 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-ML Teaming: Integrated Symbolic Decoding and Gradient Search for Valid and Stable Generative Feature Transformation
Jun 10, 2025

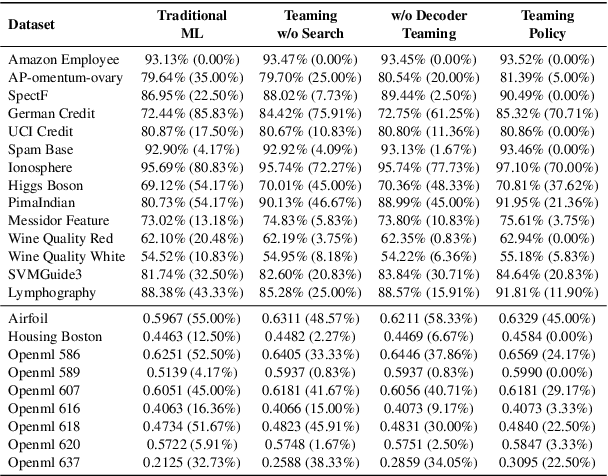
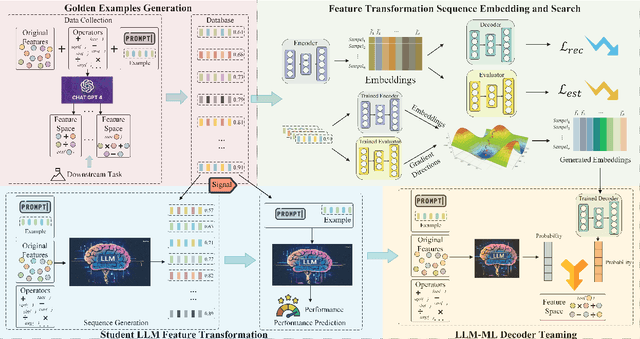
Feature transformation enhances data representation by deriving new features from the original data. Generative AI offers potential for this task, but faces challenges in stable generation (consistent outputs) and valid generation (error-free sequences). Existing methods--traditional MLs' low validity and LLMs' instability--fail to resolve both. We find that LLMs ensure valid syntax, while ML's gradient-steered search stabilizes performance. To bridge this gap, we propose a teaming framework combining LLMs' symbolic generation with ML's gradient optimization. This framework includes four steps: (1) golden examples generation, aiming to prepare high-quality samples with the ground knowledge of the teacher LLM; (2) feature transformation sequence embedding and search, intending to uncover potentially superior embeddings within the latent space; (3) student LLM feature transformation, aiming to distill knowledge from the teacher LLM; (4) LLM-ML decoder teaming, dedicating to combine ML and the student LLM probabilities for valid and stable generation. The experiments on various datasets show that the teaming policy can achieve 5\% improvement in downstream performance while reducing nearly half of the error cases. The results also demonstrate the efficiency and robustness of the teaming policy. Additionally, we also have exciting findings on LLMs' capacity to understand the original data.
