 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Difficulty of Generated Text for AI-Assisted Language Learning
Jun 04, 2025



Practicing conversations with large language models (LLMs) presents a promising alternative to traditional in-person language learning. However, most LLMs generate text at a near-native level of complexity, making them ill-suited for beginner learners (CEFR: A1-A2). In this paper, we investigate whether controllable generation techniques -- specifically modular methods that do not require model fine-tuning -- can adapt LLM outputs to better support absolute beginners. We evaluate these methods through both automatic metrics and a user study with university-level learners of Japanese. Our findings show that while prompting alone fails to control output difficulty, the use of future discriminators (Yang and Klein, 2021) significantly improves output comprehensibility (from 40.4\% to 84.3\%). We further introduce a novel token-level evaluation metric, Token Miss Rate (TMR), that quantifies the proportion of incomprehensible tokens per utterance and correlates strongly with human judgments. To support future research in AI-assisted language learning, we release our code, models, annotation tools, and dataset.
Domain Gating Ensemble Networks for AI-Generated Text Detection
May 20, 2025As state-of-the-art language models continue to improve, the need for robust detection of machine-generated text becomes increasingly critical. However, current state-of-the-art machine text detectors struggle to adapt to new unseen domains and generative models. In this paper we present DoGEN (Domain Gating Ensemble Networks), a technique that allows detectors to adapt to unseen domains by ensembling a set of domain expert detector models using weights from a domain classifier. We test DoGEN on a wide variety of domains from leading benchmarks and find that it achieves state-of-the-art performance on in-domain detection while outperforming models twice its size on out-of-domain detection. We release our code and trained models to assist in future research in domain-adaptive AI detection.
Group-Adaptive Threshold Optimization for Robust AI-Generated Text Detection
Feb 10, 2025



The advancement of large language models (LLMs) has made it difficult to differentiate human-written text from AI-generated text. Several AI-text detectors have been developed in response, which typically utilize a fixed global threshold (e.g., {\theta} = 0.5) to classify machine-generated text. However, we find that one universal threshold can fail to account for subgroup-specific distributional variations. For example, when using a fixed threshold, detectors make more false positive errors on shorter human-written text than longer, and more positive classifications on neurotic writing styles than open among long text. These discrepancies can lead to misclassification that disproportionately affects certain groups. We address this critical limitation by introducing FairOPT, an algorithm for group-specific threshold optimization in AI-generated content classifiers. Our approach partitions data into subgroups based on attributes (e.g., text length and writing style) and learns decision thresholds for each group, which enables careful balancing of performance and fairness metrics within each subgroup. In experiments with four AI text classifiers on three datasets, FairOPT enhances overall F1 score and decreases balanced error rate (BER) discrepancy across subgroups. Our framework paves the way for more robust and fair classification criteria in AI-generated output detection.
GenAI Content Detection Task 3: Cross-Domain Machine-Generated Text Detection Challenge
Jan 15, 2025



