 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacro-optimization of email recommendation response rates harnessing individual activity levels and group affinity trends
Sep 20, 2016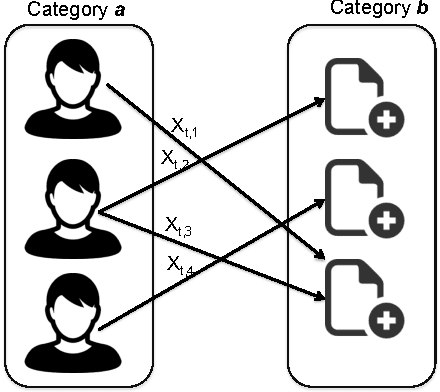
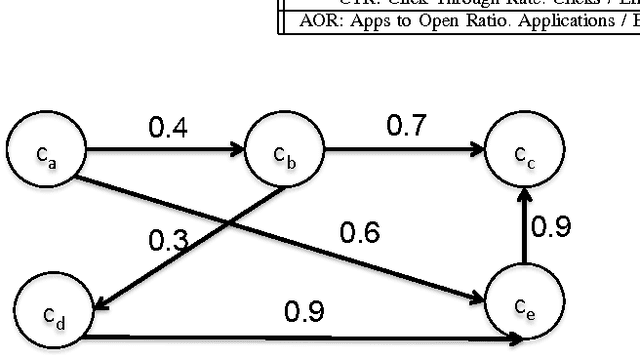
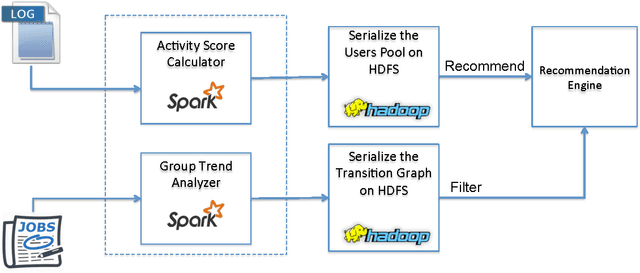

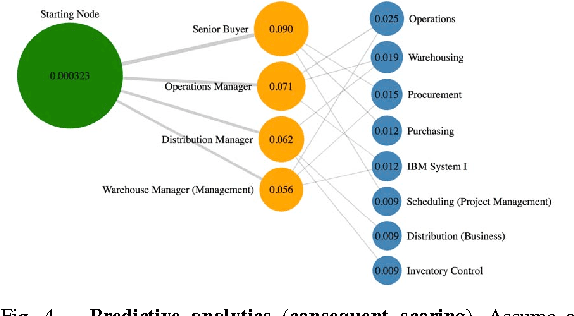
Recommendation emails are among the best ways to re-engage with customers after they have left a website. While on-site recommendation systems focus on finding the most relevant items for a user at the moment (right item), email recommendations add two critical additional dimensions: who to send recommendations to (right person) and when to send them (right time). It is critical that a recommendation email system not send too many emails to too many users in too short of a time-window, as users may unsubscribe from future emails or become desensitized and ignore future emails if they receive too many. Also, email service providers may mark such emails as spam if too many of their users are contacted in a short time-window. Optimizing email recommendation systems such that they can yield a maximum response rate for a minimum number of email sends is thus critical for the long-term performance of such a system. In this paper, we present a novel recommendation email system that not only generates recommendations, but which also leverages a combination of individual user activity data, as well as the behavior of the group to which they belong, in order to determine each user's likelihood to respond to any given set of recommendations within a given time period. In doing this, we have effectively created a meta-recommendation system which recommends sets of recommendations in order to optimize the aggregate response rate of the entire system. The proposed technique has been applied successfully within CareerBuilder's job recommendation email system to generate a 50\% increase in total conversions while also decreasing sent emails by 72%
* This version is accepted as regular paper in The 15th IEEE International Conference on Machine Learning and Applications (IEEE ICMLA'16) . pre-camera ready version