Knowledge Graph-based Session Recommendation with Adaptive Propagation
Feb 17, 2024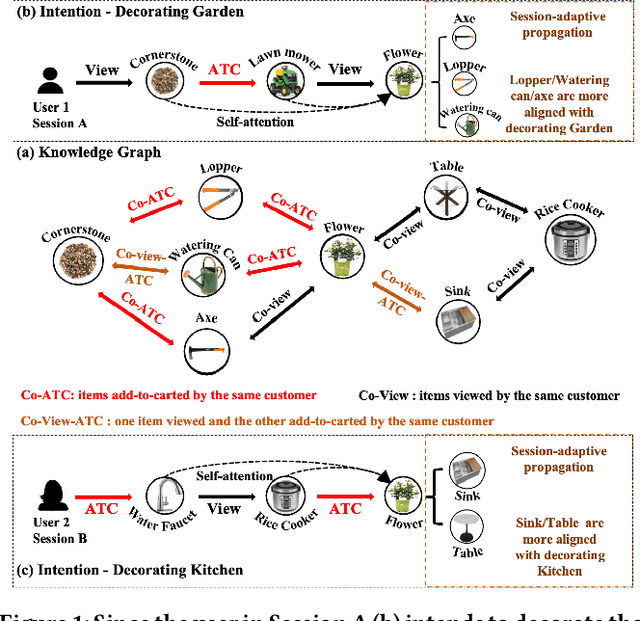
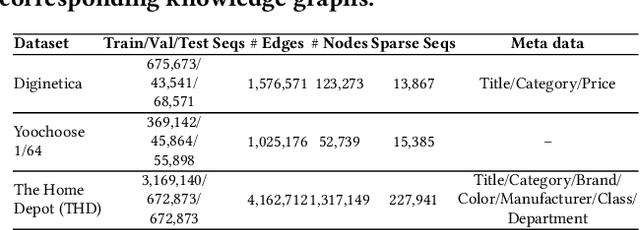

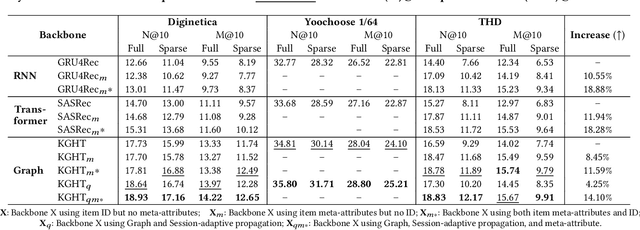
Session-based recommender systems (SBRSs) predict users' next interacted items based on their historical activities. While most SBRSs capture purchasing intentions locally within each session, capturing items' global information across different sessions is crucial in characterizing their general properties. Previous works capture this cross-session information by constructing graphs and incorporating neighbor information. However, this incorporation cannot vary adaptively according to the unique intention of each session, and the constructed graphs consist of only one type of user-item interaction. To address these limitations, we propose knowledge graph-based session recommendation with session-adaptive propagation. Specifically, we build a knowledge graph by connecting items with multi-typed edges to characterize various user-item interactions. Then, we adaptively aggregate items' neighbor information considering user intention within the learned session. Experimental results demonstrate that equipping our constructed knowledge graph and session-adaptive propagation enhances session recommendation backbones by 10%-20%. Moreover, we provide an industrial case study showing our proposed framework achieves 2% performance boost over an existing well-deployed model at The Home Depot e-platform.
Hierarchical Multi-Task Learning Framework for Session-based Recommendations
Sep 12, 2023
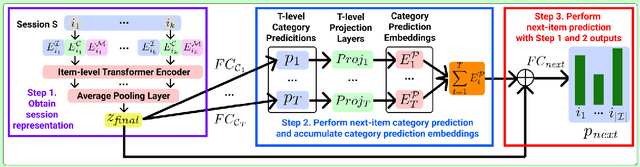

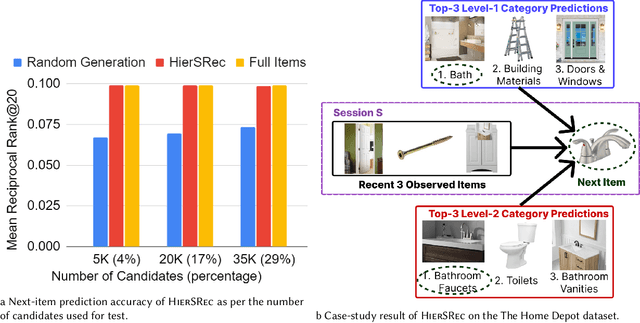
While session-based recommender systems (SBRSs) have shown superior recommendation performance, multi-task learning (MTL) has been adopted by SBRSs to enhance their prediction accuracy and generalizability further. Hierarchical MTL (H-MTL) sets a hierarchical structure between prediction tasks and feeds outputs from auxiliary tasks to main tasks. This hierarchy leads to richer input features for main tasks and higher interpretability of predictions, compared to existing MTL frameworks. However, the H-MTL framework has not been investigated in SBRSs yet. In this paper, we propose HierSRec which incorporates the H-MTL architecture into SBRSs. HierSRec encodes a given session with a metadata-aware Transformer and performs next-category prediction (i.e., auxiliary task) with the session encoding. Next, HierSRec conducts next-item prediction (i.e., main task) with the category prediction result and session encoding. For scalable inference, HierSRec creates a compact set of candidate items (e.g., 4% of total items) per test example using the category prediction. Experiments show that HierSRec outperforms existing SBRSs as per next-item prediction accuracy on two session-based recommendation datasets. The accuracy of HierSRec measured with the carefully-curated candidate items aligns with the accuracy of HierSRec calculated with all items, which validates the usefulness of our candidate generation scheme via H-MTL.