Recently there have been many shared tasks targeting the detection of generated text from Large Language Models (LLMs). However, these shared tasks tend to focus either on cases where text is limited to one particular domain or cases where text can be from many domains, some of which may not be seen during test time. In this shared task, using the newly released RAID benchmark, we aim to answer whether or not models can detect generated text from a large, yet fixed, number of domains and LLMs, all of which are seen during training. Over the course of three months, our task was attempted by 9 teams with 23 detector submissions. We find that multiple participants were able to obtain accuracies of over 99% on machine-generated text from RAID while maintaining a 5% False Positive Rate -- suggesting that detectors are able to robustly detect text from many domains and models simultaneously. We discuss potential interpretations of this result and provide directions for future research.
MiRAGeNews: Multimodal Realistic AI-Generated News Detection
Oct 11, 2024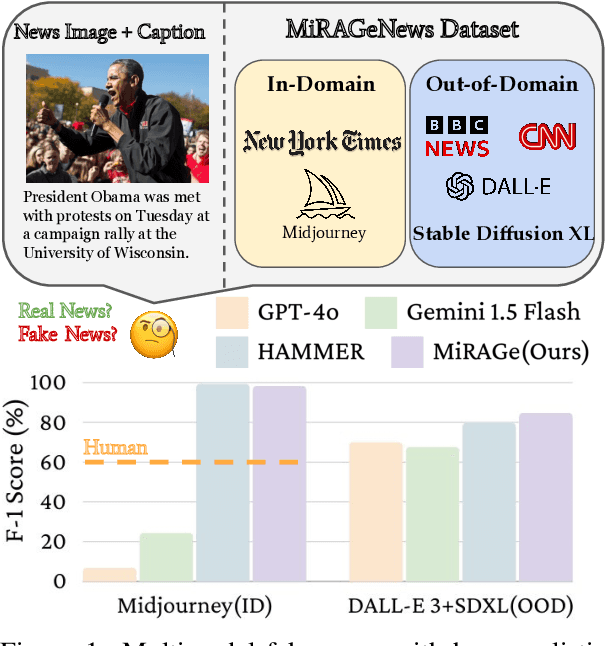
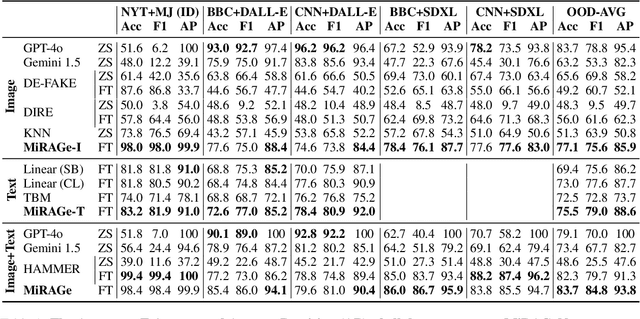
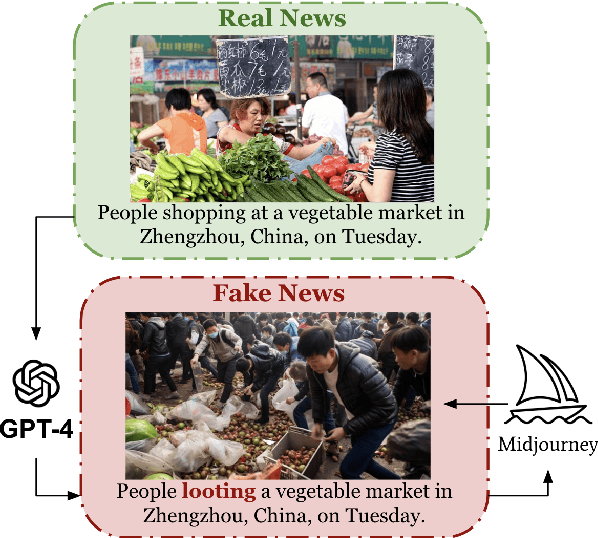
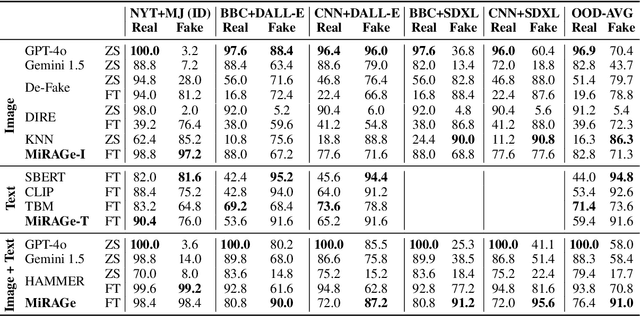
The proliferation of inflammatory or misleading "fake" news content has become increasingly common in recent years. Simultaneously, it has become easier than ever to use AI tools to generate photorealistic images depicting any scene imaginable. Combining these two -- AI-generated fake news content -- is particularly potent and dangerous. To combat the spread of AI-generated fake news, we propose the MiRAGeNews Dataset, a dataset of 12,500 high-quality real and AI-generated image-caption pairs from state-of-the-art generators. We find that our dataset poses a significant challenge to humans (60% F-1) and state-of-the-art multi-modal LLMs (< 24% F-1). Using our dataset we train a multi-modal detector (MiRAGe) that improves by +5.1% F-1 over state-of-the-art baselines on image-caption pairs from out-of-domain image generators and news publishers. We release our code and data to aid future work on detecting AI-generated content.
ReDel: A Toolkit for LLM-Powered Recursive Multi-Agent Systems
Aug 05, 2024
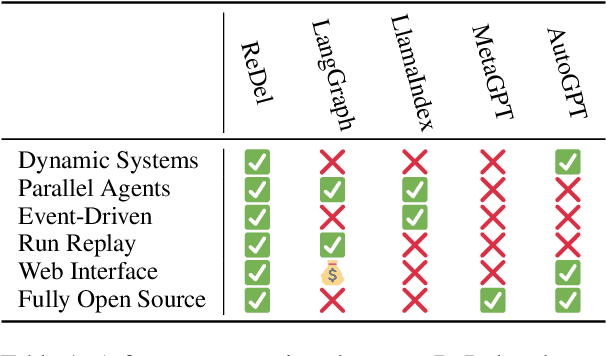