The Semantic Knowledge Graph: A compact, auto-generated model for real-time traversal and ranking of any relationship within a domain
Sep 05, 2016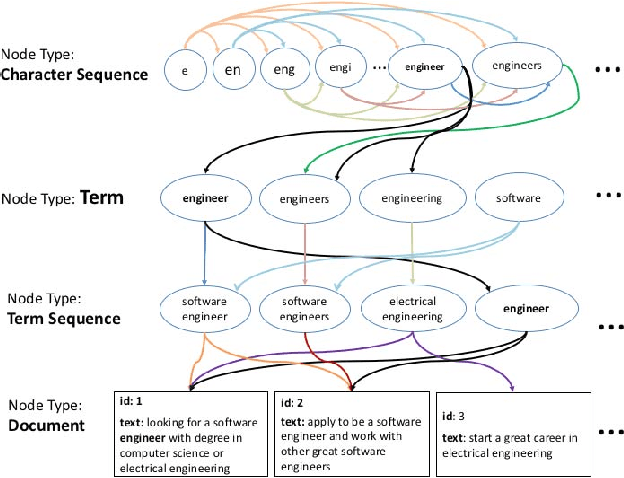
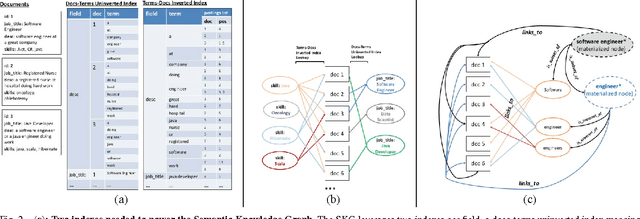
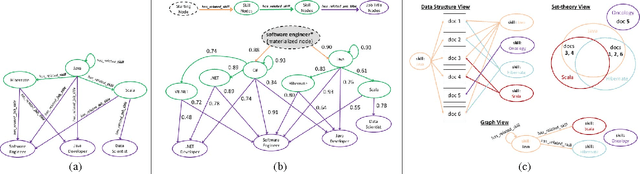
This paper describes a new kind of knowledge representation and mining system which we are calling the Semantic Knowledge Graph. At its heart, the Semantic Knowledge Graph leverages an inverted index, along with a complementary uninverted index, to represent nodes (terms) and edges (the documents within intersecting postings lists for multiple terms/nodes). This provides a layer of indirection between each pair of nodes and their corresponding edge, enabling edges to materialize dynamically from underlying corpus statistics. As a result, any combination of nodes can have edges to any other nodes materialize and be scored to reveal latent relationships between the nodes. This provides numerous benefits: the knowledge graph can be built automatically from a real-world corpus of data, new nodes - along with their combined edges - can be instantly materialized from any arbitrary combination of preexisting nodes (using set operations), and a full model of the semantic relationships between all entities within a domain can be represented and dynamically traversed using a highly compact representation of the graph. Such a system has widespread applications in areas as diverse as knowledge modeling and reasoning, natural language processing, anomaly detection, data cleansing, semantic search, analytics, data classification, root cause analysis, and recommendations systems. The main contribution of this paper is the introduction of a novel system - the Semantic Knowledge Graph - which is able to dynamically discover and score interesting relationships between any arbitrary combination of entities (words, phrases, or extracted concepts) through dynamically materializing nodes and edges from a compact graphical representation built automatically from a corpus of data representative of a knowledge domain.