Local Boosting for Weakly-Supervised Learning
Jun 05, 2023Boosting is a commonly used technique to enhance the performance of a set of base models by combining them into a strong ensemble model. Though widely adopted, boosting is typically used in supervised learning where the data is labeled accurately. However, in weakly supervised learning, where most of the data is labeled through weak and noisy sources, it remains nontrivial to design effective boosting approaches. In this work, we show that the standard implementation of the convex combination of base learners can hardly work due to the presence of noisy labels. Instead, we propose $\textit{LocalBoost}$, a novel framework for weakly-supervised boosting. LocalBoost iteratively boosts the ensemble model from two dimensions, i.e., intra-source and inter-source. The intra-source boosting introduces locality to the base learners and enables each base learner to focus on a particular feature regime by training new base learners on granularity-varying error regions. For the inter-source boosting, we leverage a conditional function to indicate the weak source where the sample is more likely to appear. To account for the weak labels, we further design an estimate-then-modify approach to compute the model weights. Experiments on seven datasets show that our method significantly outperforms vanilla boosting methods and other weakly-supervised methods.
M2TRec: Metadata-aware Multi-task Transformer for Large-scale and Cold-start free Session-based Recommendations
Sep 23, 2022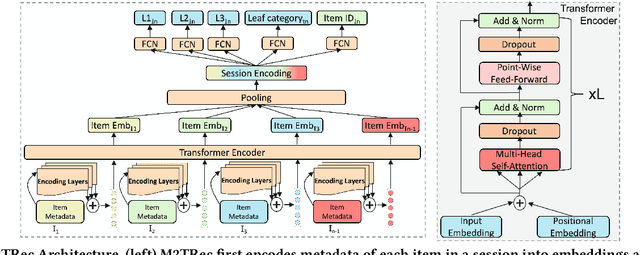
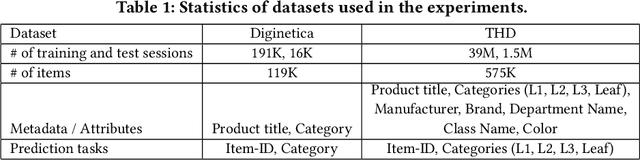
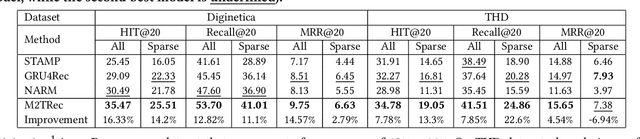
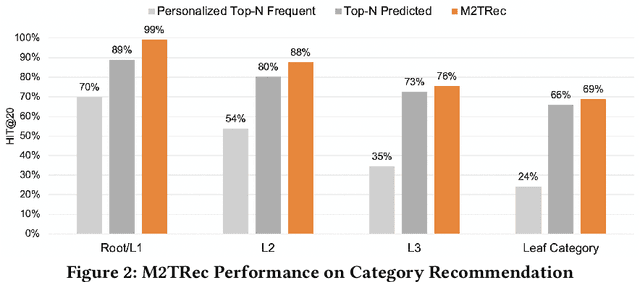
Session-based recommender systems (SBRSs) have shown superior performance over conventional methods. However, they show limited scalability on large-scale industrial datasets since most models learn one embedding per item. This leads to a large memory requirement (of storing one vector per item) and poor performance on sparse sessions with cold-start or unpopular items. Using one public and one large industrial dataset, we experimentally show that state-of-the-art SBRSs have low performance on sparse sessions with sparse items. We propose M2TRec, a Metadata-aware Multi-task Transformer model for session-based recommendations. Our proposed method learns a transformation function from item metadata to embeddings, and is thus, item-ID free (i.e., does not need to learn one embedding per item). It integrates item metadata to learn shared representations of diverse item attributes. During inference, new or unpopular items will be assigned identical representations for the attributes they share with items previously observed during training, and thus will have similar representations with those items, enabling recommendations of even cold-start and sparse items. Additionally, M2TRec is trained in a multi-task setting to predict the next item in the session along with its primary category and subcategories. Our multi-task strategy makes the model converge faster and significantly improves the overall performance. Experimental results show significant performance gains using our proposed approach on sparse items on the two datasets.
