 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review of Modern Object Segmentation Approaches
Jan 13, 2023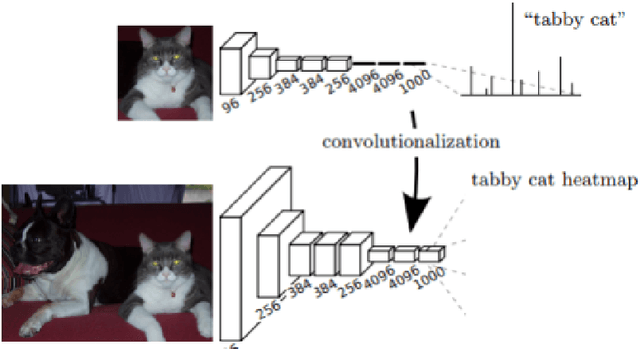



Image segmentation is the task of associating pixels in an image with their respective object class labels. It has a wide range of applications in many industries including healthcare, transportation, robotics, fashion, home improvement, and tourism. Many deep learning-based approaches have been developed for image-level object recognition and pixel-level scene understanding-with the latter requiring a much denser annotation of scenes with a large set of objects. Extensions of image segmentation tasks include 3D and video segmentation, where units of voxels, point clouds, and video frames are classified into different objects. We use "Object Segmentation" to refer to the union of these segmentation tasks. In this monograph, we investigate both traditional and modern object segmentation approaches, comparing their strengths, weaknesses, and utilities. We examine in detail the wide range of deep learning-based segmentation techniques developed in recent years, provide a review of the widely used datasets and evaluation metrics, and discuss potential future research directions.
* 173 pages, 49 figures, published in Foundations and Trends in Computer Graphics and Vision on 10/4/22. Authors retain copyright
Deep Learning-based Online Alternative Product Recommendations at Scale
Apr 15, 2021
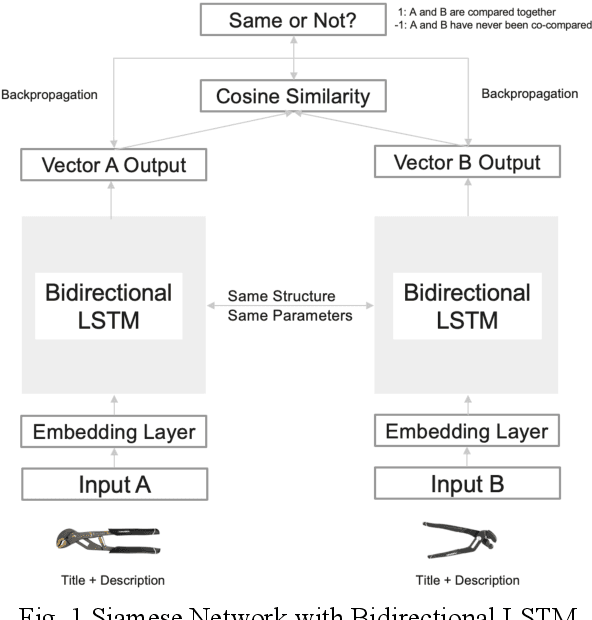

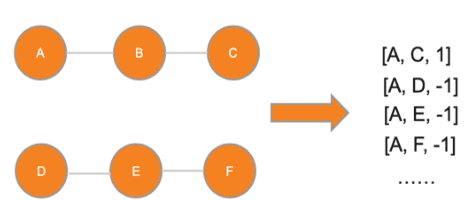
Alternative recommender systems are critical for ecommerce companies. They guide customers to explore a massive product catalog and assist customers to find the right products among an overwhelming number of options. However, it is a non-trivial task to recommend alternative products that fit customer needs. In this paper, we use both textual product information (e.g. product titles and descriptions) and customer behavior data to recommend alternative products. Our results show that the coverage of alternative products is significantly improved in offline evaluations as well as recall and precision. The final A/B test shows that our algorithm increases the conversion rate by 12 percent in a statistically significant way. In order to better capture the semantic meaning of product information, we build a Siamese Network with Bidirectional LSTM to learn product embeddings. In order to learn a similarity space that better matches the preference of real customers, we use co-compared data from historical customer behavior as labels to train the network. In addition, we use NMSLIB to accelerate the computationally expensive kNN computation for millions of products so that the alternative recommendation is able to scale across the entire catalog of a major ecommerce site.
Interpretable Methods for Identifying Product Variants
Apr 12, 2021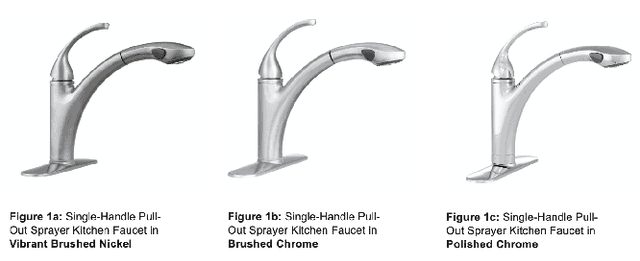

