 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextGuider: Training-Free Guidance for Text Rendering via Attention Alignment
Dec 13, 2025
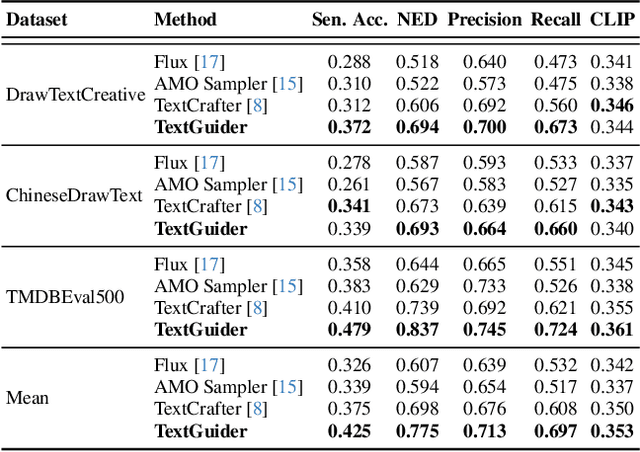
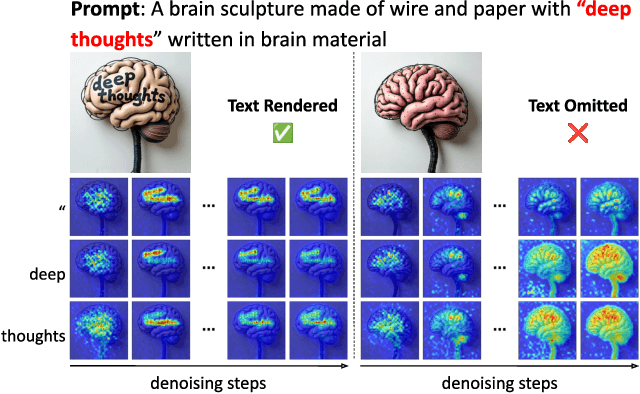
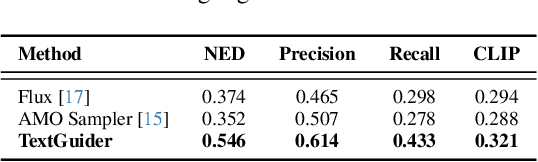
Despite recent advances, diffusion-based text-to-image models still struggle with accurate text rendering. Several studies have proposed fine-tuning or training-free refinement methods for accurate text rendering. However, the critical issue of text omission, where the desired text is partially or entirely missing, remains largely overlooked. In this work, we propose TextGuider, a novel training-free method that encourages accurate and complete text appearance by aligning textual content tokens and text regions in the image. Specifically, we analyze attention patterns in Multi-Modal Diffusion Transformer(MM-DiT) models, particularly for text-related tokens intended to be rendered in the image. Leveraging this observation, we apply latent guidance during the early stage of denoising steps based on two loss functions that we introduce. Our method achieves state-of-the-art performance in test-time text rendering, with significant gains in recall and strong results in OCR accuracy and CLIP score.
DefectFill: Realistic Defect Generation with Inpainting Diffusion Model for Visual Inspection
Mar 18, 2025Developing effective visual inspection models remains challenging due to the scarcity of defect data. While image generation models have been used to synthesize defect images, producing highly realistic defects remains difficult. We propose DefectFill, a novel method for realistic defect generation that requires only a few reference defect images. It leverages a fine-tuned inpainting diffusion model, optimized with our custom loss functions incorporating defect, object, and attention terms. It enables precise capture of detailed, localized defect features and their seamless integration into defect-free objects. Additionally, our Low-Fidelity Selection method further enhances the defect sample quality. Experiments show that DefectFill generates high-quality defect images, enabling visual inspection models to achieve state-of-the-art performance on the MVTec AD dataset.