* Accepted at the 16th ACM Conference on Recommender Systems (RecSys '22)
Adaptive Multi-view Rule Discovery for Weakly-Supervised Compatible Products Prediction
Jun 28, 2022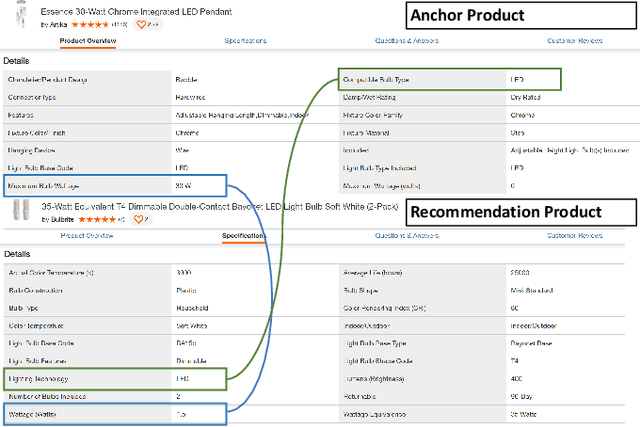

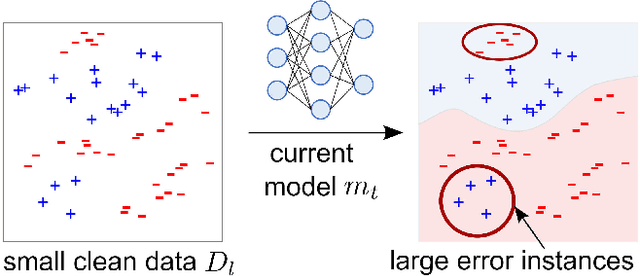

On e-commerce platforms, predicting if two products are compatible with each other is an important functionality to achieve trustworthy product recommendation and search experience for consumers. However, accurately predicting product compatibility is difficult due to the heterogeneous product data and the lack of manually curated training data. We study the problem of discovering effective labeling rules that can enable weakly-supervised product compatibility prediction. We develop AMRule, a multi-view rule discovery framework that can (1) adaptively and iteratively discover novel rulers that can complement the current weakly-supervised model to improve compatibility prediction; (2) discover interpretable rules from both structured attribute tables and unstructured product descriptions. AMRule adaptively discovers labeling rules from large-error instances via a boosting-style strategy, the high-quality rules can remedy the current model's weak spots and refine the model iteratively. For rule discovery from structured product attributes, we generate composable high-order rules from decision trees; and for rule discovery from unstructured product descriptions, we generate prompt-based rules from a pre-trained language model. Experiments on 4 real-world datasets show that AMRule outperforms the baselines by 5.98% on average and improves rule quality and rule proposal efficiency.