Application of Statistical Relational Learning to Hybrid Recommendation Systems
Jul 04, 2016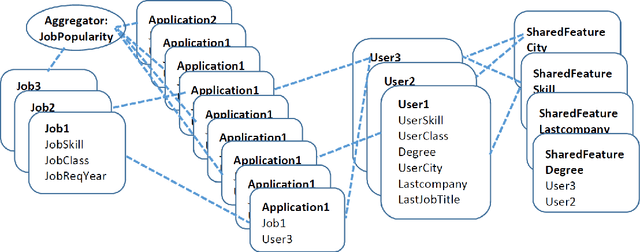
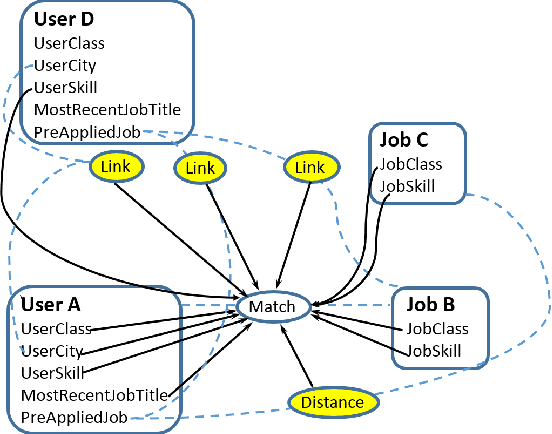
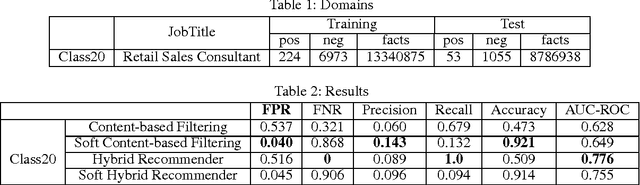
Recommendation systems usually involve exploiting the relations among known features and content that describe items (content-based filtering) or the overlap of similar users who interacted with or rated the target item (collaborative filtering). To combine these two filtering approaches, current model-based hybrid recommendation systems typically require extensive feature engineering to construct a user profile. Statistical Relational Learning (SRL) provides a straightforward way to combine the two approaches. However, due to the large scale of the data used in real world recommendation systems, little research exists on applying SRL models to hybrid recommendation systems, and essentially none of that research has been applied on real big-data-scale systems. In this paper, we proposed a way to adapt the state-of-the-art in SRL learning approaches to construct a real hybrid recommendation system. Furthermore, in order to satisfy a common requirement in recommendation systems (i.e. that false positives are more undesirable and therefore penalized more harshly than false negatives), our approach can also allow tuning the trade-off between the precision and recall of the system in a principled way. Our experimental results demonstrate the efficiency of our proposed approach as well as its improved performance on recommendation precision.
Entity Type Recognition using an Ensemble of Distributional Semantic Models to Enhance Query Understanding
Apr 04, 2016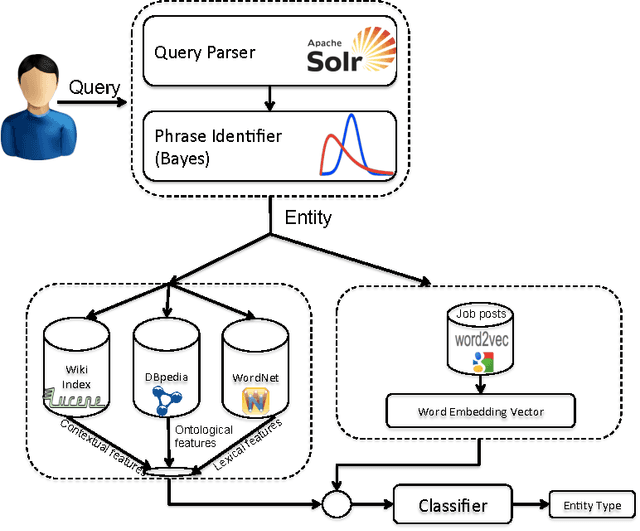
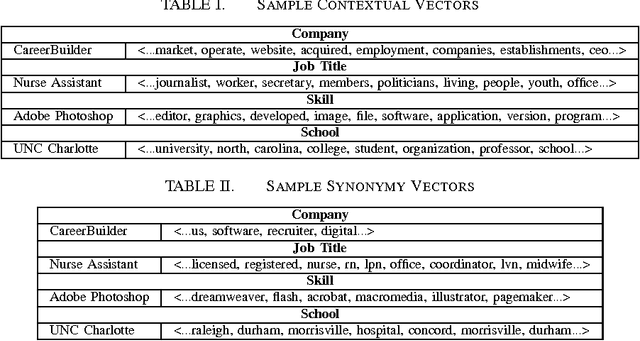
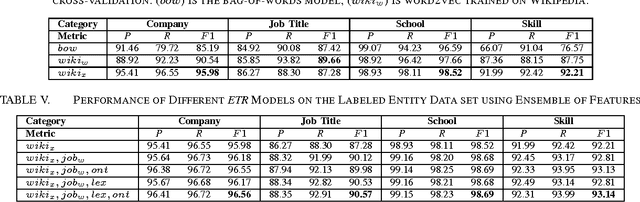
We present an ensemble approach for categorizing search query entities in the recruitment domain. Understanding the types of entities expressed in a search query (Company, Skill, Job Title, etc.) enables more intelligent information retrieval based upon those entities compared to a traditional keyword-based search. Because search queries are typically very short, leveraging a traditional bag-of-words model to identify entity types would be inappropriate due to the lack of contextual information. Our approach instead combines clues from different sources of varying complexity in order to collect real-world knowledge about query entities. We employ distributional semantic representations of query entities through two models: 1) contextual vectors