 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Act Classification in Group Chats with DAG-LSTMs
Aug 02, 2019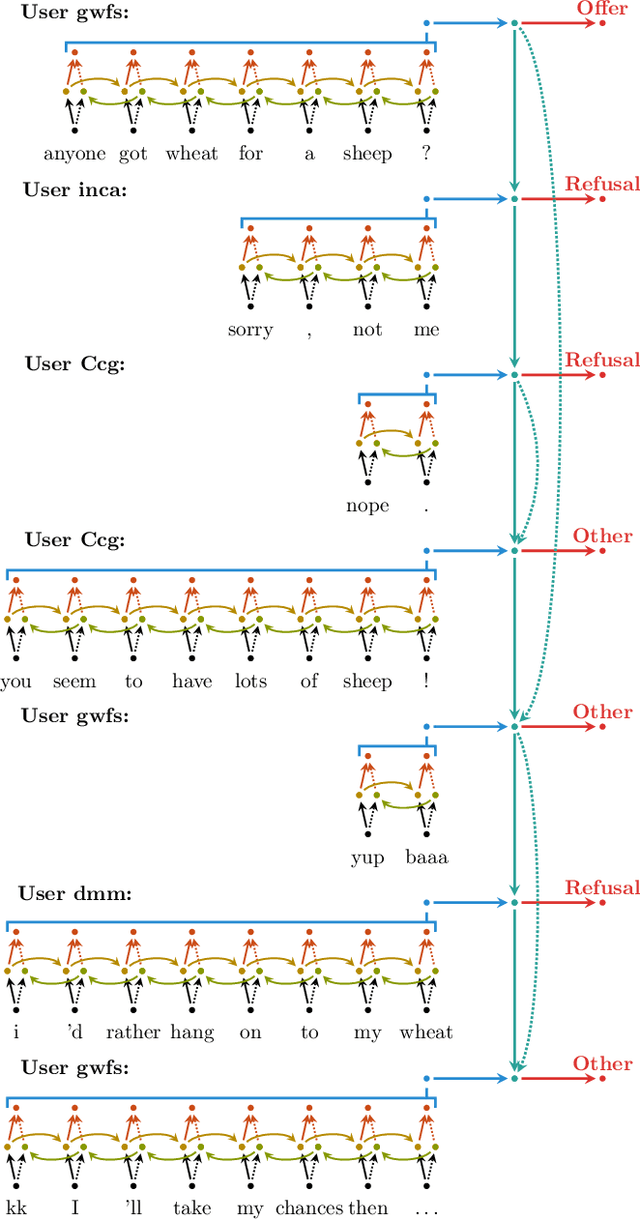
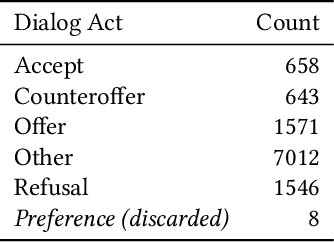

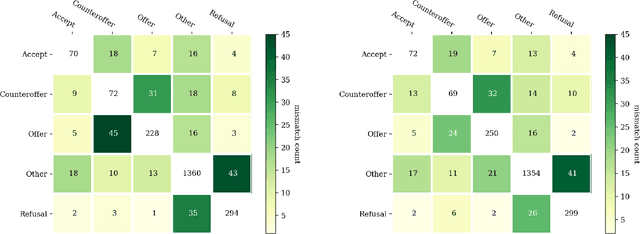
Dialogue act (DA) classification has been studied for the past two decades and has several key applications such as workflow automation and conversation analytics. Researchers have used, to address this problem, various traditional machine learning models, and more recently deep neural network models such as hierarchical convolutional neural networks (CNNs) and long short-term memory (LSTM) networks. In this paper, we introduce a new model architecture, directed-acyclic-graph LSTM (DAG-LSTM) for DA classification. A DAG-LSTM exploits the turn-taking structure naturally present in a multi-party conversation, and encodes this relation in its model structure. Using the STAC corpus, we show that the proposed method performs roughly 0.8% better in accuracy and 1.2% better in macro-F1 score when compared to existing methods. The proposed method is generic and not limited to conversation applications.
