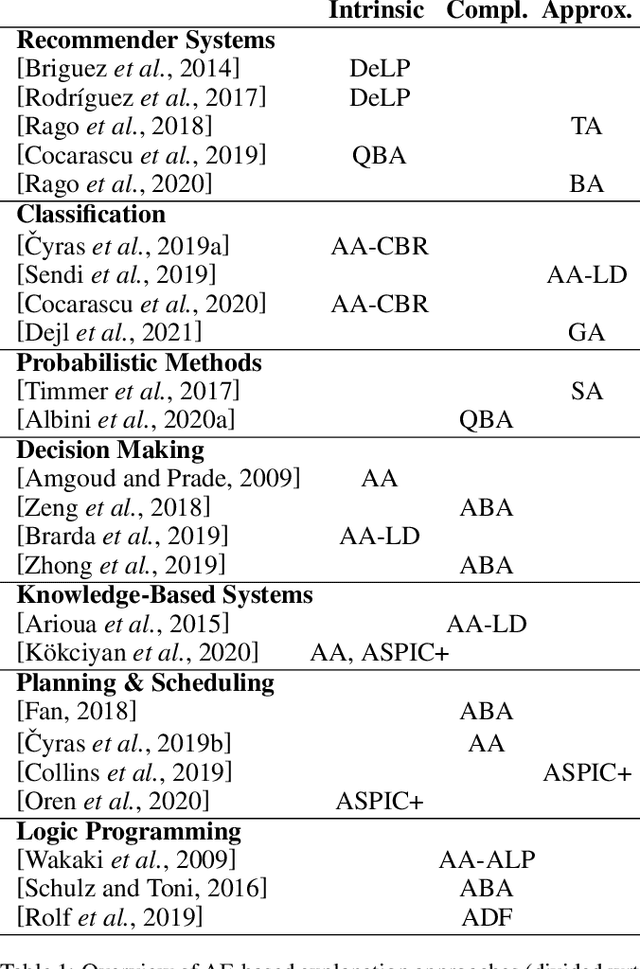
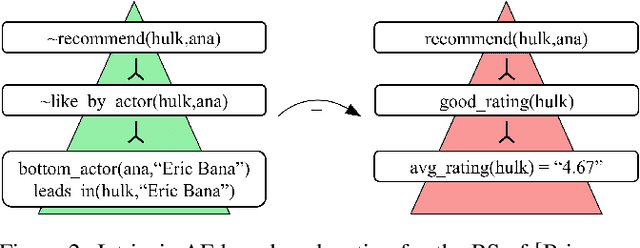

Explainable AI (XAI) has been investigated for decades and, together with AI itself, has witnessed unprecedented growth in recent years. Among various approaches to XAI, argumentative models have been advocated in both the AI and social science literature, as their dialectical nature appears to match some basic desirable features of the explanation activity. In this survey we overview XAI approaches built using methods from the field of computational argumentation, leveraging its wide array of reasoning abstractions and explanation delivery methods. We overview the literature focusing on different types of explanation (intrinsic and post-hoc), different models with which argumentation-based explanations are deployed, different forms of delivery, and different argumentation frameworks they use. We also lay out a roadmap for future work.
Influence-Driven Explanations for Bayesian Network Classifiers
Dec 10, 2020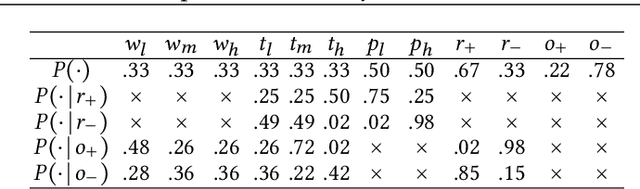
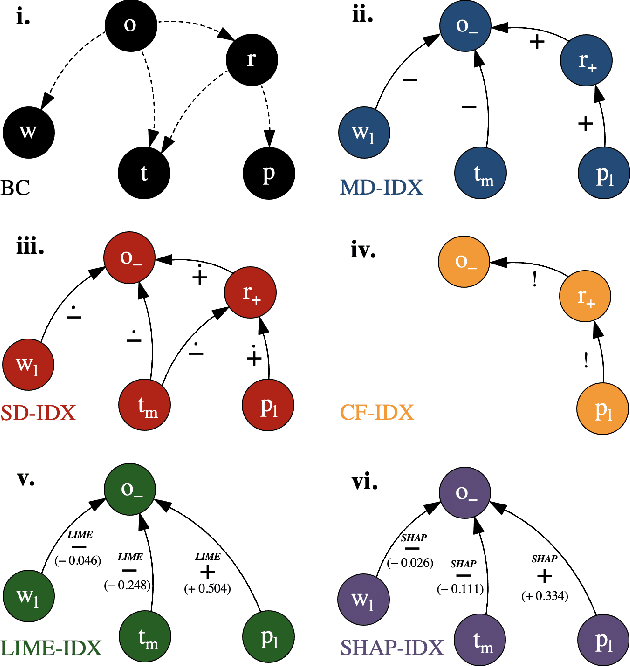
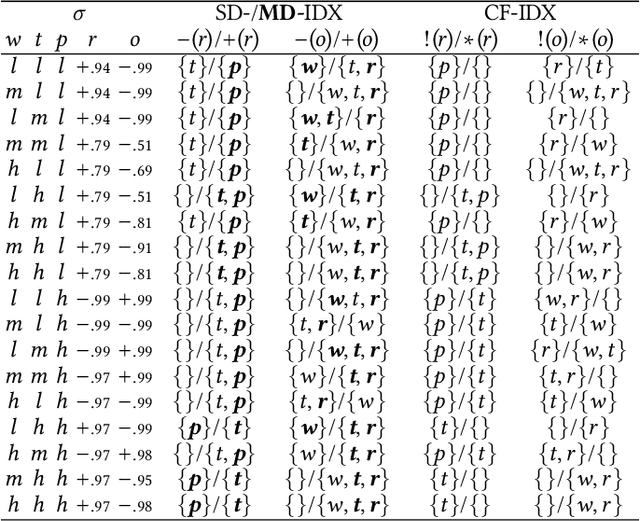
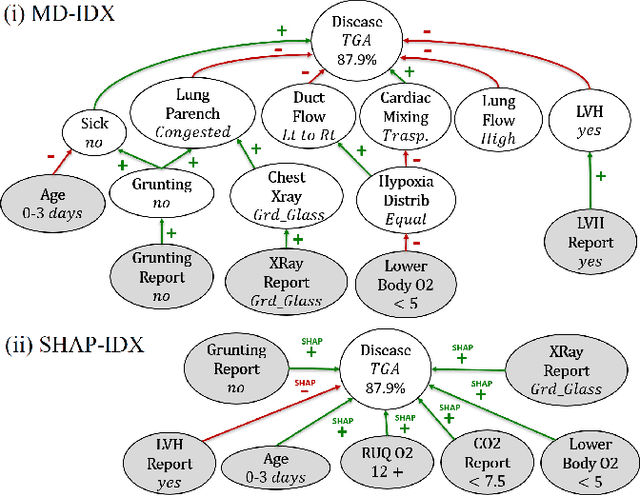
One of the most pressing issues in AI in recent years has been the need to address the lack of explainability of many of its models. We focus on explanations for discrete Bayesian network classifiers (BCs), targeting greater transparency of their inner workings by including intermediate variables in explanations, rather than just the input and output variables as is standard practice. The proposed influence-driven explanations (IDXs) for BCs are systematically generated using the causal relationships between variables within the BC, called influences, which are then categorised by logical requirements, called relation properties, according