Adaptively Optimize Content Recommendation Using Multi Armed Bandit Algorithms in E-commerce
Aug 19, 2021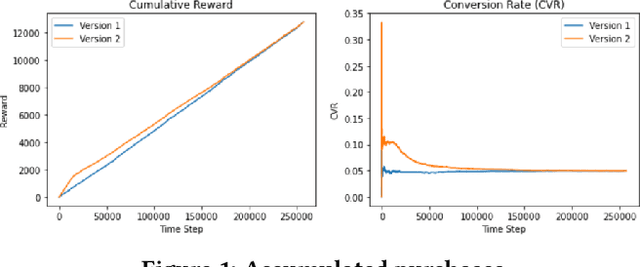
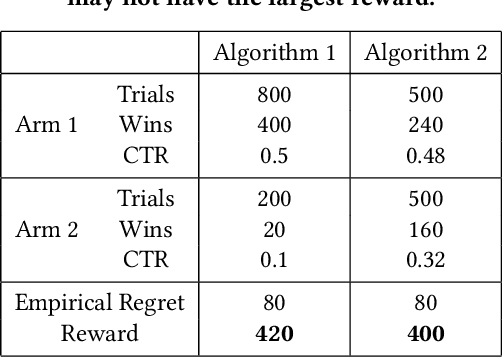
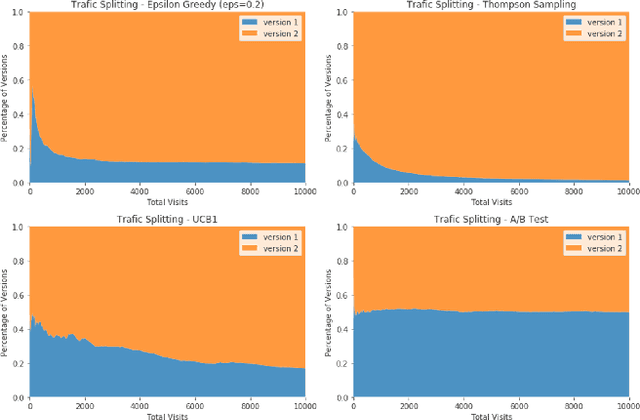
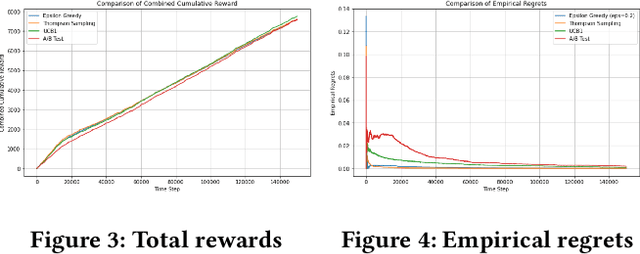
E-commerce sites strive to provide users the most timely relevant information in order to reduce shopping frictions and increase customer satisfaction. Multi armed bandit models (MAB) as a type of adaptive optimization algorithms provide possible approaches for such purposes. In this paper, we analyze using three classic MAB algorithms, epsilon-greedy, Thompson sampling (TS), and upper confidence bound 1 (UCB1) for dynamic content recommendations, and walk through the process of developing these algorithms internally to solve a real world e-commerce use case. First, we analyze the three MAB algorithms using simulated purchasing datasets with non-stationary reward distributions to simulate the possible time-varying customer preferences, where the traffic allocation dynamics and the accumulative rewards of different algorithms are studied. Second, we compare the accumulative rewards of the three MAB algorithms with more than 1,000 trials using actual historical A/B test datasets. We find that the larger difference between the success rates of competing recommendations the more accumulative rewards the MAB algorithms can achieve. In addition, we find that TS shows the highest average accumulative rewards under different testing scenarios. Third, we develop a batch-updated MAB algorithm to overcome the delayed reward issue in e-commerce and enable an online content optimization on our App homepage. For a state-of-the-art comparison, a real A/B test among our batch-updated MAB algorithm, a third-party MAB solution, and the default business logic are conducted. The result shows that our batch-updated MAB algorithm outperforms the counterparts and achieves 6.13% relative click-through rate (CTR) increase and 16.1% relative conversion rate (CVR) increase compared to the default experience, and 2.9% relative CTR increase and 1.4% relative CVR increase compared to the external MAB service.
