 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Improved Accuracy in Pelvic Tumor Resections Using a Real-Time Vision-Guided Surgical System
May 29, 2025Pelvic bone tumor resections remain significantly challenging due to complex three-dimensional anatomy and limited surgical visualization. Current navigation systems and patient-specific instruments, while accurate, present limitations including high costs, radiation exposure, workflow disruption, long production time, and lack of reusability. This study evaluates a real-time vision-guided surgical system combined with modular jigs to improve accuracy in pelvic bone tumor resections. A vision-guided surgical system combined with modular cutting jigs and real-time optical tracking was developed and validated. Five female pelvis sawbones were used, with each hemipelvis randomly assigned to either the vision-guided and modular jig system or traditional freehand method. A total of twenty resection planes were analyzed for each method. Accuracy was assessed by measuring distance and angular deviations from the planned resection planes. The vision-guided and modular jig system significantly improved resection accuracy compared to the freehand method, reducing the mean distance deviation from 2.07 $\pm$ 1.71 mm to 1.01 $\pm$ 0.78 mm (p=0.0193). In particular, all specimens resected using the vision-guided system exhibited errors of less than 3 mm. Angular deviations also showed significant improvements with roll angle deviation reduced from 15.36 $\pm$ 17.57$^\circ$ to 4.21 $\pm$ 3.46$^\circ$ (p=0.0275), and pitch angle deviation decreased from 6.17 $\pm$ 4.58$^\circ$ to 1.84 $\pm$ 1.48$^\circ$ (p<0.001). The proposed vision-guided and modular jig system significantly improves the accuracy of pelvic bone tumor resections while maintaining workflow efficiency. This cost-effective solution provides real-time guidance without the need for referencing external monitors, potentially improving surgical outcomes in complex pelvic bone tumor cases.
First Steps Towards Overhearing LLM Agents: A Case Study With Dungeons & Dragons Gameplay
May 28, 2025Much work has been done on conversational LLM agents which directly assist human users with tasks. We present an alternative paradigm for interacting with LLM agents, which we call "overhearing agents". These overhearing agents do not actively participate in conversation -- instead, they "listen in" on human-to-human conversations and perform background tasks or provide suggestions to assist the user. In this work, we explore the overhearing agents paradigm through the lens of Dungeons & Dragons gameplay. We present an in-depth study using large multimodal audio-language models as overhearing agents to assist a Dungeon Master. We perform a human evaluation to examine the helpfulness of such agents and find that some large audio-language models have the emergent ability to perform overhearing agent tasks using implicit audio cues. Finally, we release Python libraries and our project code to support further research into the overhearing agents paradigm at https://github.com/zhudotexe/overhearing_agents.
Addressing the Challenges of Planning Language Generation
May 20, 2025Using LLMs to generate formal planning languages such as PDDL that invokes symbolic solvers to deterministically derive plans has been shown to outperform generating plans directly. While this success has been limited to closed-sourced models or particular LLM pipelines, we design and evaluate 8 different PDDL generation pipelines with open-source models under 50 billion parameters previously shown to be incapable of this task. We find that intuitive approaches such as using a high-resource language wrapper or constrained decoding with grammar decrease performance, yet inference-time scaling approaches such as revision with feedback from the solver and plan validator more than double the performance.
GenAI Content Detection Task 3: Cross-Domain Machine-Generated Text Detection Challenge
Jan 15, 2025



Recently there have been many shared tasks targeting the detection of generated text from Large Language Models (LLMs). However, these shared tasks tend to focus either on cases where text is limited to one particular domain or cases where text can be from many domains, some of which may not be seen during test time. In this shared task, using the newly released RAID benchmark, we aim to answer whether or not models can detect generated text from a large, yet fixed, number of domains and LLMs, all of which are seen during training. Over the course of three months, our task was attempted by 9 teams with 23 detector submissions. We find that multiple participants were able to obtain accuracies of over 99% on machine-generated text from RAID while maintaining a 5% False Positive Rate -- suggesting that detectors are able to robustly detect text from many domains and models simultaneously. We discuss potential interpretations of this result and provide directions for future research.
