 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable-by-Design Text Classification with Iteratively Generated Concept Bottleneck
Paper and Code

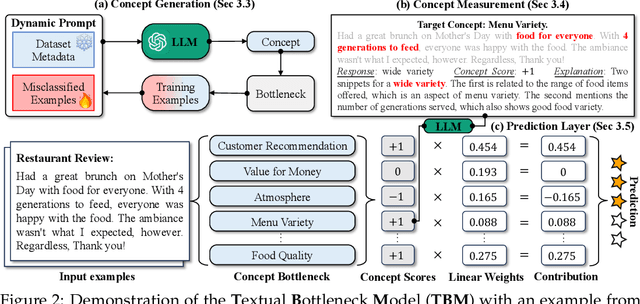

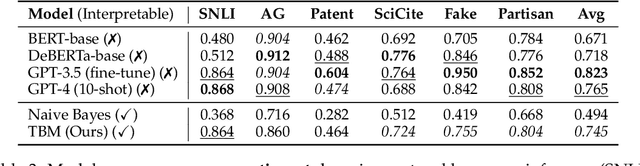
Deep neural networks excel in text classification tasks, yet their application in high-stakes domains is hindered by their lack of interpretability. To address this, we propose Text Bottleneck Models (TBMs), an intrinsically interpretable text classification framework that offers both global and local explanations. Rather than directly predicting the output label, TBMs predict categorical values for a sparse set of salient concepts and use a linear layer over those concept values to produce the final prediction. These concepts can be automatically discovered and measured by a Large Language Model (LLM), without the need for human curation. On 12 diverse datasets, using GPT-4 for both concept generation and measurement, we show that TBMs can rival the performance of established black-box baselines such as GPT-4 fewshot and finetuned DeBERTa, while falling short against finetuned GPT-3.5. Overall, our findings suggest that TBMs are a promising new framework that enhances interpretability, with minimal performance tradeoffs, particularly for general-domain text.