 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe infrastructure powering IBM's Gen AI model development
Jul 07, 2024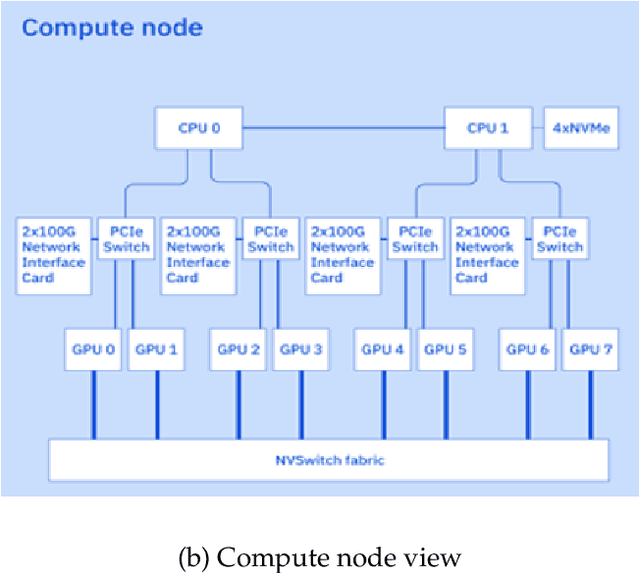
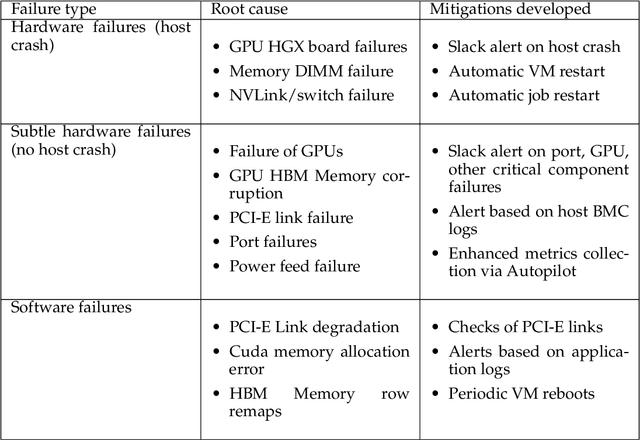
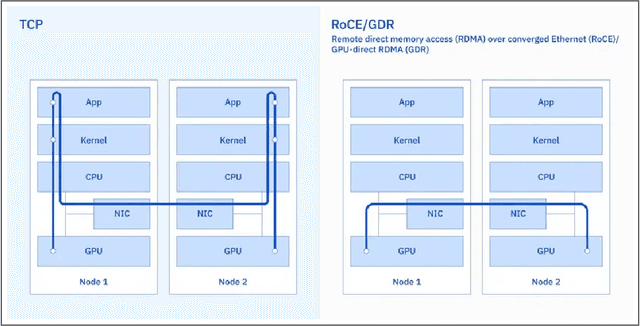
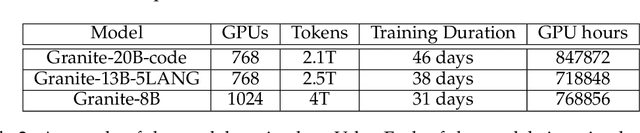
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
Adaptive Primal-Dual Method for Safe Reinforcement Learning
Feb 01, 2024

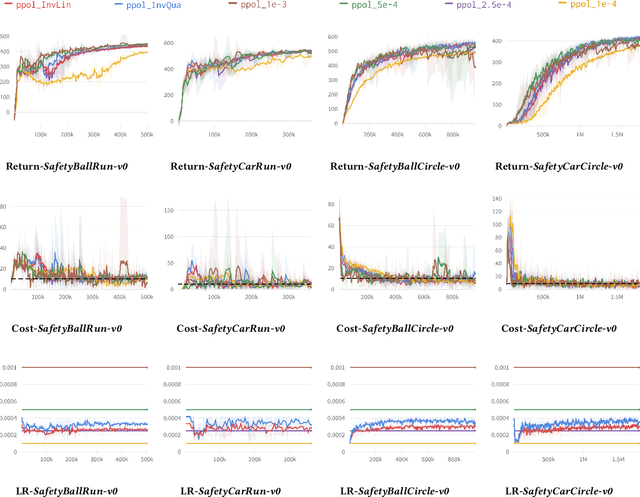

Primal-dual methods have a natural application in Safe Reinforcement Learning (SRL), posed as a constrained policy optimization problem. In practice however, applying primal-dual methods to SRL is challenging, due to the inter-dependency of the learning rate (LR) and Lagrangian multipliers (dual variables) each time an embedded unconstrained RL problem is solved. In this paper, we propose, analyze and evaluate adaptive primal-dual (APD) methods for SRL, where two adaptive LRs are adjusted to the Lagrangian multipliers so as to optimize the policy in each iteration. We theoretically establish the convergence, optimality and feasibility of the APD algorithm. Finally, we conduct numerical evaluation of the practical APD algorithm with four well-known environments in Bullet-Safey-Gym employing two state-of-the-art SRL algorithms: PPO-Lagrangian and DDPG-Lagrangian. All experiments show that the practical APD algorithm outperforms (or achieves comparable performance) and attains more stable training than the constant LR cases. Additionally, we substantiate the robustness of selecting the two adaptive LRs by empirical evidence.