SplitQuantV2: Enhancing Low-Bit Quantization of LLMs Without GPUs
Mar 07, 2025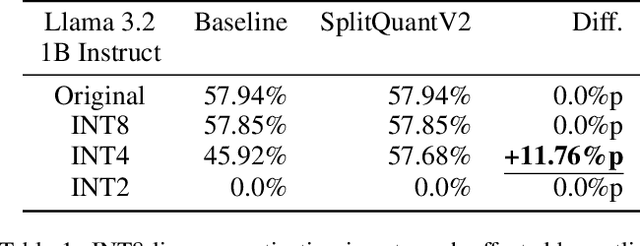

The quantization of large language models (LLMs) is crucial for deploying them on devices with limited computational resources. While advanced quantization algorithms offer improved performance compared to the basic linear quantization, they typically require high-end graphics processing units (GPUs), are often restricted to specific deep neural network (DNN) frameworks, and require calibration datasets. This limitation poses challenges for using such algorithms on various neural processing units (NPUs) and edge AI devices, which have diverse model formats and frameworks. In this paper, we show SplitQuantV2, an innovative algorithm designed to enhance low-bit linear quantization of LLMs, can achieve results comparable to those of advanced algorithms. SplitQuantV2 preprocesses models by splitting linear and convolution layers into functionally equivalent, quantization-friendly structures. The algorithm's platform-agnostic, concise, and efficient nature allows for implementation without the need for GPUs. Our evaluation on the Llama 3.2 1B Instruct model using the AI2's Reasoning Challenge (ARC) dataset demonstrates that SplitQuantV2 improves the accuracy of the INT4 quantization model by 11.76%p, matching the performance of the original floating-point model. Remarkably, SplitQuantV2 took only 2 minutes 6 seconds to preprocess the 1B model and perform linear INT4 quantization using only an Apple M4 CPU. SplitQuantV2 provides a practical solution for low-bit quantization on LLMs, especially when complex, computation-intensive algorithms are inaccessible due to hardware limitations or framework incompatibilities.
You Have Thirteen Hours in Which to Solve the Labyrinth: Enhancing AI Game Masters with Function Calling
Sep 11, 2024

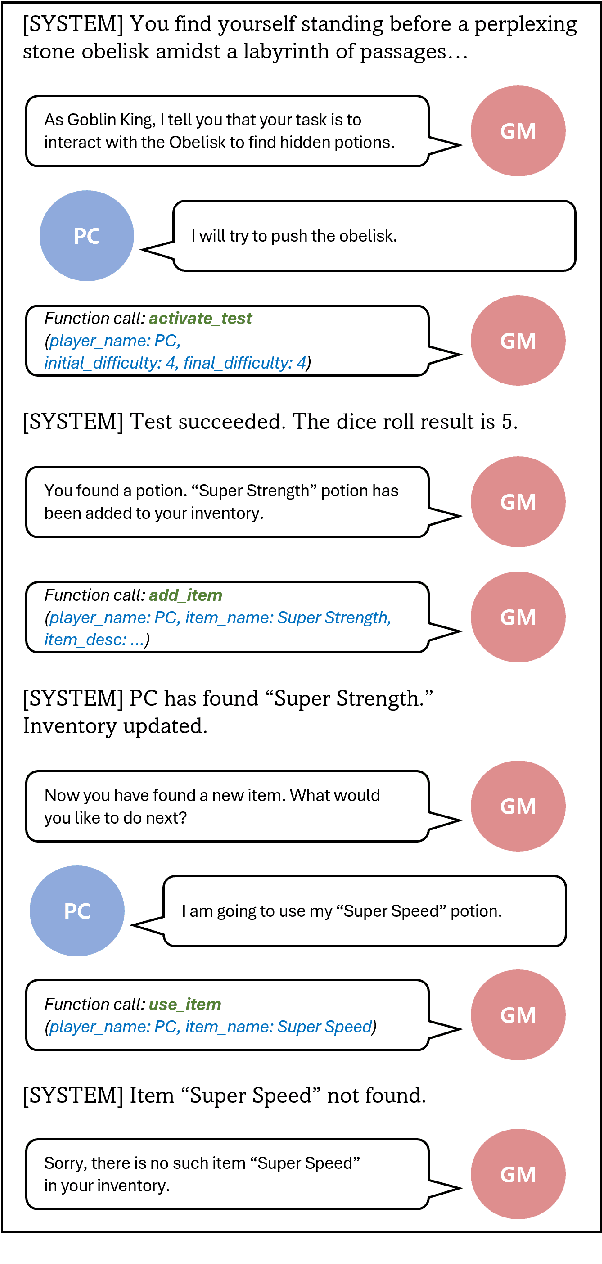
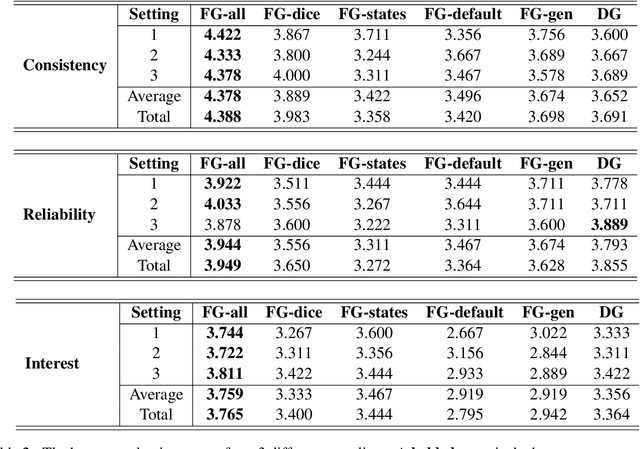
Developing a consistent and reliable AI game master for text-based games is a challenging task due to the limitations of large language models (LLMs) and the complexity of the game master's role. This paper presents a novel approach to enhance AI game masters by leveraging function calling in the context of the table-top role-playing game "Jim Henson's Labyrinth: The Adventure Game." Our methodology involves integrating game-specific controls through functions, which we show improves the narrative quality and state update consistency of the AI game master. The experimental results, based on human evaluations and unit tests, demonstrate the effectiveness of our approach in enhancing gameplay experience and maintaining coherence with the game state. This work contributes to the advancement of game AI and interactive storytelling, offering insights into the design of more engaging and consistent AI-driven game masters.