You Have Thirteen Hours in Which to Solve the Labyrinth: Enhancing AI Game Masters with Function Calling
Sep 11, 2024

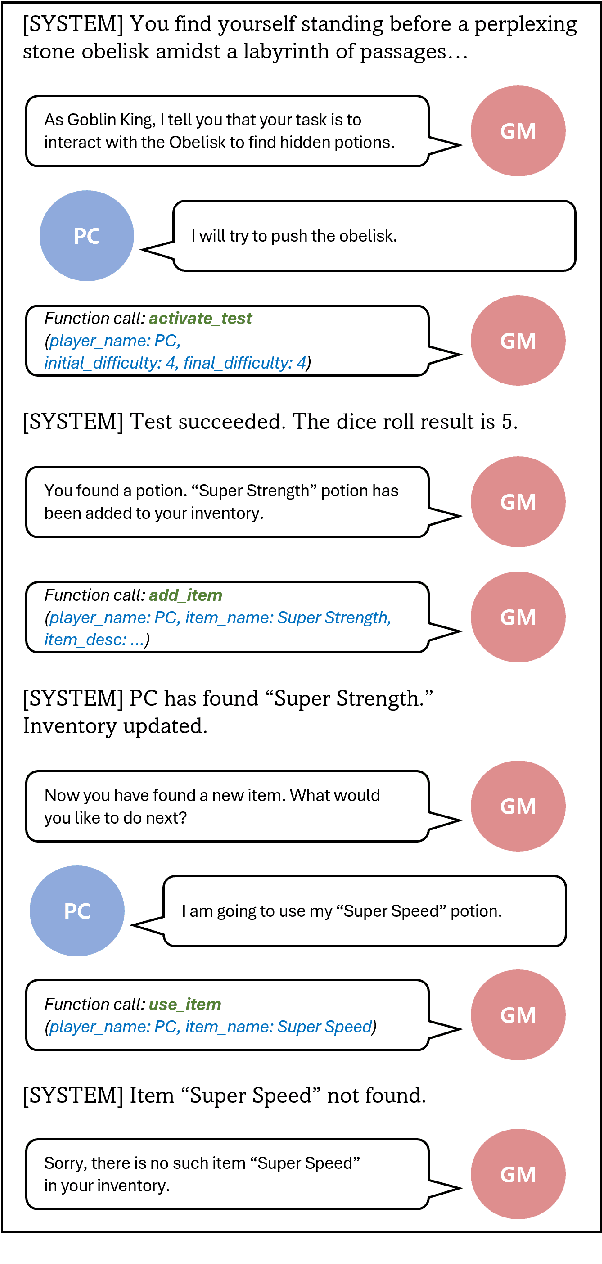
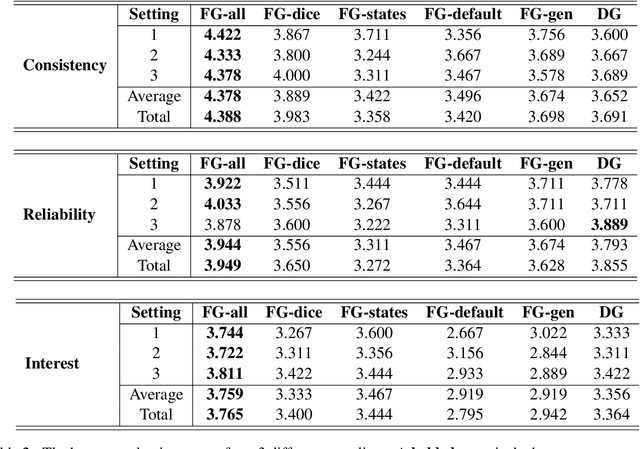
Developing a consistent and reliable AI game master for text-based games is a challenging task due to the limitations of large language models (LLMs) and the complexity of the game master's role. This paper presents a novel approach to enhance AI game masters by leveraging function calling in the context of the table-top role-playing game "Jim Henson's Labyrinth: The Adventure Game." Our methodology involves integrating game-specific controls through functions, which we show improves the narrative quality and state update consistency of the AI game master. The experimental results, based on human evaluations and unit tests, demonstrate the effectiveness of our approach in enhancing gameplay experience and maintaining coherence with the game state. This work contributes to the advancement of game AI and interactive storytelling, offering insights into the design of more engaging and consistent AI-driven game masters.
