 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrimNet: Semi-Supervised Action Recognition from Videos using Generative Adversarial Networks
Paper and Code
Jan 22, 2018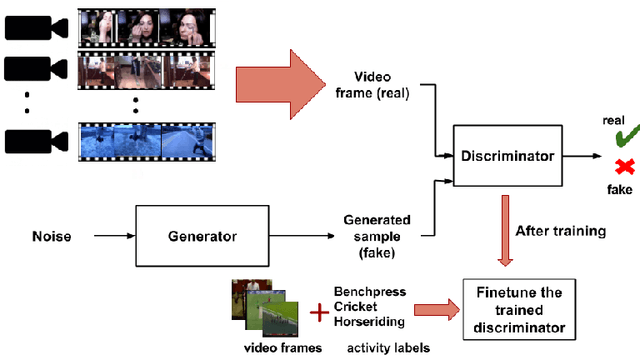
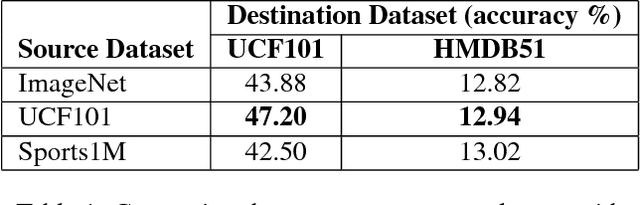


We propose an action recognition framework using Gen- erative Adversarial Networks. Our model involves train- ing a deep convolutional generative adversarial network (DCGAN) using a large video activity dataset without la- bel information. Then we use the trained discriminator from the GAN model as an unsupervised pre-training step and fine-tune the trained discriminator model on a labeled dataset to recognize human activities. We determine good network architectural and hyperparameter settings for us- ing the discriminator from DCGAN as a trained model to learn useful representations for action recognition. Our semi-supervised framework using only appearance infor- mation achieves superior or comparable performance to the current state-of-the-art semi-supervised action recog- nition methods on two challenging video activity datasets: UCF101 and HMDB51.