 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Idea to Implementation: Evaluating the Influence of Large Language Models in Software Development -- An Opinion Paper
Mar 10, 2025The introduction of transformer architecture was a turning point in Natural Language Processing (NLP). Models based on the transformer architecture such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-Trained Transformer (GPT) have gained widespread popularity in various applications such as software development and education. The availability of Large Language Models (LLMs) such as ChatGPT and Bard to the general public has showcased the tremendous potential of these models and encouraged their integration into various domains such as software development for tasks such as code generation, debugging, and documentation generation. In this study, opinions from 11 experts regarding their experience with LLMs for software development have been gathered and analysed to draw insights that can guide successful and responsible integration. The overall opinion of the experts is positive, with the experts identifying advantages such as increase in productivity and reduced coding time. Potential concerns and challenges such as risk of over-dependence and ethical considerations have also been highlighted.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
Slide-free MUSE Microscopy to H&E Histology Modality Conversion via Unpaired Image-to-Image Translation GAN Models
Aug 19, 2020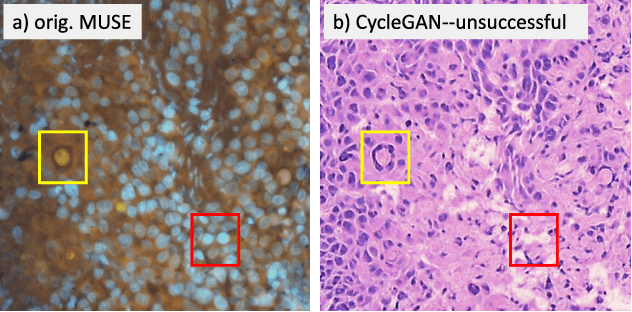
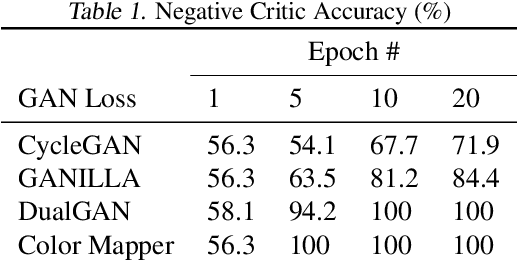
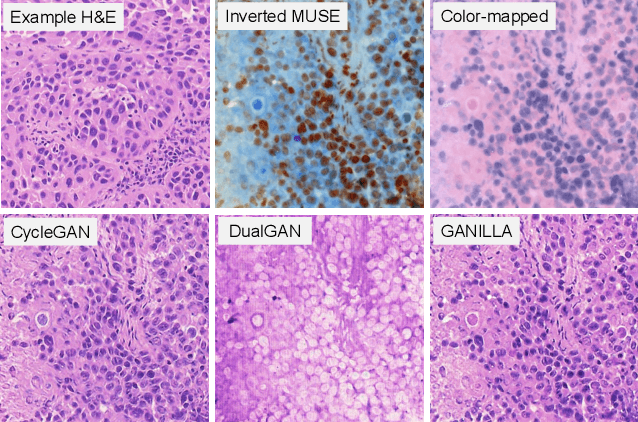
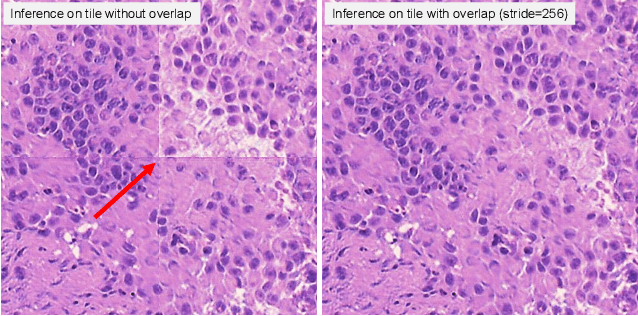
MUSE is a novel slide-free imaging technique for histological examination of tissues that can serve as an alternative to traditional histology. In order to bridge the gap between MUSE and traditional histology, we aim to convert MUSE images to resemble authentic hematoxylin- and eosin-stained (H&E) images. We evaluated four models: a non-machine-learning-based color-mapping unmixing-based tool, CycleGAN, DualGAN, and GANILLA. CycleGAN and GANILLA provided visually compelling results that appropriately transferred H&E style and preserved MUSE content. Based on training an automated critic on real and generated H&E images, we determined that CycleGAN demonstrated the best performance. We have also found that MUSE color inversion may be a necessary step for accurate modality conversion to H&E. We believe that our MUSE-to-H&E model can help improve adoption of novel slide-free methods by bridging a perceptual gap between MUSE imaging and traditional histology.