Online Product Feature Recommendations with Interpretable Machine Learning
Apr 28, 2021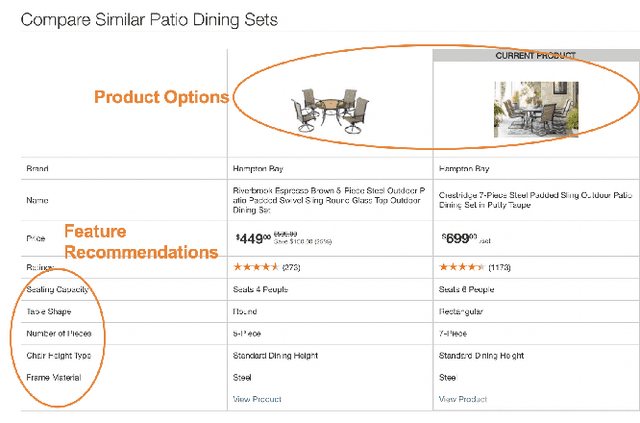
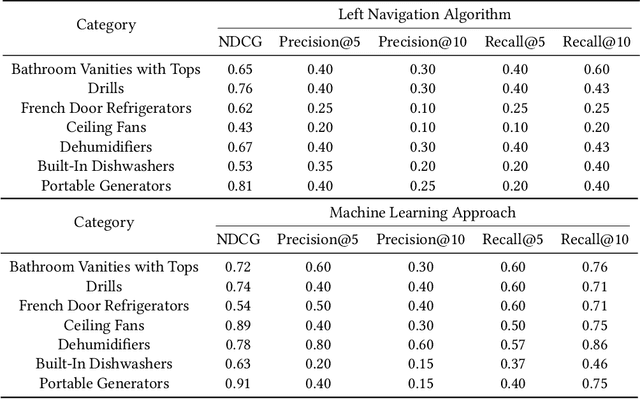
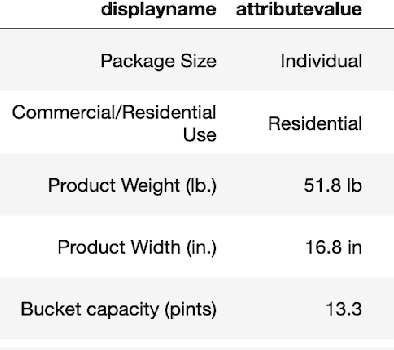

Product feature recommendations are critical for online customers to purchase the right products based on the right features. For a customer, selecting the product that has the best trade-off between price and functionality is a time-consuming step in an online shopping experience, and customers can be overwhelmed by the available choices. However, determining the set of product features that most differentiate a particular product is still an open question in online recommender systems. In this paper, we focus on using interpretable machine learning methods to tackle this problem. First, we identify this unique product feature recommendation problem from a business perspective on a major US e-commerce site. Second, we formulate the problem into a price-driven supervised learning problem to discover the product features that could best explain the price of a product in a given product category. We build machine learning models with a model-agnostic method Shapley Values to understand the importance of each feature, rank and recommend the most essential features. Third, we leverage human experts to evaluate its relevancy. The results show that our method is superior to a strong baseline method based on customer behavior and significantly boosts the coverage by 45%. Finally, our proposed method shows comparable conversion rate against the baseline in online A/B tests.