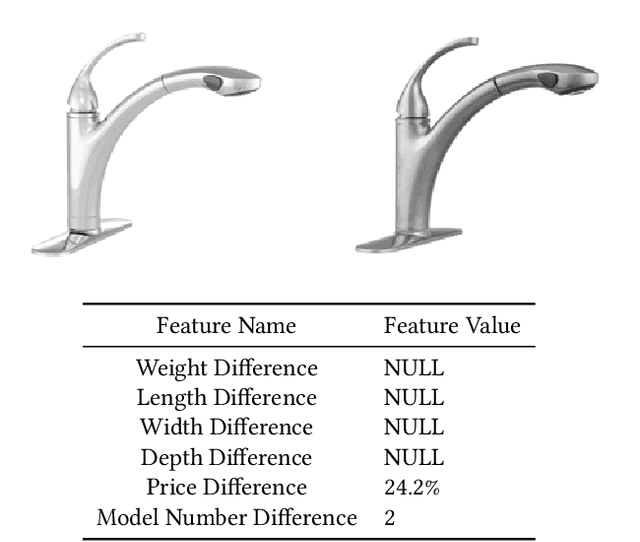

For e-commerce companies with large product selections, the organization and grouping of products in meaningful ways is important for creating great customer shopping experiences and cultivating an authoritative brand image. One important way of grouping products is to identify a family of product variants, where the variants are mostly the same with slight and yet distinct differences (e.g. color or pack size). In this paper, we introduce a novel approach to identifying product variants. It combines both constrained clustering and tailored NLP techniques (e.g. extraction of product family name from unstructured product title and identification of products with similar model numbers) to achieve superior performance compared with an existing baseline using a vanilla classification approach. In addition, we design the algorithm to meet certain business criteria, including meeting high accuracy requirements on a wide range of categories (e.g. appliances, decor, tools, and building materials, etc.) as well as prioritizing the interpretability of the model to make it accessible and understandable to all business partners.
Video Jigsaw: Unsupervised Learning of Spatiotemporal Context for Video Action Recognition
Aug 22, 2018