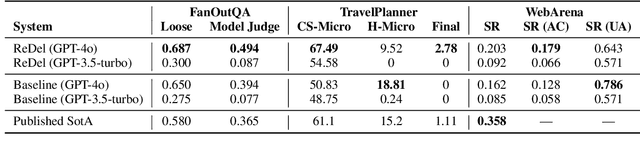
Recently, there has been increasing interest in using Large Language Models (LLMs) to construct complex multi-agent systems to perform tasks such as compiling literature reviews, drafting consumer reports, and planning vacations. Many tools and libraries exist for helping create such systems, however none support recursive multi-agent systems -- where the models themselves flexibly decide when to delegate tasks and how to organize their delegation structure. In this work, we introduce ReDel: a toolkit for recursive multi-agent systems that supports custom tool-use, delegation schemes, event-based logging, and interactive replay in an easy-to-use web interface. We show that, using ReDel, we are able to achieve significant performance gains on agentic benchmarks and easily identify potential areas of improvements through the visualization and debugging tools. Our code, documentation, and PyPI package are open-source and free to use under the MIT license.
RAID: A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors
May 13, 2024
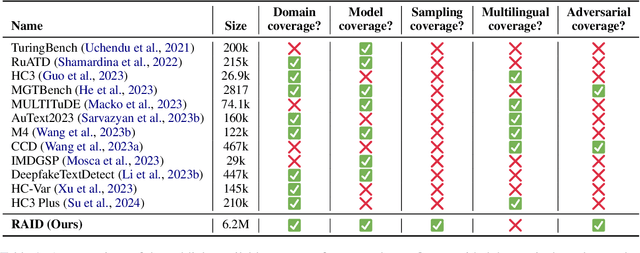
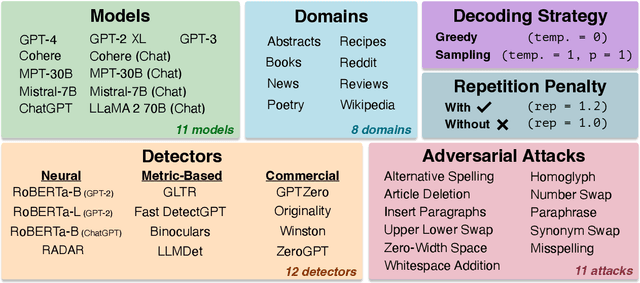

Many commercial and open-source models claim to detect machine-generated text with very high accuracy (99\% or higher). However, very few of these detectors are evaluated on shared benchmark datasets and even when they are, the datasets used for evaluation are insufficiently challenging -- lacking variations in sampling strategy, adversarial attacks, and open-source generative models. In this work we present RAID: the largest and most challenging benchmark dataset for machine-generated text detection. RAID includes over 6 million generations spanning 11 models, 8 domains, 11 adversarial attacks and 4 decoding strategies. Using RAID, we evaluate the out-of-domain and adversarial robustness of 8 open- and 4 closed-source detectors and find that current detectors are easily fooled by adversarial attacks, variations in sampling strategies, repetition penalties, and unseen generative models. We release our dataset and tools to encourage further exploration into detector robustness.
FanOutQA: Multi-Hop, Multi-Document Question Answering for Large Language Models
Feb 21, 2024One type of question that is commonly found in day-to-day scenarios is ``fan-out'' questions, complex multi-hop, multi-document reasoning questions that require finding information about a large number of entities. However, there exist few resources to evaluate this type of question-answering capability among large language models. To evaluate complex reasoning in LLMs more fully, we present FanOutQA, a high-quality dataset of fan-out question-answer pairs and human-annotated decompositions with English Wikipedia as the knowledge base. We formulate three benchmark settings across our dataset and benchmark 7 LLMs, including GPT-4, LLaMA 2, Claude-2.1, and Mixtral-8x7B, finding that contemporary models still have room to improve reasoning over inter-document dependencies in a long context. We provide our dataset and open-source tools to run models to encourage evaluation at https://fanoutqa.com
Interpretable-by-Design Text Classification with Iteratively Generated Concept Bottleneck
Oct 30, 2023
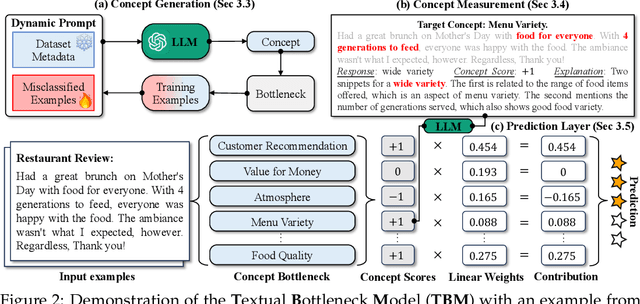