ReDel: A Toolkit for LLM-Powered Recursive Multi-Agent Systems
Aug 05, 2024
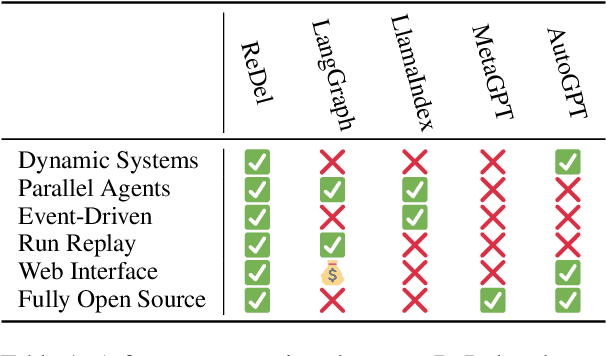

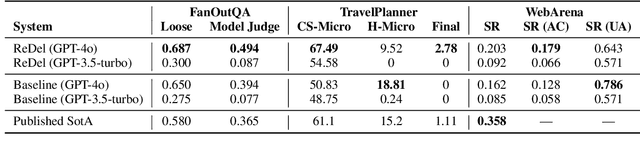
Recently, there has been increasing interest in using Large Language Models (LLMs) to construct complex multi-agent systems to perform tasks such as compiling literature reviews, drafting consumer reports, and planning vacations. Many tools and libraries exist for helping create such systems, however none support recursive multi-agent systems -- where the models themselves flexibly decide when to delegate tasks and how to organize their delegation structure. In this work, we introduce ReDel: a toolkit for recursive multi-agent systems that supports custom tool-use, delegation schemes, event-based logging, and interactive replay in an easy-to-use web interface. We show that, using ReDel, we are able to achieve significant performance gains on agentic benchmarks and easily identify potential areas of improvements through the visualization and debugging tools. Our code, documentation, and PyPI package are open-source and free to use under the MIT license.
RAID: A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors
May 13, 2024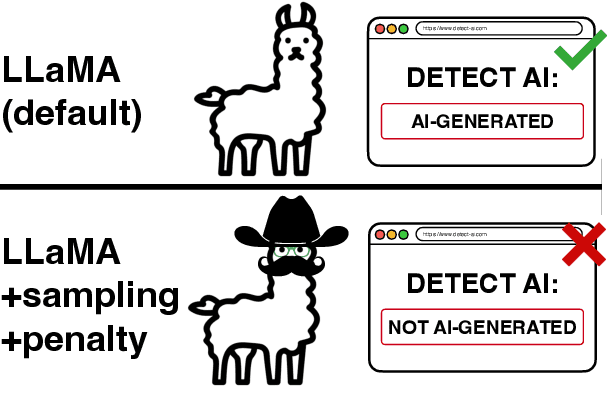
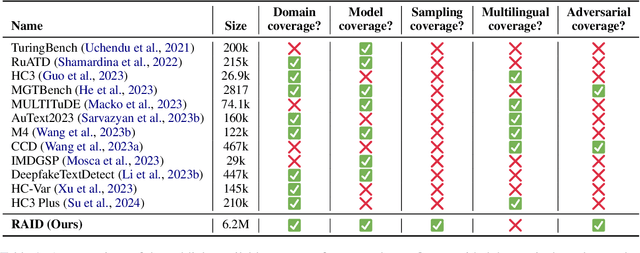
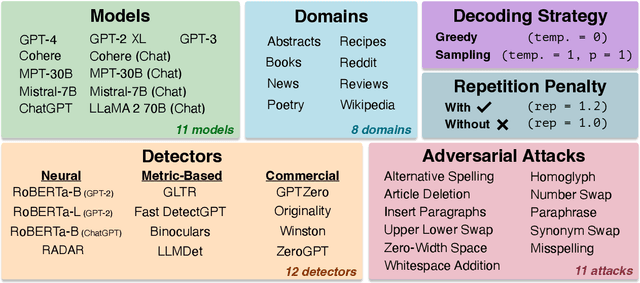

Many commercial and open-source models claim to detect machine-generated text with very high accuracy (99\% or higher). However, very few of these detectors are evaluated on shared benchmark datasets and even when they are, the datasets used for evaluation are insufficiently challenging -- lacking variations in sampling strategy, adversarial attacks, and open-source generative models. In this work we present RAID: the largest and most challenging benchmark dataset for machine-generated text detection. RAID includes over 6 million generations spanning 11 models, 8 domains, 11 adversarial attacks and 4 decoding strategies. Using RAID, we evaluate the out-of-domain and adversarial robustness of 8 open- and 4 closed-source detectors and find that current detectors are easily fooled by adversarial attacks, variations in sampling strategies, repetition penalties, and unseen generative models. We release our dataset and tools to encourage further exploration into detector robustness.
