 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Imagined Speech using Wavelet Features and Deep Neural Networks
Paper and Code
Mar 19, 2020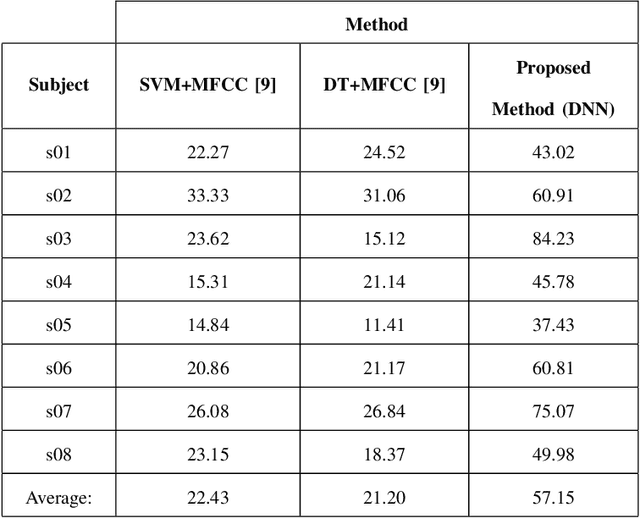
This paper proposes a novel approach that uses deep neural networks for classifying imagined speech, significantly increasing the classification accuracy. The proposed approach employs only the EEG channels over specific areas of the brain for classification, and derives distinct feature vectors from each of those channels. This gives us more data to train a classifier, enabling us to use deep learning approaches. Wavelet and temporal domain features are extracted from each channel. The final class label of each test trial is obtained by applying a majority voting on the classification results of the individual channels considered in the trial. This approach is used for classifying all the 11 prompts in the KaraOne dataset of imagined speech. The proposed architecture and the approach of treating the data have resulted in an average classification accuracy of 57.15%, which is an improvement of around 35% over the state-of-the-art results.