generated from encyclopedic corpora like Wikipedia, and 2) high dimensional word embedding vectors generated from millions of job postings using word2vec. Additionally, our approach utilizes both entity linguistic properties obtained from WordNet and ontological properties extracted from DBpedia. We evaluate our approach on a data set created at CareerBuilder; the largest job board in the US. The data set contains entities extracted from millions of job seekers/recruiters search queries, job postings, and resume documents. After constructing the distributional vectors of search entities, we use supervised machine learning to infer search entity types. Empirical results show that our approach outperforms the state-of-the-art word2vec distributional semantics model trained on Wikipedia. Moreover, we achieve micro-averaged F 1 score of 97% using the proposed distributional representations ensemble.
Mining Massive Hierarchical Data Using a Scalable Probabilistic Graphical Model
Dec 28, 2015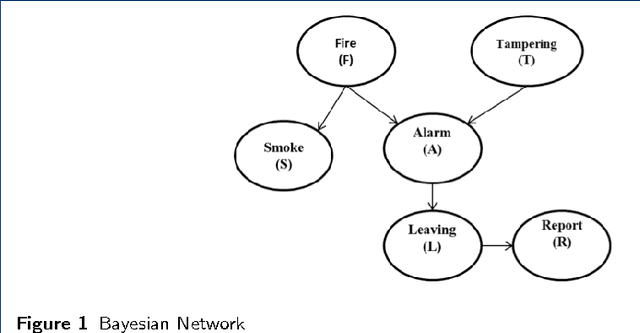
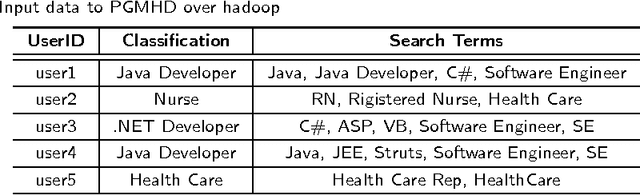
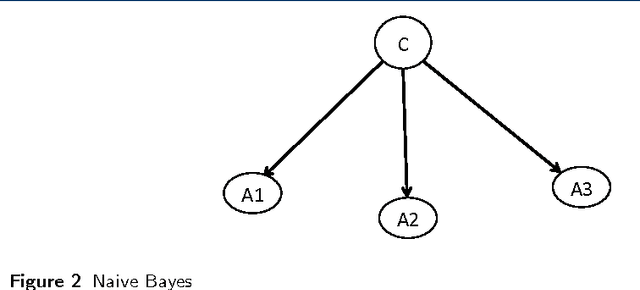

Probabilistic Graphical Models (PGM) are very useful in the fields of machine learning and data mining. The crucial limitation of those models,however, is the scalability. The Bayesian Network, which is one of the most common PGMs used in machine learning and data mining, demonstrates this limitation when the training data consists of random variables, each of them has a large set of possible values. In the big data era, one would expect new extensions to the existing PGMs to handle the massive amount of data produced these days by computers, sensors and other electronic devices. With hierarchical data - data that is arranged in a treelike structure with several levels - one would expect to see hundreds of thousands or millions of values distributed over even just a small number of levels. When modeling this kind of hierarchical data across large data sets, Bayesian Networks become infeasible for representing the probability distributions. In this paper we introduce an extension to Bayesian Networks to handle massive sets of hierarchical data in a reasonable amount of time and space. The proposed model achieves perfect precision of 1.0 and high recall of 0.93 when it is used as multi-label classifier for the annotation of mass spectrometry data. On another data set of 1.5 billion search logs provided by CareerBuilder.com the model was able to predict latent semantic relationships between search keywords with accuracy up to 0.80.
