 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Multi-view Rule Discovery for Weakly-Supervised Compatible Products Prediction
Jun 28, 2022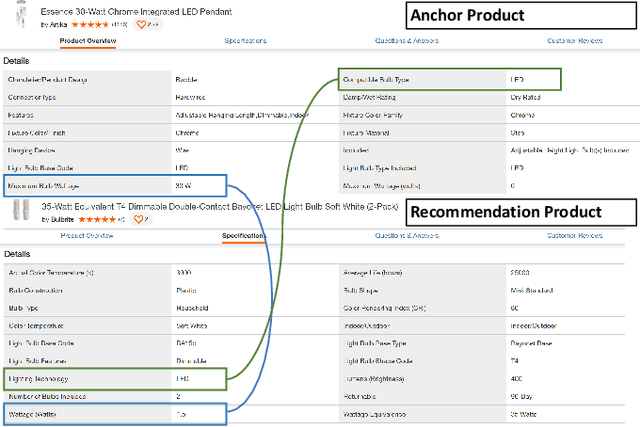

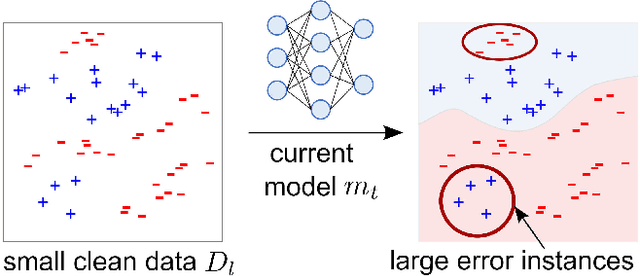

On e-commerce platforms, predicting if two products are compatible with each other is an important functionality to achieve trustworthy product recommendation and search experience for consumers. However, accurately predicting product compatibility is difficult due to the heterogeneous product data and the lack of manually curated training data. We study the problem of discovering effective labeling rules that can enable weakly-supervised product compatibility prediction. We develop AMRule, a multi-view rule discovery framework that can (1) adaptively and iteratively discover novel rulers that can complement the current weakly-supervised model to improve compatibility prediction; (2) discover interpretable rules from both structured attribute tables and unstructured product descriptions. AMRule adaptively discovers labeling rules from large-error instances via a boosting-style strategy, the high-quality rules can remedy the current model's weak spots and refine the model iteratively. For rule discovery from structured product attributes, we generate composable high-order rules from decision trees; and for rule discovery from unstructured product descriptions, we generate prompt-based rules from a pre-trained language model. Experiments on 4 real-world datasets show that AMRule outperforms the baselines by 5.98% on average and improves rule quality and rule proposal efficiency.
Deep Learning-based Online Alternative Product Recommendations at Scale
Apr 15, 2021
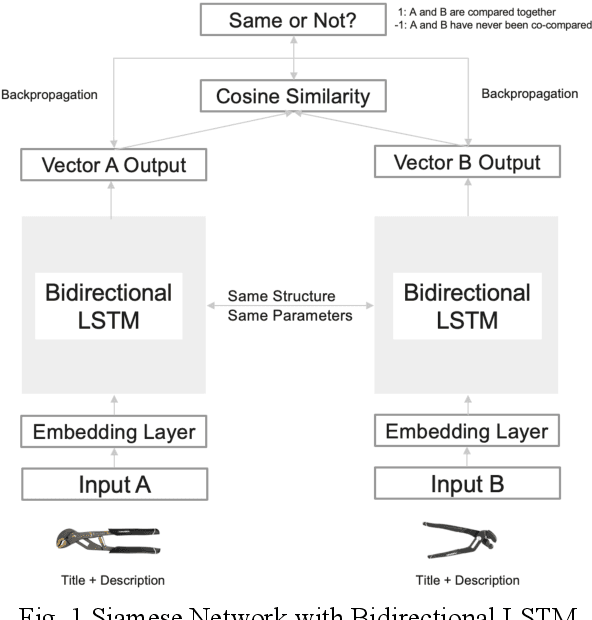

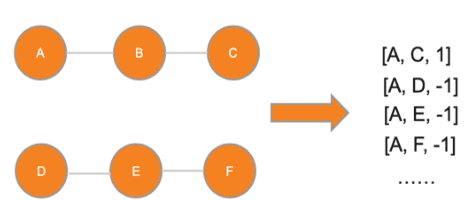
Alternative recommender systems are critical for ecommerce companies. They guide customers to explore a massive product catalog and assist customers to find the right products among an overwhelming number of options. However, it is a non-trivial task to recommend alternative products that fit customer needs. In this paper, we use both textual product information (e.g. product titles and descriptions) and customer behavior data to recommend alternative products. Our results show that the coverage of alternative products is significantly improved in offline evaluations as well as recall and precision. The final A/B test shows that our algorithm increases the conversion rate by 12 percent in a statistically significant way. In order to better capture the semantic meaning of product information, we build a Siamese Network with Bidirectional LSTM to learn product embeddings. In order to learn a similarity space that better matches the preference of real customers, we use co-compared data from historical customer behavior as labels to train the network. In addition, we use NMSLIB to accelerate the computationally expensive kNN computation for millions of products so that the alternative recommendation is able to scale across the entire catalog of a major ecommerce site.
Interpretable Methods for Identifying Product Variants
Apr 12, 2021

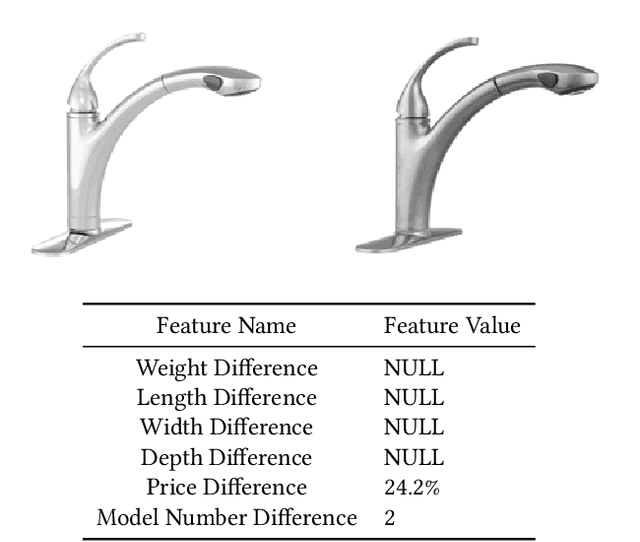

For e-commerce companies with large product selections, the organization and grouping of products in meaningful ways is important for creating great customer shopping experiences and cultivating an authoritative brand image. One important way of grouping products is to identify a family of product variants, where the variants are mostly the same with slight and yet distinct differences (e.g. color or pack size). In this paper, we introduce a novel approach to identifying product variants. It combines both constrained clustering and tailored NLP techniques (e.g. extraction of product family name from unstructured product title and identification of products with similar model numbers) to achieve superior performance compared with an existing baseline using a vanilla classification approach. In addition, we design the algorithm to meet certain business criteria, including meeting high accuracy requirements on a wide range of categories (e.g. appliances, decor, tools, and building materials, etc.) as well as prioritizing the interpretability of the model to make it accessible and understandable to all business partners.