 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMined Semantic Analysis: A New Concept Space Model for Semantic Representation of Textual Data
Paper and Code

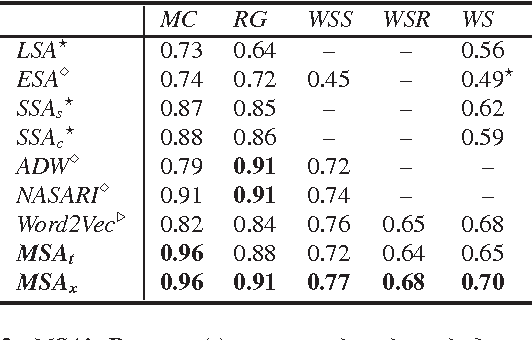

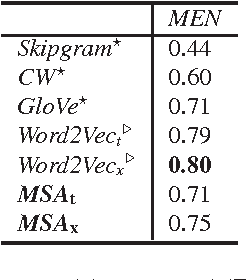
Mined Semantic Analysis (MSA) is a novel concept space model which employs unsupervised learning to generate semantic representations of text. MSA represents textual structures (terms, phrases, documents) as a Bag of Concepts (BoC) where concepts are derived from concept rich encyclopedic corpora. Traditional concept space models exploit only target corpus content to construct the concept space. MSA, alternatively, uncovers implicit relations between concepts by mining for their associations (e.g., mining Wikipedia's "See also" link graph). We evaluate MSA's performance on benchmark datasets for measuring semantic relatedness of words and sentences. Empirical results show competitive performance of MSA compared to prior state-of-the-art methods. Additionally, we introduce the first analytical study to examine statistical significance of results reported by different semantic relatedness methods. Our study shows that, the nuances of results across top performing methods could be statistically insignificant. The study positions MSA as one of state-of-the-art methods for measuring semantic relatedness, besides the inherent interpretability and simplicity of the generated semantic representation.