FanOutQA: Multi-Hop, Multi-Document Question Answering for Large Language Models
Feb 21, 2024One type of question that is commonly found in day-to-day scenarios is ``fan-out'' questions, complex multi-hop, multi-document reasoning questions that require finding information about a large number of entities. However, there exist few resources to evaluate this type of question-answering capability among large language models. To evaluate complex reasoning in LLMs more fully, we present FanOutQA, a high-quality dataset of fan-out question-answer pairs and human-annotated decompositions with English Wikipedia as the knowledge base. We formulate three benchmark settings across our dataset and benchmark 7 LLMs, including GPT-4, LLaMA 2, Claude-2.1, and Mixtral-8x7B, finding that contemporary models still have room to improve reasoning over inter-document dependencies in a long context. We provide our dataset and open-source tools to run models to encourage evaluation at https://fanoutqa.com
Kani: A Lightweight and Highly Hackable Framework for Building Language Model Applications
Sep 11, 2023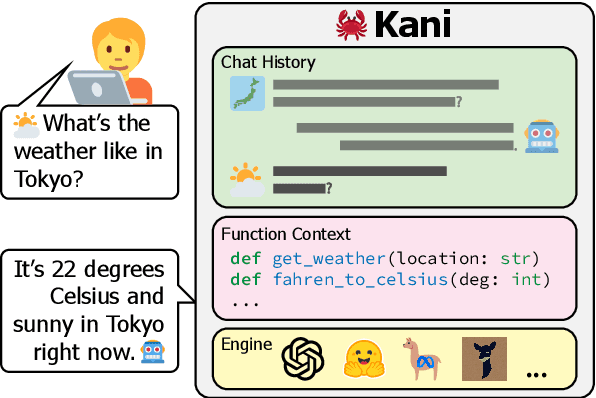

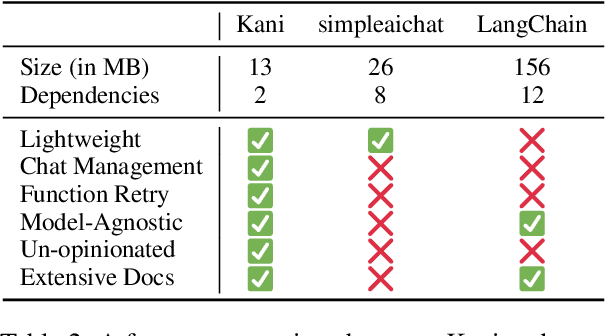
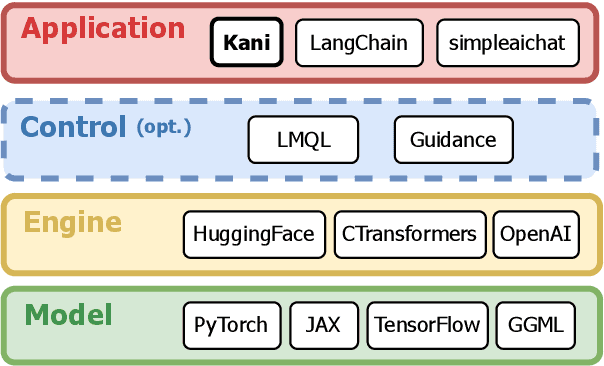
Language model applications are becoming increasingly popular and complex, often including features like tool usage and retrieval augmentation. However, existing frameworks for such applications are often opinionated, deciding for developers how their prompts ought to be formatted and imposing limitations on customizability and reproducibility. To solve this we present Kani: a lightweight, flexible, and model-agnostic open-source framework for building language model applications. Kani helps developers implement a variety of complex features by supporting the core building blocks of chat interaction: model interfacing, chat management, and robust function calling. All Kani core functions are easily overridable and well documented to empower developers to customize functionality for their own needs. Kani thus serves as a useful tool for researchers, hobbyists, and industry professionals alike to accelerate their development while retaining interoperability and fine-grained control.