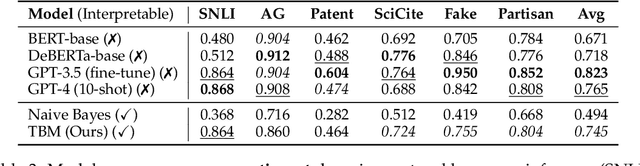
Deep neural networks excel in text classification tasks, yet their application in high-stakes domains is hindered by their lack of interpretability. To address this, we propose Text Bottleneck Models (TBMs), an intrinsically interpretable text classification framework that offers both global and local explanations. Rather than directly predicting the output label, TBMs predict categorical values for a sparse set of salient concepts and use a linear layer over those concept values to produce the final prediction. These concepts can be automatically discovered and measured by a Large Language Model (LLM), without the need for human curation. On 12 diverse datasets, using GPT-4 for both concept generation and measurement, we show that TBMs can rival the performance of established black-box baselines such as GPT-4 fewshot and finetuned DeBERTa, while falling short against finetuned GPT-3.5. Overall, our findings suggest that TBMs are a promising new framework that enhances interpretability, with minimal performance tradeoffs, particularly for general-domain text.
Kani: A Lightweight and Highly Hackable Framework for Building Language Model Applications
Sep 11, 2023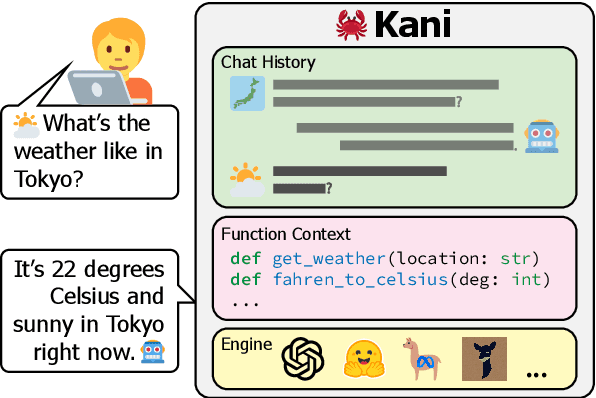

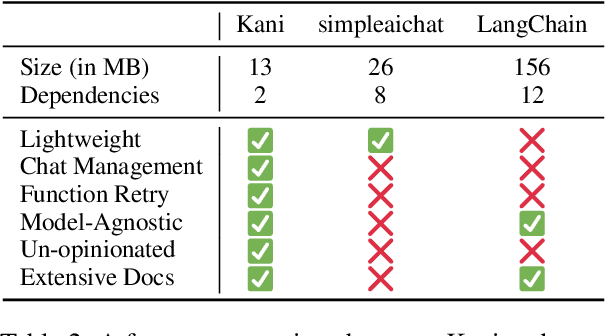
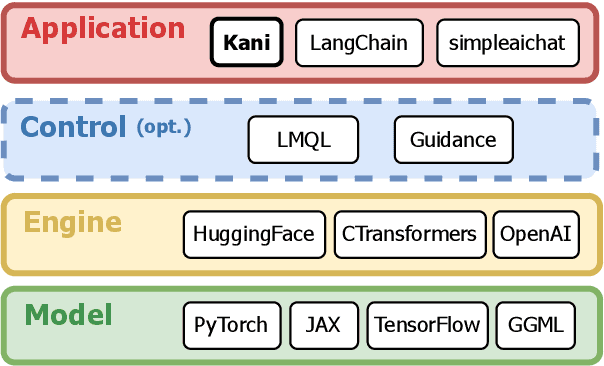
Language model applications are becoming increasingly popular and complex, often including features like tool usage and retrieval augmentation. However, existing frameworks for such applications are often opinionated, deciding for developers how their prompts ought to be formatted and imposing limitations on customizability and reproducibility. To solve this we present Kani: a lightweight, flexible, and model-agnostic open-source framework for building language model applications. Kani helps developers implement a variety of complex features by supporting the core building blocks of chat interaction: model interfacing, chat management, and robust function calling. All Kani core functions are easily overridable and well documented to empower developers to customize functionality for their own needs. Kani thus serves as a useful tool for researchers, hobbyists, and industry professionals alike to accelerate their development while retaining interoperability and fine-grained control.