Deep Learning-based Online Alternative Product Recommendations at Scale
Apr 15, 2021
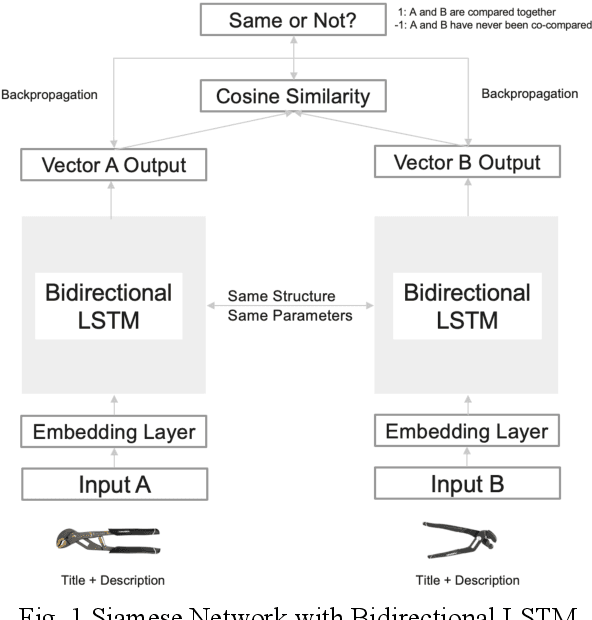

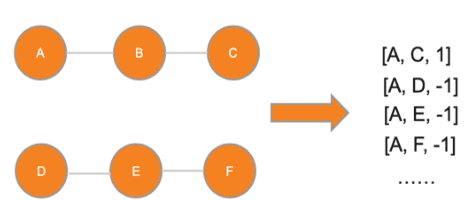
Alternative recommender systems are critical for ecommerce companies. They guide customers to explore a massive product catalog and assist customers to find the right products among an overwhelming number of options. However, it is a non-trivial task to recommend alternative products that fit customer needs. In this paper, we use both textual product information (e.g. product titles and descriptions) and customer behavior data to recommend alternative products. Our results show that the coverage of alternative products is significantly improved in offline evaluations as well as recall and precision. The final A/B test shows that our algorithm increases the conversion rate by 12 percent in a statistically significant way. In order to better capture the semantic meaning of product information, we build a Siamese Network with Bidirectional LSTM to learn product embeddings. In order to learn a similarity space that better matches the preference of real customers, we use co-compared data from historical customer behavior as labels to train the network. In addition, we use NMSLIB to accelerate the computationally expensive kNN computation for millions of products so that the alternative recommendation is able to scale across the entire catalog of a major ecommerce site.
Interpretable Methods for Identifying Product Variants
Apr 12, 2021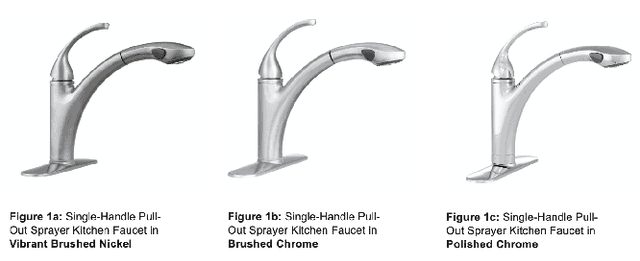

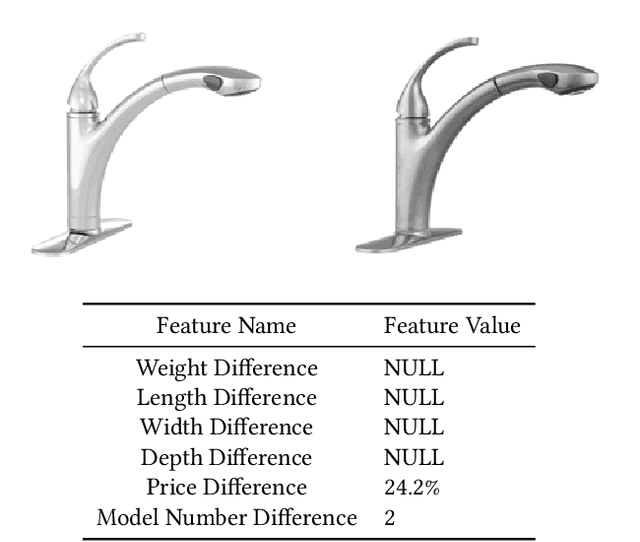

For e-commerce companies with large product selections, the organization and grouping of products in meaningful ways is important for creating great customer shopping experiences and cultivating an authoritative brand image. One important way of grouping products is to identify a family of product variants, where the variants are mostly the same with slight and yet distinct differences (e.g. color or pack size). In this paper, we introduce a novel approach to identifying product variants. It combines both constrained clustering and tailored NLP techniques (e.g. extraction of product family name from unstructured product title and identification of products with similar model numbers) to achieve superior performance compared with an existing baseline using a vanilla classification approach. In addition, we design the algorithm to meet certain business criteria, including meeting high accuracy requirements on a wide range of categories (e.g. appliances, decor, tools, and building materials, etc.) as well as prioritizing the interpretability of the model to make it accessible and understandable to all business partners.