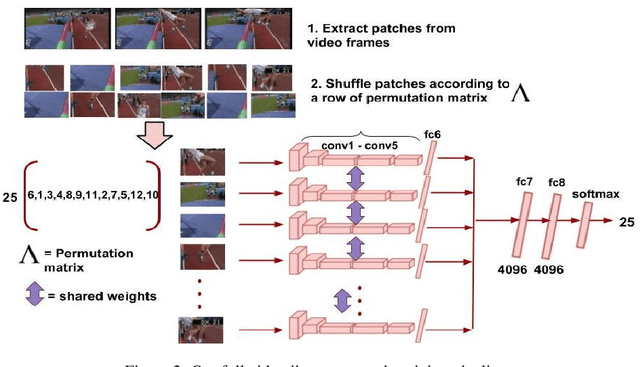
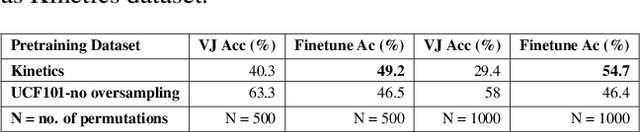
We propose a self-supervised learning method to jointly reason about spatial and temporal context for video recognition. Recent self-supervised approaches have used spatial context [9, 34] as well as temporal coherency [32] but a combination of the two requires extensive preprocessing such as tracking objects through millions of video frames [59] or computing optical flow to determine frame regions with high motion [30]. We propose to combine spatial and temporal context in one self-supervised framework without any heavy preprocessing. We divide multiple video frames into grids of patches and train a network to solve jigsaw puzzles on these patches from multiple frames. So the network is trained to correctly identify the position of a patch within a video frame as well as the position of a patch over time. We also propose a novel permutation strategy that outperforms random permutations while significantly reducing computational and memory constraints. We use our trained network for transfer learning tasks such as video activity recognition and demonstrate the strength of our approach on two benchmark video action recognition datasets without using a single frame from these datasets for unsupervised pretraining of our proposed video jigsaw network.
DiscrimNet: Semi-Supervised Action Recognition from Videos using Generative Adversarial Networks
Jan 22, 2018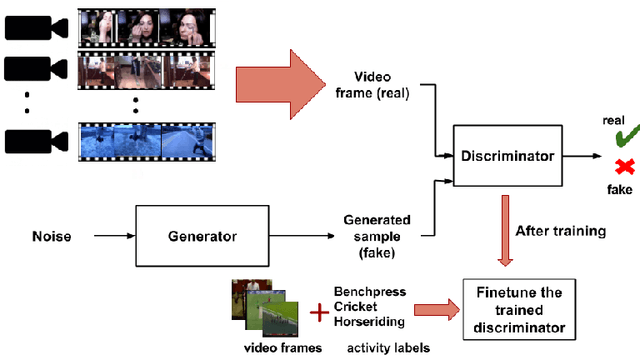
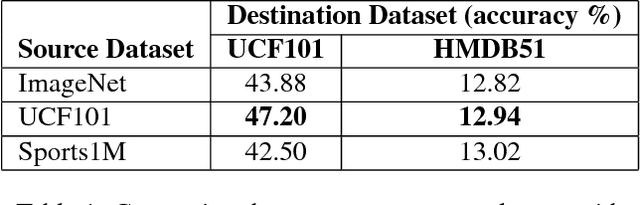


We propose an action recognition framework using Gen- erative Adversarial Networks. Our model involves train- ing a deep convolutional generative adversarial network (DCGAN) using a large video activity dataset without la- bel information. Then we use the trained discriminator from the GAN model as an unsupervised pre-training step and fine-tune the trained discriminator model on a labeled dataset to recognize human activities. We determine good network architectural and hyperparameter settings for us- ing the discriminator from DCGAN as a trained model to learn useful representations for action recognition. Our semi-supervised framework using only appearance infor- mation achieves superior or comparable performance to the current state-of-the-art semi-supervised action recog- nition methods on two challenging video activity datasets: UCF101 and HMDB51.
Complex Event Recognition from Images with Few Training Examples
Jan 17, 2017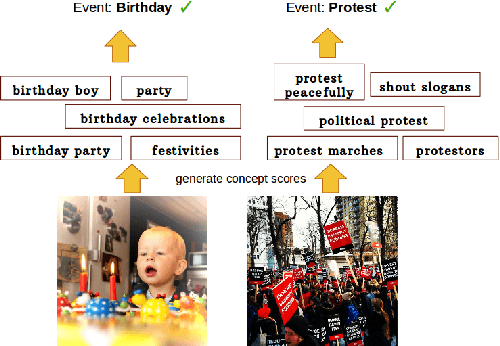

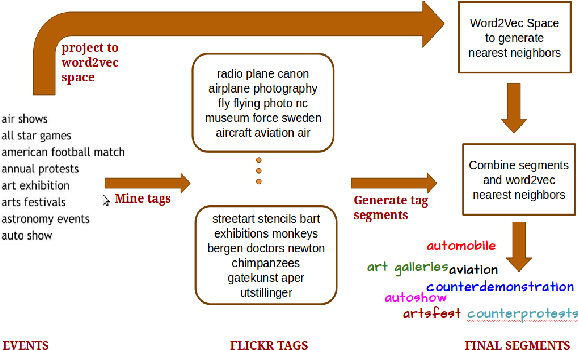
We propose to leverage concept-level representations for complex event recognition in photographs given limited training examples. We introduce a novel framework to discover event concept attributes from the web and use that to extract semantic features from images and classify them into social event categories with few training examples. Discovered concepts include a variety of objects, scenes, actions and event sub-types, leading to a discriminative and compact representation for event images. Web images are obtained for each discovered event concept and we use (pretrained) CNN features to train concept classifiers. Extensive experiments on challenging event datasets demonstrate that our proposed method outperforms several baselines using deep CNN features directly in classifying images into events with limited training examples. We also demonstrate that our method achieves the best overall accuracy on a dataset with unseen event categories using a single training example.