 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCantoASR: Prosody-Aware ASR-LALM Collaboration for Low-Resource Cantonese
Nov 06, 2025Automatic speech recognition (ASR) is critical for language accessibility, yet low-resource Cantonese remains challenging due to limited annotated data, six lexical tones, tone sandhi, and accent variation. Existing ASR models, such as Whisper, often suffer from high word error rates. Large audio-language models (LALMs), in contrast, can leverage broader contextual reasoning but still require explicit tonal and prosodic acoustic cues. We introduce CantoASR, a collaborative ASR-LALM error correction framework that integrates forced alignment for acoustic feature extraction, a LoRA-finetuned Whisper for improved tone discrimination, and an instruction-tuned Qwen-Audio for prosody-aware correction. Evaluations on spontaneous Cantonese data show substantial CER gains over Whisper-Large-V3. These findings suggest that integrating acoustic cues with LALM reasoning provides a scalable strategy for low-resource tonal and dialectal ASR.
Veri-R1: Toward Precise and Faithful Claim Verification via Online Reinforcement Learning
Oct 02, 2025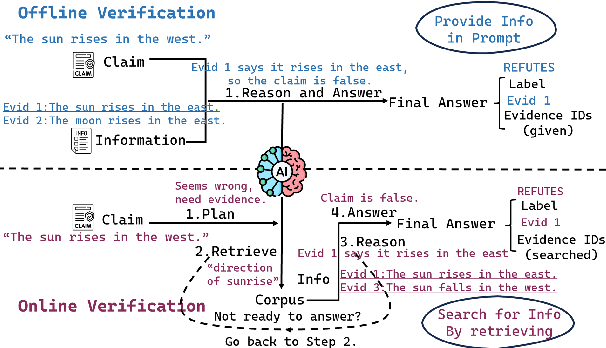
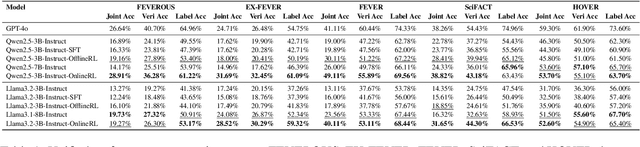
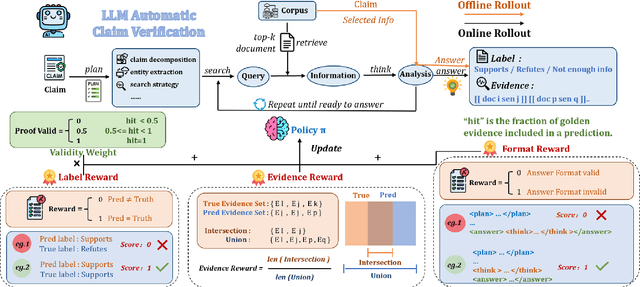