PocketNN: Integer-only Training and Inference of Neural Networks via Direct Feedback Alignment and Pocket Activations in Pure C++
Jan 08, 2022
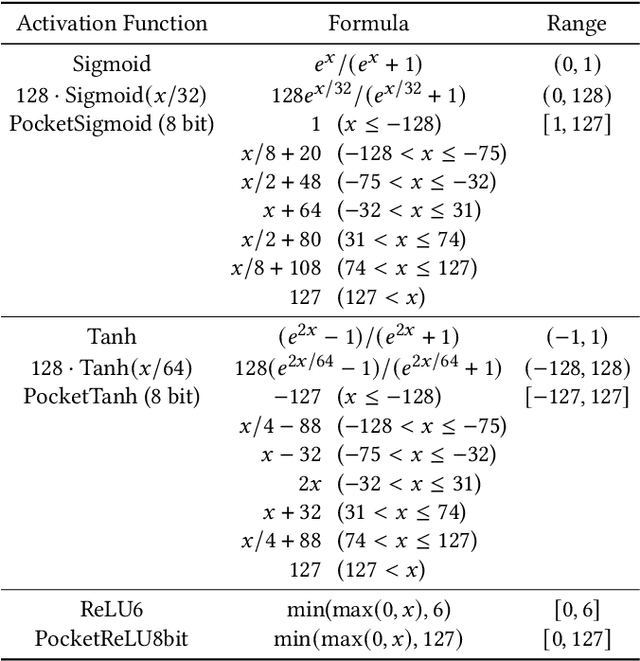
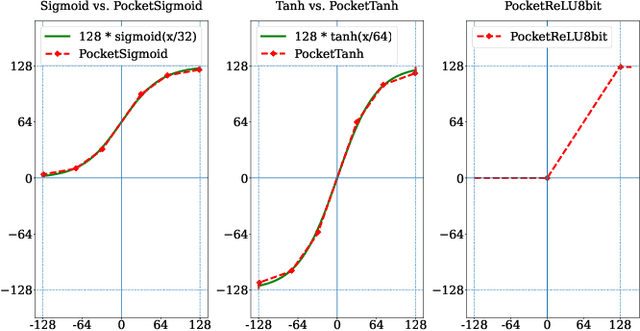
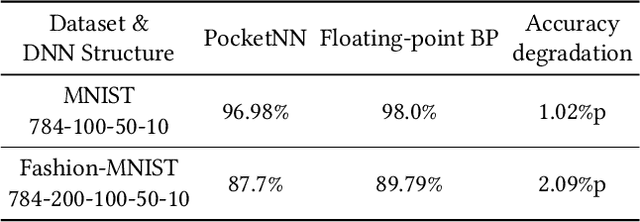
Standard deep learning algorithms are implemented using floating-point real numbers. This presents an obstacle for implementing them on low-end devices which may not have dedicated floating-point units (FPUs). As a result, researchers in TinyML have considered machine learning algorithms that can train and run a deep neural network (DNN) on a low-end device using integer operations only. In this paper we propose PocketNN, a light and self-contained proof-of-concept framework in pure C++ for the training and inference of DNNs using only integers. Unlike other approaches, PocketNN directly operates on integers without requiring any explicit quantization algorithms or customized fixed-point formats. This was made possible by pocket activations, which are a family of activation functions devised for integer-only DNNs, and an emerging DNN training algorithm called direct feedback alignment (DFA). Unlike the standard backpropagation (BP), DFA trains each layer independently, thus avoiding integer overflow which is a key problem when using BP with integer-only operations. We used PocketNN to train some DNNs on two well-known datasets, MNIST and Fashion-MNIST. Our experiments show that the DNNs trained with our PocketNN achieved 96.98% and 87.7% accuracies on MNIST and Fashion-MNIST datasets, respectively. The accuracies are very close to the equivalent DNNs trained using BP with floating-point real number operations, such that accuracy degradations were just 1.02%p and 2.09%p, respectively. Finally, our PocketNN has high compatibility and portability for low-end devices as it is open source and implemented in pure C++ without any dependencies.