to their behaviour. These relation properties both provide guarantees beyond heuristic explanation methods and allow the information underpinning an explanation to be tailored to a particular context's and user's requirements, e.g., IDXs may be dialectical or counterfactual. We demonstrate IDXs' capability to explain various forms of BCs, e.g., naive or multi-label, binary or categorical, and also integrate recent approaches to explanations for BCs from the literature. We evaluate IDXs with theoretical and empirical analyses, demonstrating their considerable advantages when compared with existing explanation methods.
DAX: Deep Argumentative eXplanation for Neural Networks
Dec 10, 2020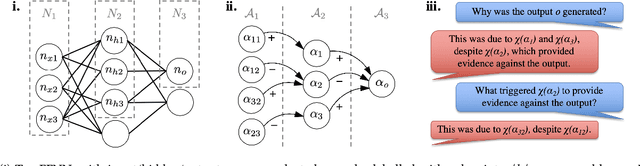

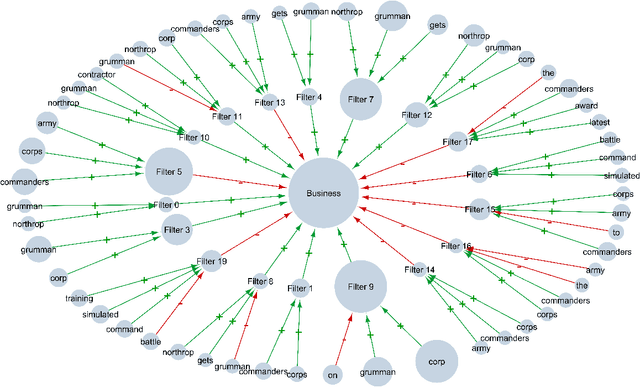
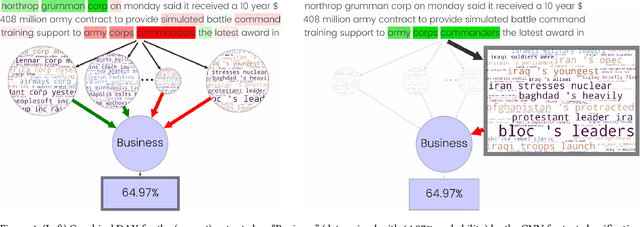
Despite the rapid growth in attention on eXplainable AI (XAI) of late, explanations in the literature provide little insight into the actual functioning of Neural Networks (NNs), significantly limiting their transparency. We propose a methodology for explaining NNs, providing transparency about their inner workings, by utilising computational argumentation (a form of symbolic AI offering reasoning abstractions for a variety of settings where opinions matter) as the scaffolding underpinning Deep Argumentative eXplanations (DAXs). We define three DAX instantiations (for various neural architectures and tasks) and evaluate them empirically in terms of stability, computational cost, and importance of depth. We also conduct human experiments with DAXs for text classification models, indicating that they are comprehensible to humans and align with their judgement, while also being competitive, in terms of user acceptance, with existing approaches to XAI that also have an argumentative spirit.