Claim verification with large language models (LLMs) has recently attracted considerable attention, owing to their superior reasoning capabilities and transparent verification pathways compared to traditional answer-only judgments. Online claim verification requires iterative evidence retrieval and reasoning, yet existing approaches mainly rely on prompt engineering or predesigned reasoning workflows without offering a unified training paradigm to improve necessary skills. Therefore, we introduce Veri-R1, an online reinforcement learning (RL) framework that enables an LLM to interact with a search engine and to receive reward signals that explicitly shape its planning, retrieval, and reasoning behaviors. The dynamic interaction between models and retrieval systems more accurately reflects real-world verification scenarios and fosters comprehensive verification skills. Empirical results show that Veri-R1 improves joint accuracy by up to 30% and doubles evidence score, often surpassing larger-scale counterparts. Ablation studies further reveal the impact of reward components and the link between output logits and label accuracy. Our results highlight the effectiveness of online RL for precise and faithful claim verification and provide a foundation for future research. We release our code to support community progress in LLM empowered claim verification.
MMBoundary: Advancing MLLM Knowledge Boundary Awareness through Reasoning Step Confidence Calibration
May 29, 2025In recent years, multimodal large language models (MLLMs) have made significant progress but continue to face inherent challenges in multimodal reasoning, which requires multi-level (e.g., perception, reasoning) and multi-granular (e.g., multi-step reasoning chain) advanced inferencing. Prior work on estimating model confidence tends to focus on the overall response for training and calibration, but fails to assess confidence in each reasoning step, leading to undesirable hallucination snowballing. In this work, we present MMBoundary, a novel framework that advances the knowledge boundary awareness of MLLMs through reasoning step confidence calibration. To achieve this, we propose to incorporate complementary textual and cross-modal self-rewarding signals to estimate confidence at each step of the MLLM reasoning process. In addition to supervised fine-tuning MLLM on this set of self-rewarded confidence estimation signal for initial confidence expression warm-up, we introduce a reinforcement learning stage with multiple reward functions for further aligning model knowledge and calibrating confidence at each reasoning step, enhancing reasoning chain self-correction. Empirical results show that MMBoundary significantly outperforms existing methods across diverse domain datasets and metrics, achieving an average of 7.5% reduction in multimodal confidence calibration errors and up to 8.3% improvement in task performance.
Let's Reason Formally: Natural-Formal Hybrid Reasoning Enhances LLM's Math Capability
May 29, 2025Enhancing the mathematical reasoning capabilities of LLMs has garnered significant attention in both the mathematical and computer science communities. Recent works have made substantial progress in both Natural Language (NL) reasoning and Formal Language (FL) reasoning by leveraging the potential of pure Reinforcement Learning (RL) methods on base models. However, RL approaches struggle to impart new capabilities not presented in the base model, highlighting the need to integrate more knowledge like FL into NL math reasoning effectively. Yet, this integration is challenging due to inherent disparities in problem structure and reasoning format between NL and FL. To address these challenges, we introduce **NL-FL HybridReasoning**, an end-to-end framework designed to incorporate the FL expert into NL math problem-solving. To bridge the NL and FL input format gap, we propose the *NL-FL Problem Alignment* method, which reformulates the Question-Answering (QA) problems in NL as existence theorems in FL. Subsequently, the *Mixed Problem Input* technique we provide enables the FL reasoner to handle both QA and existence problems concurrently. Lastly, we mitigate the NL and FL output format gap in reasoning through an LLM-based *Answer Extraction* mechanism. Comprehensive experiments demonstrate that the **HybridReasoning** framework achieves **89.80%** and **84.34%** accuracy rates on the MATH-500 and the AMC benchmarks, surpassing the NL baseline by 4.60% and 4.82%, respectively. Notably, some problems resolved by our framework remain unsolved by the NL baseline model even under a larger number of trials.
RePPL: Recalibrating Perplexity by Uncertainty in Semantic Propagation and Language Generation for Explainable QA Hallucination Detection
May 21, 2025Large Language Models (LLMs) have become powerful, but hallucinations remain a vital obstacle to their trustworthy use. While previous works improved the capability of hallucination detection by measuring uncertainty, they all lack the ability to explain the provenance behind why hallucinations occur, i.e., which part of the inputs tends to trigger hallucinations. Recent works on the prompt attack indicate that uncertainty exists in semantic propagation, where attention mechanisms gradually fuse local token information into high-level semantics across layers. Meanwhile, uncertainty also emerges in language generation, due to its probability-based selection of high-level semantics for sampled generations. Based on that, we propose RePPL to recalibrate uncertainty measurement by these two aspects, which dispatches explainable uncertainty scores to each token and aggregates in Perplexity-style Log-Average form as total score. Experiments show that our method achieves the best comprehensive detection performance across various QA datasets on advanced models (average AUC of 0.833), and our method is capable of producing token-level uncertainty scores as explanations for the hallucination. Leveraging these scores, we preliminarily find the chaotic pattern of hallucination and showcase its promising usage.
Alice: Proactive Learning with Teacher's Demonstrations for Weak-to-Strong Generalization
Apr 09, 2025The growing capabilities of large language models (LLMs) present a key challenge of maintaining effective human oversight. Weak-to-strong generalization (W2SG) offers a promising framework for supervising increasingly capable LLMs using weaker ones. Traditional W2SG methods rely on passive learning, where a weak teacher provides noisy demonstrations to train a strong student. This hinders students from employing their knowledge during training and reaching their full potential. In this work, we introduce Alice (pro{A}ctive {l}earning w{i}th tea{c}her's D{e}monstrations), a framework that leverages complementary knowledge between teacher and student to enhance the learning process.We probe the knowledge base of the teacher model by eliciting their uncertainty, and then use these insights together with teachers' responses as demonstrations to guide student models in self-generating improved responses for supervision. In addition, for situations with significant capability gaps between teacher and student models, we introduce cascade Alice, which employs a hierarchical training approach where weak teachers initially supervise intermediate models, who then guide stronger models in sequence. Experimental results demonstrate that our method significantly enhances the W2SG performance, yielding substantial improvements in three key tasks compared to the original W2SG: knowledge-based reasoning (+4.0%), mathematical reasoning (+22.62%), and logical reasoning (+12.11%). This highlights the effectiveness of our new W2SG paradigm that enables more robust knowledge transfer and supervision outcome.
VLM$^2$-Bench: A Closer Look at How Well VLMs Implicitly Link Explicit Matching Visual Cues
Feb 17, 2025



Visually linking matching cues is a crucial ability in daily life, such as identifying the same person in multiple photos based on their cues, even without knowing who they are. Despite the extensive knowledge that vision-language models (VLMs) possess, it remains largely unexplored whether they are capable of performing this fundamental task. To address this, we introduce VLM$^2$-Bench, a benchmark designed to assess whether VLMs can Visually Link Matching cues, with 9 subtasks and over 3,000 test cases. Comprehensive evaluation across eight open-source VLMs and GPT-4o, along with further analysis of various language-side and vision-side prompting methods, leads to a total of eight key findings. We identify critical challenges in models' ability to link visual cues, highlighting a significant performance gap where even GPT-4o lags 34.80% behind humans. Based on these insights, we advocate for (i) enhancing core visual capabilities to improve adaptability and reduce reliance on prior knowledge, (ii) establishing clearer principles for integrating language-based reasoning in vision-centric tasks to prevent unnecessary biases, and (iii) shifting vision-text training paradigms toward fostering models' ability to independently structure and infer relationships among visual cues.
Group-Adaptive Threshold Optimization for Robust AI-Generated Text Detection
Feb 10, 2025



The advancement of large language models (LLMs) has made it difficult to differentiate human-written text from AI-generated text. Several AI-text detectors have been developed in response, which typically utilize a fixed global threshold (e.g., {\theta} = 0.5) to classify machine-generated text. However, we find that one universal threshold can fail to account for subgroup-specific distributional variations. For example, when using a fixed threshold, detectors make more false positive errors on shorter human-written text than longer, and more positive classifications on neurotic writing styles than open among long text. These discrepancies can lead to misclassification that disproportionately affects certain groups. We address this critical limitation by introducing FairOPT, an algorithm for group-specific threshold optimization in AI-generated content classifiers. Our approach partitions data into subgroups based on attributes (e.g., text length and writing style) and learns decision thresholds for each group, which enables careful balancing of performance and fairness metrics within each subgroup. In experiments with four AI text classifiers on three datasets, FairOPT enhances overall F1 score and decreases balanced error rate (BER) discrepancy across subgroups. Our framework paves the way for more robust and fair classification criteria in AI-generated output detection.