 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively Optimize Content Recommendation Using Multi Armed Bandit Algorithms in E-commerce
Aug 19, 2021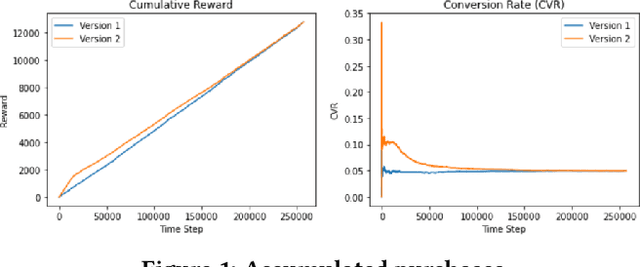
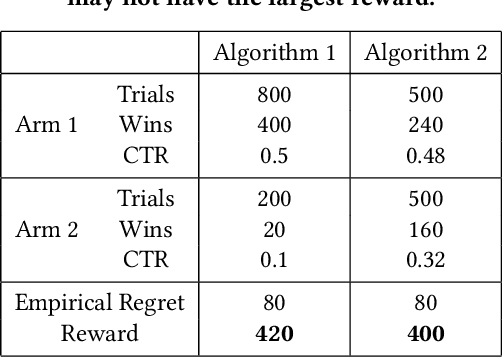
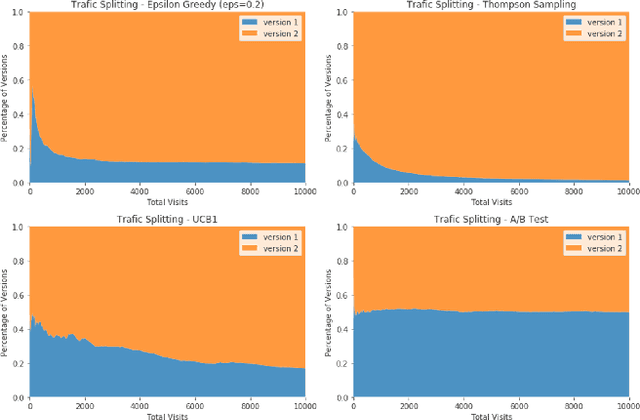
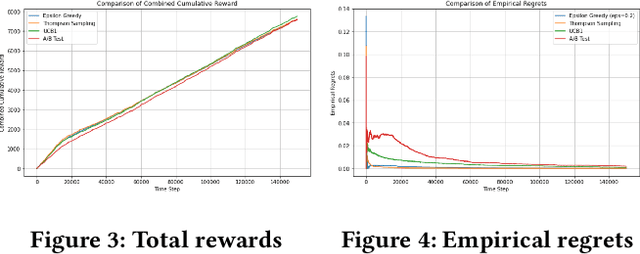
E-commerce sites strive to provide users the most timely relevant information in order to reduce shopping frictions and increase customer satisfaction. Multi armed bandit models (MAB) as a type of adaptive optimization algorithms provide possible approaches for such purposes. In this paper, we analyze using three classic MAB algorithms, epsilon-greedy, Thompson sampling (TS), and upper confidence bound 1 (UCB1) for dynamic content recommendations, and walk through the process of developing these algorithms internally to solve a real world e-commerce use case. First, we analyze the three MAB algorithms using simulated purchasing datasets with non-stationary reward distributions to simulate the possible time-varying customer preferences, where the traffic allocation dynamics and the accumulative rewards of different algorithms are studied. Second, we compare the accumulative rewards of the three MAB algorithms with more than 1,000 trials using actual historical A/B test datasets. We find that the larger difference between the success rates of competing recommendations the more accumulative rewards the MAB algorithms can achieve. In addition, we find that TS shows the highest average accumulative rewards under different testing scenarios. Third, we develop a batch-updated MAB algorithm to overcome the delayed reward issue in e-commerce and enable an online content optimization on our App homepage. For a state-of-the-art comparison, a real A/B test among our batch-updated MAB algorithm, a third-party MAB solution, and the default business logic are conducted. The result shows that our batch-updated MAB algorithm outperforms the counterparts and achieves 6.13% relative click-through rate (CTR) increase and 16.1% relative conversion rate (CVR) increase compared to the default experience, and 2.9% relative CTR increase and 1.4% relative CVR increase compared to the external MAB service.