Mining Massive Hierarchical Data Using a Scalable Probabilistic Graphical Model
Dec 28, 2015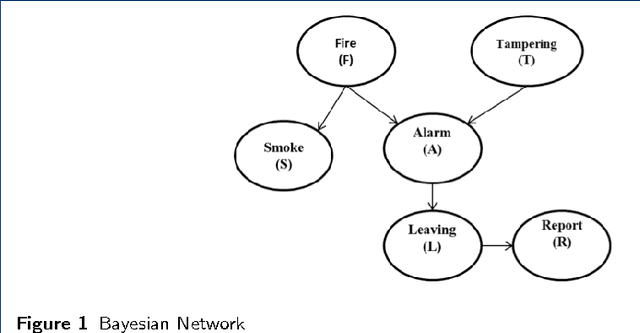
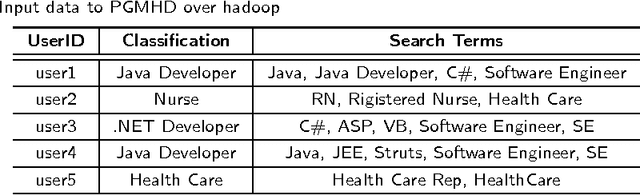

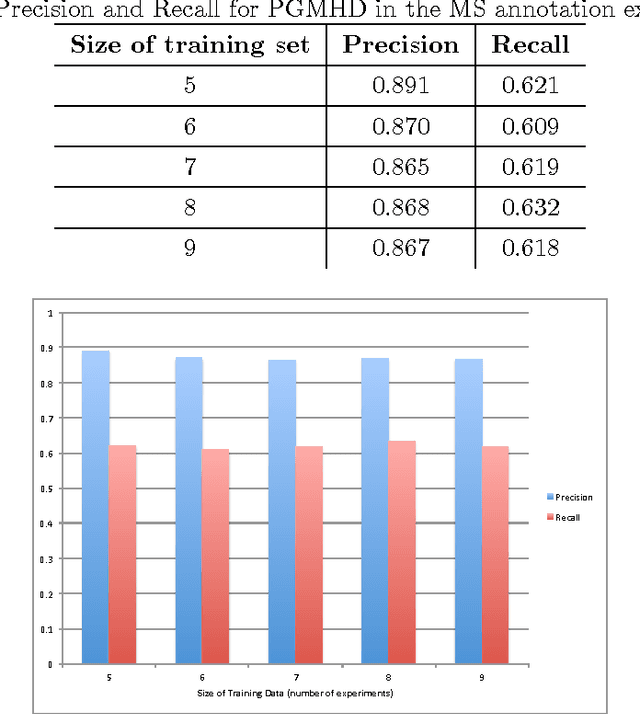
Probabilistic Graphical Models (PGM) are very useful in the fields of machine learning and data mining. The crucial limitation of those models,however, is the scalability. The Bayesian Network, which is one of the most common PGMs used in machine learning and data mining, demonstrates this limitation when the training data consists of random variables, each of them has a large set of possible values. In the big data era, one would expect new extensions to the existing PGMs to handle the massive amount of data produced these days by computers, sensors and other electronic devices. With hierarchical data - data that is arranged in a treelike structure with several levels - one would expect to see hundreds of thousands or millions of values distributed over even just a small number of levels. When modeling this kind of hierarchical data across large data sets, Bayesian Networks become infeasible for representing the probability distributions. In this paper we introduce an extension to Bayesian Networks to handle massive sets of hierarchical data in a reasonable amount of time and space. The proposed model achieves perfect precision of 1.0 and high recall of 0.93 when it is used as multi-label classifier for the annotation of mass spectrometry data. On another data set of 1.5 billion search logs provided by CareerBuilder.com the model was able to predict latent semantic relationships between search keywords with accuracy up to 0.80.
PGMHD: A Scalable Probabilistic Graphical Model for Massive Hierarchical Data Problems
Aug 19, 2014
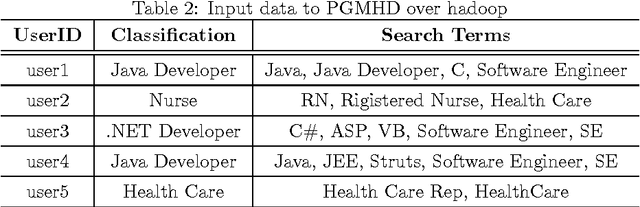
In the big data era, scalability has become a crucial requirement for any useful computational model. Probabilistic graphical models are very useful for mining and discovering data insights, but they are not scalable enough to be suitable for big data problems. Bayesian Networks particularly demonstrate this limitation when their data is represented using few random variables while each random variable has a massive set of values. With hierarchical data - data that is arranged in a treelike structure with several levels - one would expect to see hundreds of thousands or millions of values distributed over even just a small number of levels. When modeling this kind of hierarchical data across large data sets, Bayesian networks become infeasible for representing the probability distributions for the following reasons: i) Each level represents a single random variable with hundreds of thousands of values, ii) The number of levels is usually small, so there are also few random variables, and iii) The structure of the network is predefined since the dependency is modeled top-down from each parent to each of its child nodes, so the network would contain a single linear path for the random variables from each parent to each child node. In this paper we present a scalable probabilistic graphical model to overcome these limitations for massive hierarchical data. We believe the proposed model will lead to an easily-scalable, more readable, and expressive implementation for problems that require probabilistic-based solutions for massive amounts of hierarchical data. We successfully applied this model to solve two different challenging probabilistic-based problems on massive hierarchical data sets for different domains, namely, bioinformatics and latent semantic discovery over search logs.