PGMHD: A Scalable Probabilistic Graphical Model for Massive Hierarchical Data Problems
Aug 19, 2014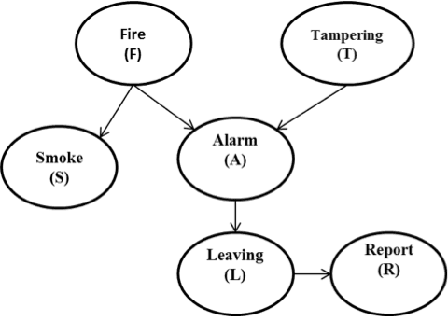
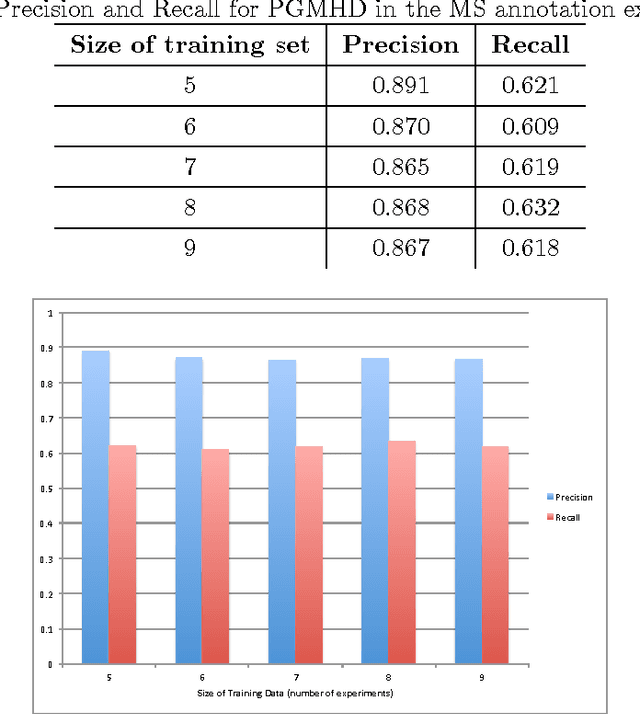
In the big data era, scalability has become a crucial requirement for any useful computational model. Probabilistic graphical models are very useful for mining and discovering data insights, but they are not scalable enough to be suitable for big data problems. Bayesian Networks particularly demonstrate this limitation when their data is represented using few random variables while each random variable has a massive set of values. With hierarchical data - data that is arranged in a treelike structure with several levels - one would expect to see hundreds of thousands or millions of values distributed over even just a small number of levels. When modeling this kind of hierarchical data across large data sets, Bayesian networks become infeasible for representing the probability distributions for the following reasons: i) Each level represents a single random variable with hundreds of thousands of values, ii) The number of levels is usually small, so there are also few random variables, and iii) The structure of the network is predefined since the dependency is modeled top-down from each parent to each of its child nodes, so the network would contain a single linear path for the random variables from each parent to each child node. In this paper we present a scalable probabilistic graphical model to overcome these limitations for massive hierarchical data. We believe the proposed model will lead to an easily-scalable, more readable, and expressive implementation for problems that require probabilistic-based solutions for massive amounts of hierarchical data. We successfully applied this model to solve two different challenging probabilistic-based problems on massive hierarchical data sets for different domains, namely, bioinformatics and latent semantic discovery over search logs.